最近要考試了,就不繼續往下看,開始一邊復習考試一邊稍微看看最近學的機器學習相關。
這一篇想說的是EM演算法。想說的原因是在回顧PRML第三章最後關於超參數的evidence的求解過程時候突然感覺這和EM似乎有點像。這是evidence的最佳化目標:
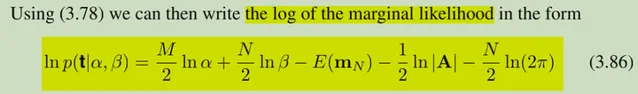
而這個evidence的產生是來自於這個分解(marginalization):

其實fully bayesian的視角就可以看成是對整個模型加了個隱變量,因此似乎理論上也可以用EM algorithm那套對於隱變量模型的叠代逼近參數演算法來搞,但事實上並沒有這麽用,為什麽咧?
我的理解是:它「用了」,也沒有「用」。
前半句的原因是來源於第二張圖,它和對於EM algorithm模型一樣,嘗試用marginalization的方法對原來的機率進行分解(EM algorithm據我所知有兩個proof,分別使用兩種不同的分解,一個采用jenson不等式,一個采用kl divergence來證明的,這裏說的是關於jenson不等式的那個proof)。
後半句是因為,這個model和一些用em algorithm的model還是有些不同之處的:那些model(比如GMM)積分號裏面雖然能夠解析的寫出來,但往往不能直接寫成一整個distribution的形式;而這裏的經過一些化簡,就是一個gauss distribution。因此從某種意義上來說,此處的問題復雜度更低一些,可以用一些更「合適」的叠代演算法(不至於在這一步就直接用不等式放縮),繼續的進行一些對於目標化簡在開始我們的approximation process,而我們的目標化簡過程就是從第二張圖化簡到了第一張圖。這就是普遍的EM過不來的一步。
然後現在的問題就是轉化成了對第一張圖的式子做近似,因為此時我們又遇到了和當初在考慮EM演算法時相似的問題,直接求gradient是不解析的,再透過觀察這個式子,我再貼一遍:
它的第三項是關於alpha比較復雜的,其他部份關於alpha的gradient都是形式很好的,那麽那麽叠代的靈感就來了,根據初值alpha得到第三項,然後再對固定第三項後的式子求gradient,這樣就可以得到一個叠代的方法了。這也就是PRML在處理這個問題給出的一個具體方法。( 更新:這種靈感也在ADMM演算法中利用過。對於non-smooth的部份采用Proximal Operator的閉式解;對於smooth的部份采用正常的最佳化思路 )
再來回顧一下EM演算法:為了形成對比,采取同樣形式對目標進行拆分(marginalization形式的拆分,但拆分之後不做分解),EM的思路要復雜許多(構造性強很多),它把目標轉化成了一個期望,再利用凹凸性得到一個ELBO(可達下界還是啥名字來著),因為這種構造方式我們可以得到這種approximation的一些很好的性質(收斂性,和一些幾何意義),甚至利用這種分解還能推廣到廣義EM演算法(GEM)。其實EM演算法的本質也是一種座標下降法,只不過EM演算法的第一步比較漂亮是因為某些形式比較好的最佳化函式可以得到解析的第一步(E步)的分布;而GEM演算法就是建立在一些形式不太好的最佳化函式不能直接得到解析的第一步(E步)的分布,因而轉化為另外一個對ELBO的argmax問題,因此EM演算法也可看成是MM演算法(對於ELBO兩個分量利用座標下降法輪流進行argmax的叠代演算法)。
值得一提的是,EM演算法找到的ELBO是一個有一定好的性質的量,因此用ELBO近似原本的最佳化目標,會產生一個可解析(某些模型,如HMM,GMM)的叠代方程式。(如果這個近似的目標比原來目標更難求,那顯然這個方法是不可取的)
具體公式可參見白板視訊(我是想總結一些除了公式外的思路)
最後來總結一下,這兩個演算法本質其實都是一樣的,利用一些分解來構造可叠代的逼近序列,只不過EM演算法的構造更加精細(相對),泛化能力較強,效果也很好;但遇到具體問題,更應該先努力拆分化簡最佳化目標,如果形式很差的話再考慮EM\GEM演算法,不然可能會有一些更簡單、效果也不錯的叠代方法(比如PRML對於超參數的evidence的求解)。











