在前面的基礎上:
此時我們知道有可能能經過某種神奇的操作,使得GPU在某種情況下,的確能夠比CPU計算的快一些。但是,某些情況下,GPU速度反而不如CPU,使得在說出這個結論時總感覺有些不是很暢快。
或者說這是一兩朵小烏雲。
那麽是不是記錯了呢?記憶有時候具有欺騙性,這裏本文決定重現一下:
CMakeLists.txt:
cmake_minimum_required
(
VERSION
3.17
)
project
(
vector_add
CXX
)
set
(
CUDA_ENABLE
true
)
if
(
CUDA_ENABLE
)
enable_language
(
CUDA
)
endif
()
set
(
MPI_ENABLE
true
)
set
(
PRJ_SRC_LIST
)
set
(
PRJ_HEADER_LIST
)
set
(
PRJ_LIBRARIES
)
set
(
PRJ_INCLUDE_DIRS
)
file
(
GLOB
root_header_files
"${CMAKE_CURRENT_SOURCE_DIR}/*.h"
)
file
(
GLOB
root_src_files
"${CMAKE_CURRENT_SOURCE_DIR}/*.cpp"
)
file
(
GLOB
root_cuda_files
"${CMAKE_CURRENT_SOURCE_DIR}/*.cu"
)
list
(
APPEND
PRJ_HEADER_LIST
${
root_header_files
}
)
list
(
APPEND
PRJ_SRC_LIST
${
root_src_files
}
)
list
(
APPEND
PRJ_SRC_LIST
${
root_cuda_files
}
)
add_executable
(
${
PROJECT_NAME
}
${
PRJ_SRC_LIST
}
${
PRJ_HEADER_LIST
}
)
target_include_directories
(
${
PROJECT_NAME
}
PRIVATE
${
PRJ_INCLUDE_DIRS
}
)
target_compile_features
(
${
PROJECT_NAME
}
PUBLIC
cuda_std_14
cxx_std_14
)
set_target_properties
(
${
PROJECT_NAME
}
PROPERTIES
#CUDA_ARCHITECTURES "50;75"
CUDA_ARCHITECTURES
"35;50;52;72;75"
CUDA_SEPARABLE_COMPILATION
ON
)
target_link_libraries
(
${
PROJECT_NAME
}
PRIVATE
${
PRJ_LIBRARIES
}
)
kernel.cu:
#include
"cuda_runtime.h"
#include
<vector>
#include
<iostream>
#include
<ctime>
using
namespace
std
;
void
addWithCuda
(
int
*
a
,
int
*
b
,
int
*
c
,
unsigned
int
nElements
);
void
addWithCPU
(
int
*
a
,
int
*
b
,
int
*
c
,
unsigned
int
nElements
);
__global__
void
addKernel
(
int
*
a
,
int
*
b
,
int
*
c
);
void
TestAddTime
();
double
CpuSecond
();
double
CpuSecond
()
{
clock_t
now_time
=
clock
();
return
static_cast
<
double
>
(
now_time
)
/
CLOCKS_PER_SEC
;
}
void
SetDevice
(
int
devId
)
{
cudaDeviceProp
deviceProp
;
cudaGetDeviceProperties
(
&
deviceProp
,
devId
);
cout
<<
"Using device "
<<
devId
<<
": "
<<
deviceProp
.
name
<<
"
\n
"
;
cudaSetDevice
(
devId
);
}
int
main
()
{
TestAddTime
();
return
0
;
}
void
TestAddTime
()
{
int
arraySize
=
4096
*
4096
;
vector
<
int
>
a
(
arraySize
,
0
);
vector
<
int
>
b
(
arraySize
,
1
);
vector
<
int
>
c
(
arraySize
);
double
cpuStart
=
CpuSecond
();
addWithCPU
(
&
a
[
0
],
&
b
[
0
],
&
c
[
0
],
arraySize
);
double
cpuTime
=
CpuSecond
()
-
cpuStart
;
cout
<<
"CPU Execution Time: "
<<
cpuTime
<<
" sec
\n
"
;
double
gpuStart
=
CpuSecond
();
addWithCuda
(
&
a
[
0
],
&
b
[
0
],
&
c
[
0
],
arraySize
);
double
gpuTime
=
CpuSecond
()
-
gpuStart
;
cout
<<
"GPU Execution Time: "
<<
gpuTime
<<
" sec
\n
"
;
cudaDeviceReset
();
}
void
addWithCuda
(
int
*
a
,
int
*
b
,
int
*
c
,
unsigned
int
nElements
)
{
int
*
dev_a
=
0
;
int
*
dev_b
=
0
;
int
*
dev_c
=
0
;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaSetDevice
(
0
);
int
nBytes
=
nElements
*
sizeof
(
int
);
cudaMalloc
(
(
void
**
)
&
dev_a
,
nBytes
);
cudaMalloc
(
(
void
**
)
&
dev_b
,
nBytes
);
cudaMalloc
(
(
void
**
)
&
dev_c
,
nBytes
);
cudaMemcpy
(
dev_a
,
a
,
nBytes
,
cudaMemcpyHostToDevice
);
cudaMemcpy
(
dev_b
,
b
,
nBytes
,
cudaMemcpyHostToDevice
);
// Launch a kernel on the GPU with one thread for each element.
addKernel
<<<
1
,
nElements
>>>
(
dev_a
,
dev_b
,
dev_c
);
cudaDeviceSynchronize
();
cudaMemcpy
(
c
,
dev_c
,
nBytes
,
cudaMemcpyDeviceToHost
);
cudaFree
(
dev_c
);
cudaFree
(
dev_a
);
cudaFree
(
dev_b
);
}
void
addWithCPU
(
int
*
a
,
int
*
b
,
int
*
c
,
unsigned
int
nElements
)
{
for
(
int
i
=
0
;
i
<
nElements
;
++
i
)
{
c
[
i
]
=
a
[
i
]
+
b
[
i
];
}
}
__global__
void
addKernel
(
int
*
a
,
int
*
b
,
int
*
c
)
{
int
i
=
threadIdx
.
x
;
c
[
i
]
=
a
[
i
]
+
b
[
i
];
}
編譯執行:
已啟動重新生成…
1>------ 已啟動全部重新生成: 專案: ZERO_CHECK, 配置: Debug x64 ------
1>Checking Build System
2>------ 已啟動全部重新生成: 專案: vector_add, 配置: Debug x64 ------
2>Building Custom Rule D:/work/cuda_work/VectorAddSpeedTest/CMakeLists.txt
2>Compiling CUDA source file ..\kernel.cu...
2>
2>d:\work\cuda_work\VectorAddSpeedTest\build>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\bin\nvcc.exe" -gencode=arch=compute_35,code=\"compute_35,compute_35\" -gencode=arch=compute_35,code=\"sm_35,compute_35\" -gencode=arch=compute_50,code=\"compute_50,compute_50\" -gencode=arch=compute_50,code=\"sm_50,compute_50\" -gencode=arch=compute_52,code=\"compute_52,compute_52\" -gencode=arch=compute_52,code=\"sm_52,compute_52\" -gencode=arch=compute_72,code=\"compute_72,compute_72\" -gencode=arch=compute_72,code=\"sm_72,compute_72\" -gencode=arch=compute_75,code=\"compute_75,compute_75\" -gencode=arch=compute_75,code=\"sm_75,compute_75\" --use-local-env -ccbin "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\HostX64\x64" -x cu -rdc=true -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include" --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile -cudart static -std=c++14 -Xcompiler="/EHsc -Zi -Ob0" -g -D_WINDOWS -D"CMAKE_INTDIR=\"Debug\"" -D_MBCS -D"CMAKE_INTDIR=\"Debug\"" -Xcompiler "/EHsc /W1 /nologo /Od /Fdvector_add.dir\Debug\vc142.pdb /FS /Zi /RTC1 /MDd /GR" -o vector_add.dir\Debug\kernel.obj "d:\work\cuda_work\VectorAddSpeedTest\kernel.cu"
2>CUDACOMPILE : nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
2>kernel.cu
2>已完成生成專案「vector_add.vcxproj」的操作。
2>
2>d:\work\cuda_work\VectorAddSpeedTest\build>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\bin\nvcc.exe" -dlink -o vector_add.dir\Debug\vector_add.device-link.obj -Xcompiler "/EHsc /W1 /nologo /Od /Fdvector_add.dir\Debug\vc142.pdb /Zi /RTC1 /MDd /GR" -L"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\bin/crt" -L"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\x64" cudadevrt.lib cudart_static.lib kernel32.lib user32.lib gdi32.lib winspool.lib shell32.lib ole32.lib oleaut32.lib uuid.lib comdlg32.lib advapi32.lib -forward-unknown-to-host-compiler -Wno-deprecated-gpu-targets -gencode=arch=compute_35,code=compute_35 -gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=compute_50 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_52,code=compute_52 -gencode=arch=compute_52,code=sm_52 -gencode=arch=compute_72,code=compute_72 -gencode=arch=compute_72,code=sm_72 -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --machine 64 vector_add.dir\Debug\kernel.obj
2>cudadevrt.lib
2>cudart_static.lib
2>kernel32.lib
2>user32.lib
2>gdi32.lib
2>winspool.lib
2>shell32.lib
2>ole32.lib
2>oleaut32.lib
2>uuid.lib
2>comdlg32.lib
2>advapi32.lib
2>kernel.obj
2> 正在建立庫 D:/work/cuda_work/VectorAddSpeedTest/build/Debug/vector_add.lib 和物件 D:/work/cuda_work/VectorAddSpeedTest/build/Debug/vector_add.exp
2>vector_add.vcxproj -> D:\work\cuda_work\VectorAddSpeedTest\build\Debug\vector_add.exe
3>------ 已跳過全部重新生成: 專案: ALL_BUILD, 配置: Debug x64 ------
3>沒有為此解決方案配置選中要生成的專案
========== 全部重新生成: 成功 2 個,失敗 0 個,跳過 1 個 ==========

GPU比CPU慢了10倍不止,雖然看不太懂,但是大受震撼。
難不成debu模式不可靠?換release:

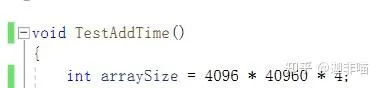
改變問題規模:
從

改為:
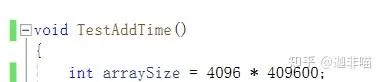
此時,有(debug模式)
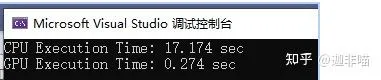
Release:
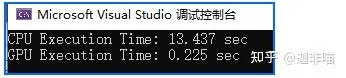
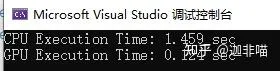
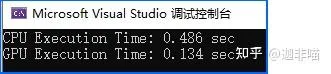
可見這種規模下GPU的速度的確要快一些。可見這是個和規模相關的問題,那麽再將問題規模縮小一些:
此時,有(debug模式)
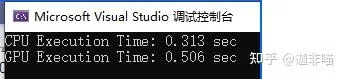
Release:
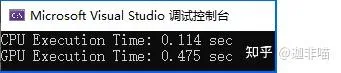
再增加一些規模:
此時,有(debug模式)
Release:
應該指出的是,這個計時可能不是完全準確的,但是可以提供一種參考。
下面進一步退回到前面GPU比CPU計算慢的部份,看看問題的原因是什麽?
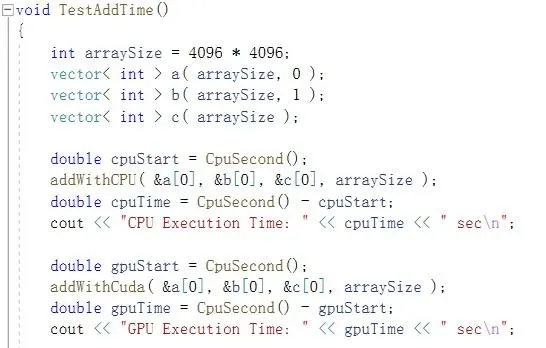
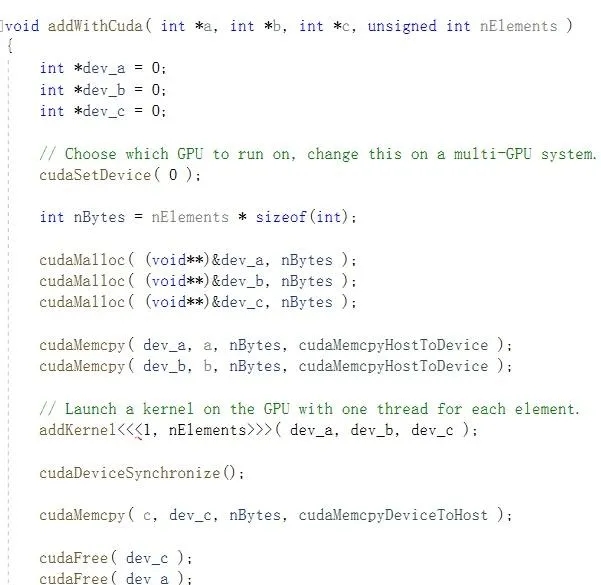
可以看到至少在addWithCuda函數裏面有:

這種和器材相關的操作會不會占用時間呢?
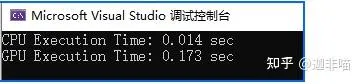
先測試一下時間:
將程式碼重構為:

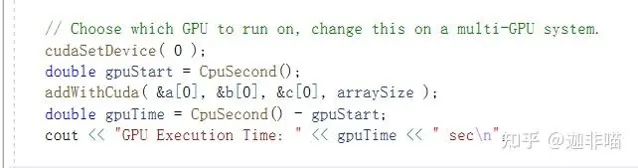
執行,有:
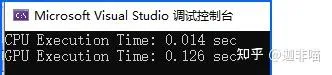
可見,這個器材的開啟占用了很多時間。
這給了一個重構方向,是不是還有很多和計算無關的部份把關心的問題掩蓋了?
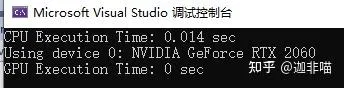
繼續:

這時GPU的時間又顯著減少了。說明記憶體分配這些雜事比較耗費時間。
繼續沿此思路重構:

此時有:
繼續:
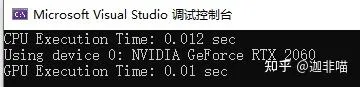
說明copy這些操作很耗時。
繼續重構,讓CPU,GPU各迴圈10次,有:

此時:
這樣,透過以上步驟,基本上測試了GPU向量相加的一些時間消耗的問題,使得其與CPU的耗費之間的關系有了一些可以接受的解釋。感興趣者可以沿此思路進行更細致的研究。
為便於檢索,文章收錄於:







![[足球史記·表二]雙王—60年歐冠決賽](http://img.jasve.com/2024-7/c1cba3fc9e879cb51037beac7c88d732.webp)
![[足球史記·書四] 60](http://img.jasve.com/2024-8/d2edd287228b433acdd02881dbe95303.webp)


