在语言学习中,一个常见的关键问题是如何对学习者表现评分,这种评分一般可分为客观与主观评价。客观评价一般以客观题的形式测试,比如填空、选择等,学习者答案正确即为合格。主观评价则通常以问话形式测试,由学习者做答,再由评判老师对学生的回答给出主观评测,比如作文打分、口语评测等。
主观评价常常耗时耗力,成本较高。另外,由于评测设备、心理状态、个人偏好的差异,不易保持评价结果的一致性。为了解决这些问题,主观评测已成为计算机辅助语言学习 Computer-Assisted Language Learning (CALL) 的重要课题之一。
我们将介绍微软小英团队利用序数回归 Ordinal Regression (OR) 方法处理 CALL 中主观评价问题的创新,以及其在发音、语音流畅度及英文写作三种自然语音/语言的应用,以及相关方法的总结与展望。
序数回归与主观评测
在主观评测的问题中,用不同的分数表示不同的等级,比如在5分制平均意见分 Mean Opinion Score (MOS) 中,常以1分到5分分别代表很差,差,一般,好,很好。传统方法常用分类或回归的方法解决,训练多类型的分类器或回归得到由输入特征与分数间的映射。
然而,这类问题中样本之间相对次序的信息未能全盘解读。因为不同的分数除其绝对分数外,其物理意义也代表了样本在整个序列中的相对位置,比如一个3分的样本,它所呈现的信息代表着一个比4分的样本差比2分样本好的样本,同时3分与2分的样本的主观差异与2分与1分之间的主观差异,不尽相同。传统的分类器只将每个分数视为一类,并不能完善地利用主观评分中相对次序的特质。
不同分数样本间的差异并非非等距,比如作文打分,1-3分的评价常针对拼写和语法错误,而3-5分的差异着重在更高一级的写作技巧,例如论述、展开与切题等等。对于等分间距的回归,训练中受到数据集大小与数据分布的影响,会有模型对于训练数据过拟合的问题。
考虑到分数之间的相对次序,微软亚洲研究院的研究员们提出利用序数回归解决此类的问题。序数回归是针对具有主观上的自然排序的数据集进行建模与预测。类似的问题如预测年龄、甄别信用好坏、美感高低等,都有很大的应用潜力。
基于锚定参考样本的序数回归
收集数据时,研究员们发现对于标注者,给一个样本1到5的分数相对于找出一对样本的优劣更加困难,也更容易出现打分时因打分人与评测时间变化而产生的浮动与偏移。这是因为对于某些样本,由于评分者的心理或生理变化,使评判标准发生了迁移,出现了浮动的主观评分。一对样本相比较更容易判断孰好孰坏。尽管样本对之间的比较更为一致和准确,但由于不同样本对可能组合的待测数量呈阶乘式上升,导致人力与金钱成本同比上升,因此几乎不可能使打分人通过大量的对比确定待测样本的水平。但对机器而言,决定一对样本间的相对优劣可由一个二元分类器轻易完成,对于计算机的算力也不是很大的负担。
通过这样的观察,研究员们提出了 基于锚定参考样本的序数回归 Ordinal Regression with Anchored Reference Sampless (ORARS) 。如图1所示,该方法的基本逻辑是在不同的分数段分别选取若干样本作为锚点(Anchor),对于新的待测样本,为了确定它的对应等级,所以将该待测样本分别与不同分数子集内的参考锚定样本相比较,从而得到待测样本在整体序列中的位置,以及对应的分数。举个例子,有一待测样本在对比过程中,比在1分、2分段中的锚定样本表现更佳,和3分段中的样本不相上下,比4分、5分中的样本稍显不足,那么很容易可以推断出其最适当的分数为3分。这种方法不是直接去预测分数,而是将分数所代表的序数关系还原到原始的数列分布中,找出其对应的位置。对于机器来说,理解不同分数的绝对意义是相对更难的操作,尤其是细粒度分段,如100分制,而 ORARS 方法将此类的打分问题回归到最为朴素的本质,也就是比较样本对之间的相对优劣,并以对应位置的样本作为预测的分数预测。
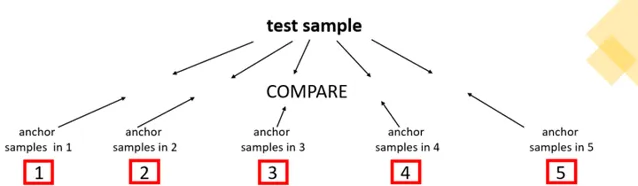
具体来讲,ORARS 分为训练与推断阶段。如图2所示,在训练阶段,首先,从训练集 D(具有专家评测后的样本集合)中分出锚点集(Anchor set)A 与剩余训练集(Training set)T,A 与 T 可有重叠部分,并利用 A 与 T 之间的笛卡尔积生成样本对 (a, b),样本对的对应标签由样本对之间的相对关系决定,分别代表样本 a 优于样本 b,或是样本 a 不优于样本 b。然后,利用构建的样本对集合训练一个用来判断输入样本对间相对优劣的二分类器。在推断阶段,则先将待测样本与选定的锚点集 A 同样进行配对,然后利用在训练阶段获得的二分类器进行推断,最后利用待测样本与锚点集中所有样本的比对结果打分。
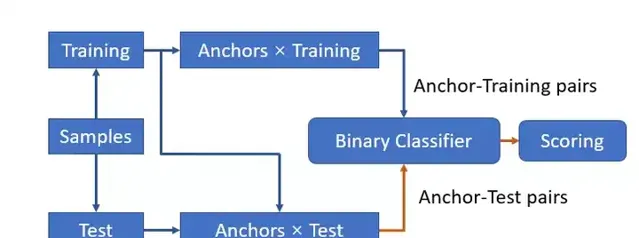
对于推断过程中打分部分,研究员们提出了两种不同的打分逻辑,分别适用于样本分布比较均匀与样本分布不均的情况。
方法一:对于数据分布较为均匀的样本集,在选定锚点集 A 时,假设共有 N 个等级,对每个等级选取 M 个样本作为锚点,一般建议选择在人工打分中多个标注者意见较为统一的样本作为锚点。记训练的二分类器的推断结果为 P(x_t, x_a),其物理意义为待测样本是否比锚定参考样本 x_a 的更优,则最终分数为 s= ∑_(i=1)^(N*M)(P(x_t,x_a)/M)。这种方法利用待测样本与各分数段待测样本之间的比较,通过加权平均的方式得到最终的预测分数。
方法二:对于数据分布不均匀或等级较多的样本集(如百分制),选取均匀的锚点集是极具挑战的,因此研究员们用训练集中所有样本作为参考锚点,将待测样本与所有的样本进行对比,利用所有的模型输出求和得到待测样本在锚点序列中的「排序」,并利用锚点集中对应排名的样本分数作为预测分数。
基于锚定参考样本的序数回归有以下优势 :第一,利用序数信息将传统的多分类器或回归器简化为样本对之间的相对比较。一来,二元比较更为简单,二来,通过原有数据样本间的组合配对生成了多量的数据样本,如此训练二分类器,更多的数据、更简单的优劣比对保证了模型的性能。第二,相较于传统序数回归方法,ORARS 引入了锚定参考样本,通过样本对之间的比较确定待测样本水平,锚定参考样本在对比的过程中,提供了参考信息,构建了更加准确的序数空间与序数回归的精细量化。
ORARS在计算机辅助语言学习中的应用
基于锚定参考样本的序数回归由于引入了序位信息,并将原来的打分问题转化为样本对之间的比较,所以优化了性能。
研究员们在三个子问题中验证了其有效性,分别为英文语音的流利度、语音的发音准确度,还有英文的写作能力。一方面,三个子问题分别属于语音信号处理与自然语言处理领域,另一方面,三个问题的数据集样本量分别为8000,2500,350。这些实验可以验证 ORARS 方法在不同问题和大小数据集的普适性与鲁棒性。
语音流利度打分
利用8000句来自微软小英的 ESL(English as Second Language)说话人语料,每句话由两位语言学背景的专业编辑进行5分制评分,并以平均分作为标注。若两位编辑打分分差大于2分,将引入第三位专业编辑进行仲裁。
之后,选取500句作为测试集,剩余部分用作训练集,利用语速、停顿等六维流利度特征对比 ORARS 方法和基于 DNN 与 SVM 的分类器、SVR 回归器,以及经典序数回归方法序数二元分解[4]与多任务序数回归[5]。

通过在 Pearson Correlation Coefficient (PCC) 上,平均绝对误差 Mean Absolute Error (MAE) 以及细粒度误差比例(Fine Error,预测误差小于0.5的比例)和粗粒度误差比例(Coarse Error,预测误差大于1.5的比例)的对比,可以看到基于序数回归的方法可以提高模型的性能, ORARS 方法则可以达到最优性能,甚至在 MAE 与 Fine Error 上超过了专家评测 。
语音的发音准确度打分
利用2500句来自微软小英的 ESL 说话人在跟读场景下的语料,每句话请四位有语言/语音学背景的专业编辑以5分制评分,以最后的平均分作为标注。
传统的发音打分一般是基于 GOP (Goodness of Pronunciation) 完成,先得到各个音素的发音得分,再采取平均的方式得到句子级别的总分。但这样的方法具有以下问题:1)简单的平均运算忽略了各音素间的差异,不能代表整句话的发音水平;2)忽略了打分问题中的相对排序信息。因此该任务提出了句子级别的特征(average GOP vector + confusion GOP vector),并采用 ORARS 方法组建打分模型。
研究员们基于不同的声学模型(Acoustic model, AM)执行了两组实验,分别记为 AM1 与 AM2,并利用五折交叉验证(5-fold cross-validation) 的方法验证了模型的性能。通过对比传统方法 GOP 及其最新变种 Transition Awarepronunciation Score (TA Score), 以及基于神经网络的回归方法和 ORARS 方法之间的性能差异,并采用 Pearson Correlation Coefficient (PCC),Spearman Correlation Coefficient (SCC) 以及 MAE 进行对比,结果如表2所示:
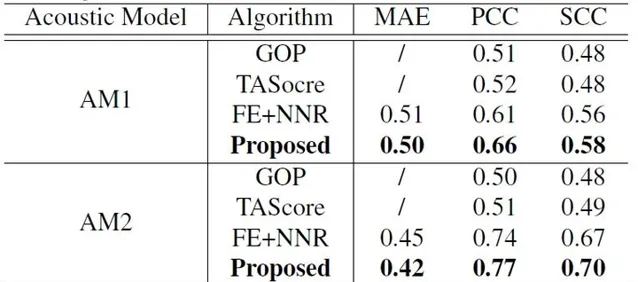
通过对比可以发现,研究员们提出的 ORARS 方法相较于传统的 GOP 方法在 PCC,SCC 指标上分别相对提升了26.9%与20.8%, 并达到了与人类打分水平相当,或更好的水平 。
英文写作打分
研究员们收集了350篇托福 (TOEFL) 独立写作,并让专业标注团队基于满分30分制进行打分标注,每篇文章由两人标注。微软小英采用了基于词、句、段等方面的特征进行模型建模,并利用十折交叉验证的方式对比了不同模型的性能,具体如表3所示:
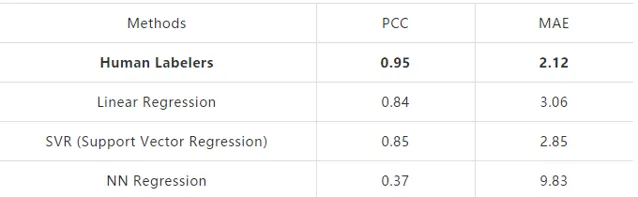
实验结果显示,ORARS 方法相较于其他方法性能更优。由于数据量很少,基于神经网络 Neural Net (NN) 的回归几乎无法训练,然而 ORARS 方法通过样本对组合,增加了训练核心二分类器的数据量,展现出了优异的性能。不过当数据量过少时,虽然 ORARS 比传统机器学习方法效果更优,但机器学习的性能仍然不如专家评测。
总结与分析
ORARS 方法将传统的主观打分问题转化为一系列样本对之间的二元优劣比较,相比传统的机器学习方法及序数回归,ORARS 方法的打分功能得到了稳定的提升。基于 ORARS 的发音评分及写作打分现已应用于微软 Azure 语音发音打分服务(Speech Pronunciation Rating Service)及微软爱写作应用中。除了应用在语言学习的主观打分方面,ORARS 方法还将可以应用到更多的排序问题上,如由人脸决定年龄、由音色识别年龄、主观美感评级等等。该方法充分利用了人类在处理同类问题中的认知理解,在未来的研究中,微软小英团队也将会从数学、理论和认知的角度,进一步阐述对于 ORARS 方法的理论分析与推广更多应用。
ORARS 方法也已经应用到了微软 Azure 语音服务 Speech-to-Text(语音转文本)的语音评测功能中,微软小英就是基于该功能进行构建的。微软希望可以借此更好地赋能教育领域解决方案的合作伙伴、应用开发者以及语言学校、培训中心、教育机构、考试中心的各种语言学习、口语练习和考试等场景的开发。
欢迎试用微软小英以及微软 Azure 语音评测功能,并提供宝贵的意见。
https://www. engkoo.com/
https:// docs.microsoft.com/zh-c n/azure/cognitive-services/speech-service/rest-speech-to-text#pronunciation-assessment-parameters
https:// github.com/Azure-Sample s/Cognitive-Speech-TTS/tree/master/PronunciationAssessment/CSharp/WPF
[1] Shaoguang Mao, Zhiyong Wu, Jingshuai Jiang, Peiyun Liu, Frank Soong, NN-based ordinal regression for assessing fluency of ESL speech. [in] Proc. ICASSP 2019, pp. 7420-7424, 2019.
[2] Bin Su, Shaoguang Mao, Frank Soong, Yan Xia, Jonathan Tien, Zhiyong Wu, Improving pronunciation assessment via ordinal regression with anchored reference samples. [in] arXiv preprint arXiv:2010.13339, 2020.
[3] Improve remote learning with speech-enabled apps powered by Azure Cognitive Services. Microsoft Tech Community Blog
https:// techcommunity.microsoft.com /t5/azure-ai/improve-remote-learning-with-speech-enabled-apps-powered-by/ba-p/1612807
[4] Ling Li, Hsuan-Tien Lin, Ordinal regression by extended binary classification. [in] Proc. Advances in neural information processing systems, pp. 865-872, 2007.
[5] Zhenxing Niu, Mo Zhou, Le Wang, Xinbo Gao, Gang Hua, Ordinal regression with multiple output cnn for age estimation. [in] Proc. CVPR, pp. 4920-4928, 2016.
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的「邀请」,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究











