編輯:喬楊
【新智元導讀】70年前科學家們所暢想的「機器常識」被LLM實作了嗎?Nature最近的一篇評論文章給出了否定的答案,並堅定地指出:常識推理是AGI的必備品。
自從2022年ChatGPT橫空出世以來,LLM進入了一日千裏、突飛猛進的發展階段。
一些專家和研究人員推測,這些模型的問世,代表著我們向「通用人工智能」(AGI)的實作邁出了決定性的一步,從而完成了人工智能 (AI) 研究70年來的探索。
這一歷程中的一個重要裏程碑之一,就是機器能夠展現出「常識」。
對人類來說,「常識」是關於人和日常生活的「顯而易見的事情」。比如,我們可以從經驗中知道,玻璃是易碎的,或者給吃素的朋友端上來一盤肉是不禮貌的。
然而,在「常識」這一點上,即使是當今最先進、最強大的LLM也常常達不到要求。

一名機器人藝術家在2022年英國Glastonbury音樂節上為表演者作畫
LLM非常善於在涉及記憶的測試中取得高分,比如GPT-4最為人稱道的成績之一,就是可以透過美國的醫生和律師執業考試,但依舊很容易被簡單的謎題搞迷糊。
如果你問ChatGPT「Riley很痛苦,之後她會感覺如何?」,它會從很多個選項中挑出「覺察」(aware)作為最佳答案,而不是對人類來說顯而易見的「痛苦」(painful)。
為了彌補這方面的缺陷,很多這類的選擇題都被納入到流行的基準測試中,用於用於衡量AI對常識的掌握。
然而,這些問題很少能夠真正反映現實世界,包括人類對物理定律的直覺理解,以及社互動動中的背景和語境。因此,要量化出LLM的「類人」程度仍然是一個尚未解決的問題。
相比於AI,我們可以發現人類認知的一些不同之處。
首先,人類善於處理不確定和模糊的情況,會滿足於一個「令人滿意但未必最佳」的答案,很少消耗大量的認知資源去執著於找到最佳的解決方案。
其次,人類可以在「直覺推理」和「深思熟慮」的模式之間靈活切換,從而更好地應對小概率的突發情況。
AI能否實作類似的認知能力?我們又如何如何確切地知道AI系統是否正在獲得這種能力?
這就不僅僅是AI或電腦科學的問題,還需要涉足發展心理學、認知哲學等學科,同時我們也需要對人類認知過程的生物基礎有更深入的了解,才能設計更好的指標來評估LLM的表現。
AI發展出常識,從何時開始?
機器常識的研究,還是要追溯到深度學習領域不得不提的一個時間點——1956年,紐咸西州達特茅斯的那場暑期研討會。
這場會議將當時頂尖的AI研究人員聚集在了一起,隨後就誕生了基於邏輯的符號框架,使用字母或邏輯運算子來描述物件和概念之間的關系,用於構建有關時間、事件和物理世界的常識知識。
例如,一系列「如果發生……,那麽就會發生……」的語句可以被手動編程到機器中,用於教會一個常識性事實,比如不受支持力的物體會因為重力而下落。
這類研究確立了機器常識的願景,即構建能夠像人類一樣有效地從經驗中學習的電腦程式。
從技術角度定義,這個目標就是制造一台機器,在給定一組規則的情況下,「根據已知內容和資訊,自行推斷出範圍足夠廣泛的直接結果」 。

在加州舉行的機器人挑戰賽中,一個人形機器人向後摔倒
因此,機器常識不僅限於有效學習,還包括自我反思和抽象等能力。
從本質上講,常識需要事實知識,也需要利用知識進行推理的能力。僅僅是記住大量事實是不夠的,從現有資訊中推斷出新資訊同樣重要,這樣才能在新的或不確定的情況下做出決策。
20世紀80年代時,研究人員開始進行早期嘗試,希望賦予機器以常識和決策能力,主要的手段是建立結構化的知識數據庫,例如CYC、ConceptNet等專案。
CYC這個名字的靈感來源於「百科全書」(encyclopedia),不僅包含了事物間的關系,還嘗試使用關系符號來整合上下文相關的知識。
因此,憑借CYC,機器能夠區分事實知識(例如「美國第一任總統是喬治·華盛頓」)和常識知識(例如「椅子是用來坐的」)。
ConceptNet專案有類似的原理,同樣是將關系邏輯對映到一個由三元詞組構成的龐大網絡(例如「蘋果」—「用來」—「吃」)。
然而,無論是CYC,還是ConceptNet,都不具備推理能力。
常識推理的挑戰性在於模糊性,因為在提供更多資訊後,情況或問題就會變得很難確定。
比如,想要回答「Lina和Michael正在節食,他們來做客時我們要準備蛋糕嗎?」這個問題,如果添加了另一個事實「他們有cheat days」,答案就會變得相對復雜且難以抉擇。
基於符號和規則的邏輯無法處理這種模糊性,甚至依靠概率生成下一個token的LLM也無濟於事,因為引入關於「cheat days」的額外資訊不僅會降低確定性,還會完全改變語境。
AI系統如何應對這種未見的、不確定的情況,將直接決定機器常識前進演化的速度,我們要做的,就是開發出更好的評估方法來跟蹤相關進展,但「衡量常識」這個任務並沒有看起來這麽容易。
LLM有常識嗎?這很難評
目前評估AI系統常識推理能力的80多項著名測試中,至少75%是多項選擇測驗。然而,從統計的角度來看,這樣的測驗最多也只能給出模棱兩可的結果。
向LLM提出一個相關領域的問題,並不能揭示模型是否擁有更廣泛的事實知識,因為LLM在響應特定查詢時,並不會以統計學上有意義的方式從知識庫中進行采樣。
比如,即使向LLM提出兩個非常相似的問題,也可能會得到截然不同的答案。
對於不涉及多項選擇題的測試,比如為影像生成合適標題,也很難完全探測到模型的多步驟和常識性推理能力。
不涉及多項選擇測驗的測試(例如,為影像生成適當的影像標題)不會完全探測模型顯示靈活、多步驟、常識性推理的能力。
因此, 機器常識相關的測試方案和方法仍需要發展,從而更清楚地區分「知識」和「推理」。
有一種方法可以用於改進當前測試,就是要求AI解釋給出當前答案的理由。例如,一杯咖啡放在室外會變涼,這是常識,但其中的推理過程涉及熱傳遞、熱平衡等物理概念。
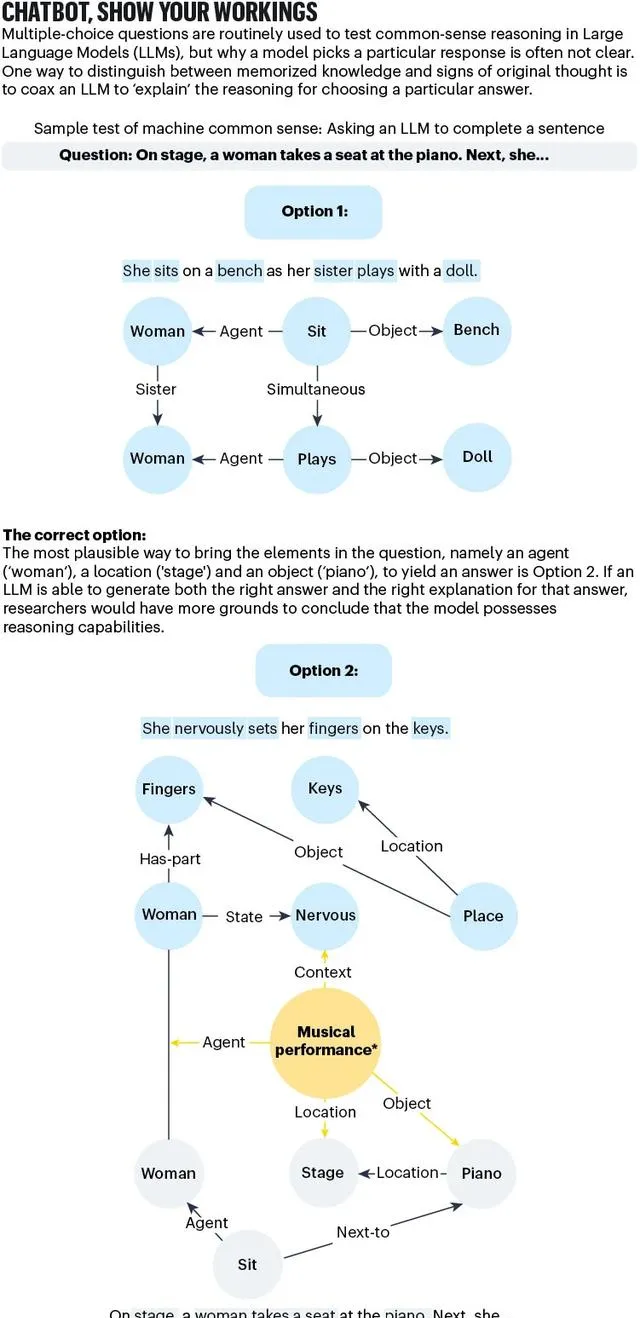
盡管LLM可能會生成正確的答案(「因為熱量逸散到周圍的空氣中」),但基於邏輯的響應將需要逐步的推理過程來解釋原因。
如果LLM能夠使用CYC專案開創的那種符號語言來復現出正確的原因揭示,我們就更有理由認為,模型不僅僅是透過參考訓練語料來尋找答案,而是確實發展出了常識推理能力。
另一類開放式測試,就是考察LLM的計劃或戰略規劃能力。
想象一個簡單的遊戲:能量令牌隨機分布在棋盤上,玩家需要在棋盤上移動20次,收集盡可能多的能量並將其放到指定的地方。
在這類遊戲中,人類不一定能找到最佳解決方案,但常識推理足以支持我們拿到合理的分數。那LLM呢?
研究人員進行測試後發現,模型的表現遠遠低於人類。
從LLM的行為來看,它似乎理解了遊戲規則:它可以棋盤上移動,有時也能找到能量令牌並收集起來,但會犯各種看似愚蠢的錯誤,比如將能量令牌丟在錯誤的位置。
鑒於LLM會犯這種有常識的人都不會犯的錯誤,因此我們很難期待這種模型在解決更混亂的現實規劃問題時,能夠有更出色的表現。
下一步怎麽走
為了系統地奠定機器常識的基礎,可以考慮采取以下步驟:
「把盤子做大」
研究人員需要超越單純的AI或電腦科學領域的經驗,涉足認知科學、哲學和心理學等學科,找出關於人類如何學習、如何套用常識的關鍵原理。
這些原則應該能夠指導我們,建立能夠進行類人推理的AI系統。
擁抱理論
與此同時,研究人員需要設計全面的、理論驅動的基準測試,反映廣泛的常識推理技能,例如理解物理特性、社互動動和因果關系。
這些基準測試的目標,必須是量化AI系統跨領域概括常識知識的能力,而不是專註於一組狹窄的任務 。
超越語言的思考
誇大LLM能力的風險之一就是誇大了語言的重要性,這會讓我們與另一個重要願景脫節——構建能在混亂現實環境中感知、導航的具身系統。
DeepMind聯合創始人Mustafa Suleyman就認為,實作「有能力」的AI(capable)可能是比AGI更切實可行的裏程碑。
至少在人類基本水平上,如果要構建具有物理能力的人工智能,具體化的機器常識是十分必要的。然而,目前的AI似乎仍處於獲取幼兒水平身體智力的早期階段。
令人欣喜的是,研究人員開始在以上所有方面取得了進展,但仍有很長的路要走。
隨著人工智能系統,尤其是LLM成為各種套用的主要內容,理解人類推理的能力將在醫療保健、法律決策、客服和自動駕駛等領域產生更可靠和值得信賴的結果。
例如,具有社交常識的客服機器人將能夠推斷出使用者的沮喪情緒,即使沒有明確的表達出來。
從長遠來看,也許機器常識領域的最大貢獻,將是讓人類更深入地了解自己。











