这取决于怎么定义「性能」,以及怎么定义「天花板」 。
我们目前讨论的消费级CPU设计,往往不是无限功耗(随意超频)或者无限的芯片面积,往往更倾向于在特定功率范围(约为65W)和特定芯片尺寸(约为100mm2)下,怎么设计出更好的CPU。所以,在这个问题下考虑超频性能是不公平且有失偏颇的。
如果要系统回答这个问题,我们应该从CPU性能影响因素开始讲起。
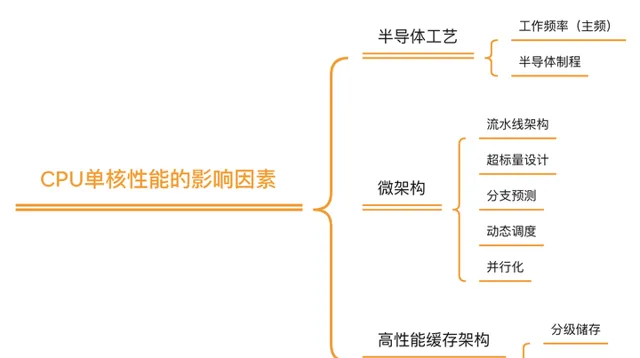
如果我们以目前大家默认的CPU性能衡量标准(CPU单核运算性能)来讲, 理论上CPU性能主要由三方面决定:
就CPU性能,一个非常普遍的观点是,即使(基于硅)的半导体工艺可以继续演进,但纳米级晶体管尺寸带来的量子效应也已经变得越来越不可忽视, 所以半导体制程带来的CPU性能提升可能会在5nm左右(就是现在)出现收益递减 [2] , 这是「CPU性能达到天花板」这一观点的基础 。
但是,这一观点是片面的,因为这种说法仅着眼于工艺进步的边际效应, 而芯片本身的性能进步并不局限于工艺本身 。在硬件,微架构,缓存架构,芯片驱动软件等等方面都有太多地方可以对CPU 晶体管利用率,能耗比,极限性能,芯片极限面积,甚至芯片软件开发时间等等方面做出优化,这些优化都会对传统意义上的「CPU性能」产生积极影响。
我可以把它们分为几类分别讨论,期望能够给大家一个关于芯片性能的更全面的视角。
1. 硬件 –--制程提升带来的边际效应越来越明显,下一步是什么?
1959年,诺贝尔奖获得者Richard Feynman在对美国物理学会的大会演讲上曾这么说过,「计算机性能的进步大多来自于计算机组件的小型化,(这些进步)在底部依然有足够的空间」 [3] 。这里的「底部」其实就是在说CPU这类通用计算芯片。
考虑到CPU的小型化大多依赖于更小的晶体管尺寸和半导体制程的进步,这条评论本身也其实正在间接暗示摩尔定律推动CPU性能进步(注:这句话早于摩尔定律十几年)。而在过去五十年时间里,芯片的发展一直符合这个观点,或者说,
摩尔定律 。
摩尔定律预测,预计18个月会将芯片的性能提高一倍(即更多的晶体管使其更快。我们可以在这里解释的更加详细一点。众所周知,半导体电路(特别是CMOS电路)的电路功耗和工作频率成正比,而工作频率的提升意味着芯片性能的直接提升(大家可以想象超频给电脑所带来的性能增长)。
但是,正如我们之前所说,大多数情况下的消费级CPU在设计时都存在一定的功率范围。这种功率范围既不能太高导致整体耗电急剧增长(或触碰功率墙),也不能太低导致计算能力低下,所以,有没有一种可能让半导体芯片在功率不变的情况下直接提升性能工作频率?
换句话说,我们在期望能通过某些设计来提升CPU的能量效率?
答案是肯定的。

这也是1970年左右,Dennard (MOSFET)Scaling Law 产生的基础: 在半导体芯片里,每代将会使晶体管尺寸减少30%,并且同时保持晶体管里各处的电场恒定 。晶体管尺寸减少(也就是制程提升)会带来很多好处:
Dennard Scaling Law 带来的直接预测结果是,在每一代半导体制程进步中,晶体管的密度都翻了一番,性能将提高 40%,而整体系统功耗几乎保持不变。 如果配合摩尔定律,几乎等同于每18个月,芯片的每瓦性能将会翻一倍 (见下图 [4] ) 。
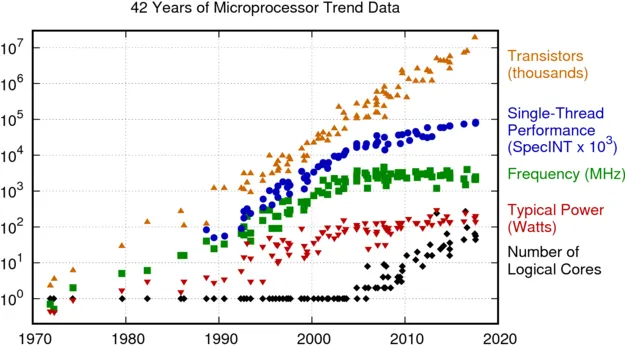
这也是过去二十年间,推动芯片制程进步的主要动力:芯片设计师利用晶体管密度来设计更复杂的架构和晶体管速度以提高频率,而得益于晶体管密度的提升,设计师们有足够的空间在合理的功率和能量范围内同时获得复杂的架构和更高的频率。以一种简单粗暴的思路,甚至可以只依靠晶体管的小型化简单粗暴添加更多内核,然后通过制程进步带来的更多「免费」核心来提升CPU性能。
从另一方面来说,更先进的芯片制程不止影响了技术进步,它们也间接影响了计算机的价格(同样的钱能买到更多晶体管,也意味着能买到更多计算性能)。
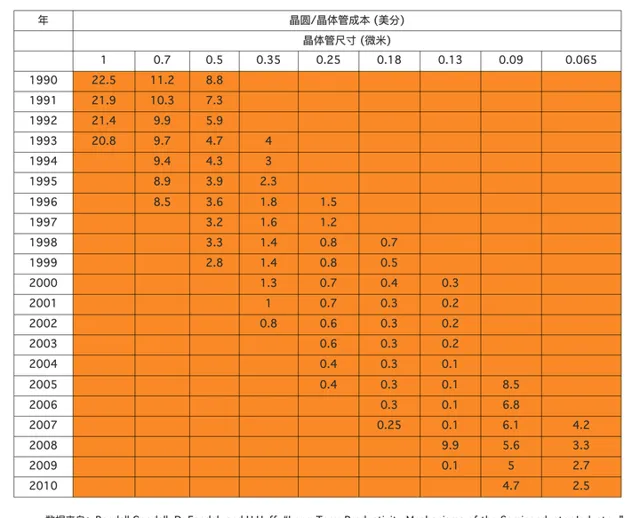
实际上,在20世纪60年代初,一个晶体管要10美元左右,但随着晶体管越来越小,小到一根头发丝上可以放1000个晶体管时,每个晶体管的价格只有千分之一美分。据有关统计,按运算10万次乘法的价格算,IBM704电脑为85美分,IBM709降到17美分,而60年代中期IBM耗资50亿研制的IBM360系统电脑已变为3.0美分,具体统计数据见下图(数据收集自论文 [5] )。
但是在未来,大概率并非如此。
一些观点认为这代表着是摩尔定律的终结,即「后摩尔时代」的到来。这可以通过芯片领域的国家自然基金重点项目指南得到确认(见下图): 我们需要在「后摩尔时代」解决低功耗器件,新材料工艺和新架构的芯片设计问题。

从目前来看,在「后摩尔时代」,晶体管制程的进步仍会继续,但正如之前所说,单位面积晶体管密度增长会不断放缓,从而对整体芯片性能的影响越来越小。既然如此, 架构方面和软件方面 的提升就成了目前的性能提升重点,比如更有效的异构多核架构和领域定制处理器,以及目前的一些研究热点,非冯·诺伊曼体系结构、存内计算、多芯片封装等等。
答案是非常正确的,且有很多例子可以证明这一点。这也是芯片设计中的一种比较重要的设计思想---发现程序中的共性特点,并以硬件设计加速相关共性计算 [6] 。
在计算机历史上, 领域定制处理器 最经典的例子是独立显卡的出现。随着当年影音和图像处理业务越来越多,通用的CPU不能非常有效的处理图形图像所需要的浮点型数据运算,所以显卡就此诞生。
此后也随着多媒体内容逐渐增多,显卡市场也得到了更蓬勃的发展,而且所支持的指令集和显卡架构也在不断升级。在Intel前几天发布的第11代英特尔酷睿处理器高性能移动版(p5)芯片组里,Iris Xe 集成显卡可以支持更快捷的视频转码和多媒体处理,这类领域定制处理器(集成显卡)可以帮助p5完成视频处理的硬件加速,并且通过更多的智能加速引擎为影音处理和游戏提供更好的性能。

领域定制处理器 另一个非常典型的例子是人工智能芯片的兴起,以及(通用处理器)中对人工智能相关指令集的支持力度加大。在芯片设计领域,判断一类应用是否需要专用芯片支持,需要非常大规模的热点代码分析。
08年左右人工智能相关算法方兴未艾,但是一些公司曾经通过大规模的代码分析出人工智能代码运算正在大幅度增加,所以需要设计专用硬件架构来提升人工智能计算效率。同样,在Intel 第11代英特尔酷睿处理器高性能移动版(p5)芯片组里,Intel也通过抽象出Advanced Vector Extensions指令集来大幅度加速电脑所需要的人工智能图像应用,通过Gaussian & Neural Accelerator (Intel® GNA)来提升人工智能语音处理速度。
随着制程提升带来的边际效应越来越明显,硬件方面的提升更多的可能会着眼于在特定面积下的领域定制处理设计,以及更有效的多核心通信方式;当然,半导体材料和工艺的飞跃性进步依然有可能。
2. 算法以及缓存
在很早之前(2010年左右),白宫总统科技咨询委员会就曾经做出过论断,在CPU性能优化上,算法带来的增益已经远远超过提升处理器速度所带来的增益 [3] 。所以,一个普遍的观点是, 上层的算法和调度方法会成为CPU性能提升的下一个关键点 。
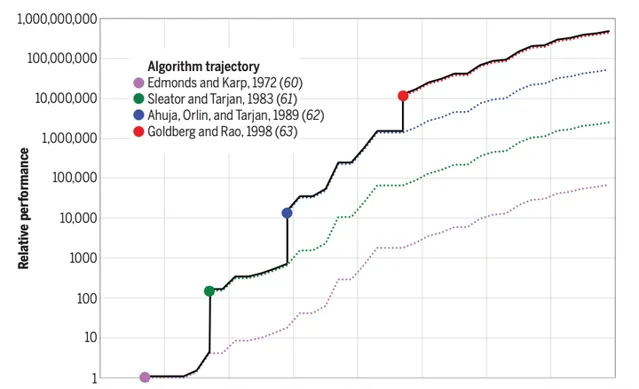
而另一个原因是,算法实现严重依赖于数学领域的建模和抽象,大多数问题往往无解或者暂时无法建模,只有少量问题有算法加速的空间。换句话说,算法的优化不同于芯片制程进步,它是离散而且充满了偶然性,这给相应的CPU性能提升带来了一定的偶然空间。
可以这么说,算法部分能够给CPU性能带来多少提升,很大程度上依赖于这段时间内解决了多少问题。如果大家看上图,就会发现在某些年份里,CPU性能提升是呈现阶梯状的,这正是因为当年算法领域出现了突破性进展。
作为主要研究算法的科研民工,其实我可以在这里加上一句,大多数算法进步也往往会因为假设条件过强,导致无法直接应用于实际工业中,算法和实现之间依然存在非常巨大的鸿沟。
但是,即使如此, 我们依然可以想象到,算法的进步空间并没有受限,它依然可以给CPU性能带来更多提升空间 。
3. 软件和生态
如果大家对软件行业有所了解,就会发先随着计算机普及,高级编程语言(特别是非常简单的脚本语言)变得越来越流行,比如Python。但是,这些代码本身其实是非常低效的。
前段时间Science上的一篇文章 [3] 曾经指出,目前的高级编程语言的运行效率非常低下,如果我们用硬件实现相应的计算方式(以矩阵计算为例),那么速度提升可以达到数万倍,这是非常巨大的提升空间(见下图)。
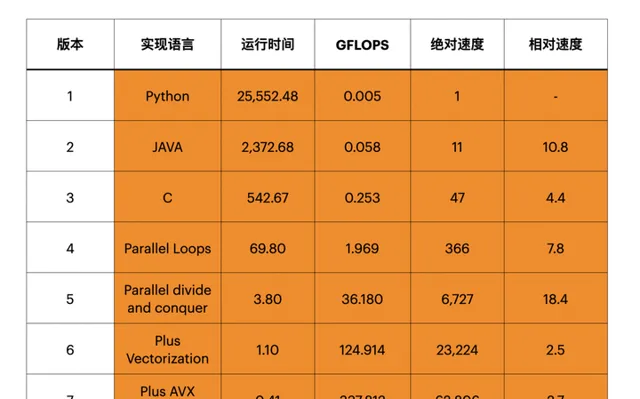
高性能代码对CPU的性能提升有着极大的帮助,但是因为其耗时比较长,目前暂时没有太多关注。这导致我们即使能够看到这些性能提升空间,也暂时难以有效利用。
其中一个非常重要的原因是,算法设计需要人工思考,而且大多数人无法熟练从高级编程语言掌握到汇编语言,如果我们所有的算法都通过设计专用电路来加速的话,流片成本高昂到无法承受。
此外,随着目前的芯片硬件架构设计越来越领域化,高性能的代码可能会更加难以编写。所以,如果摩尔定律或者CPU性能越来越难以进步,可能会出现更多硬件和软件工程师共同设计代码,来优化相应的软件性能 [7] 。
从另一方面上说,芯片本身需要软件驱动,而软件的运行速度并不是唯一衡量指标。事实上,对于越来越多的软件开发者来说,他们更需要的是减少软件开发时间,而不仅仅是「高性能」的计算水平。
这就是「CPU生态」的一种。CPU和芯片公司总是可以通过向开发者提供更简单的开发套件, 来提升(或者有人说是压榨)CPU性能 。大公司往往有更加充足的精力来建设相应生态,Intel应当是其中非常值得提及的例子。
p5提供了20通道的PCI-E接口,以及外置WiFi6芯片,这些外置接口和套件都可以为软件开发者提供更简单的开发方案和开发套件,从用更简单的指令集支持更多应用。从指令集来看,基于X86的指令集可以给第11代英特尔酷睿处理器高性能移动版(p5)提供非常良好的编译器生态,这又大大降低了开发成本,也可以通过原生提供更多丰富的接口,可以原生支持更多设备,从而方便用户扩展。
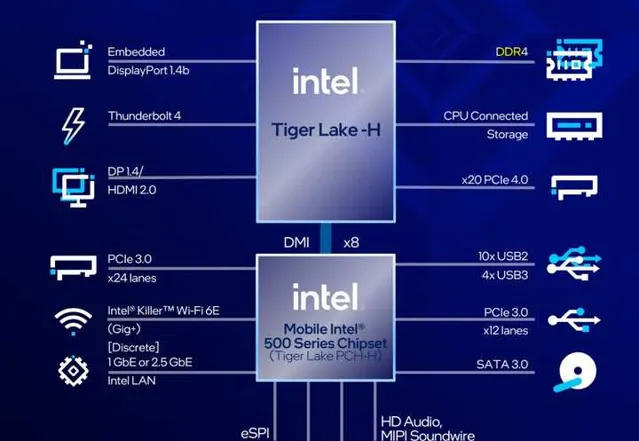
从另一方面来说,对生态的扩展也可以抽象出更多行业共性软件需求,提供更多有价值的高性能代码和指令集,从而进一提升和挖掘CPU性能,这是另一种CPU性能提升空间。
例如,大多3A游戏都深度支持Intel的指令集,从而提升软件使用效率;通过与Killer网卡的深度支持,也可以提升CPU与网卡之间的调度效率,提升用户的游戏体验。

Ending:
或许在可见的未来,芯片微架构,片上网络通信,领域定制处理器,或者本文中未提到的更多芯片优化技术可以给CPU带来更多性能提升。这些优化技术曾经在过去几十年内,在intel CPU中集成了数十上百种,例如超标量,乱序执行,超线程,硬件虚拟化,大页面等等。
又或许,在未来几年内,算法部分和高性能代码研发会出现更多突破性,直接影响到用户的体验。目前科研领域可能会期望更多来自材料领域的进展能够实际使用,影响到消费级CPU,这些都是未来可能的发展方向。
正如大多数芯片从业者都认为,目前的摩尔定律正在接近末尾,但是这并不意味着CPU的性能提升就会停止。未来虽然不可知,但是CPU性能的提升并不会因为制程的收益缓慢而停止。
参考
- ^ Borkar S, Chien A A. The future of microprocessors[J]. Communications of the ACM, 2011, 54(5): 67-77.
- ^ R. Merritt, 「Path to 2 nm may not be worth it,」 EE Times, 23 March 2018.
- ^ a b c Leiserson C E, Thompson N C, Emer J S, et al. There’s plenty of room at the Top: What will drive computer performance after Moore’s law? [J]. Science, 2020, 368(6495).
- ^ Rupp K. 42 years of microprocessor trend data[C]. GitHub. 2018.
- ^ Randall Goodall, D. Fandel, and H.Huff, 「Long-Term Productivity Mechanisms of the Semiconductor Industry,」 Ninth International Symposium on Silicon Materials Science and Technology, May 12–17, 2002, Philadelphia, sponsored by the Electrochemical Society (ECS) and International Sematech.
- ^ a b 多核之后,CPU 的发展方向是什么? - 包云岗的回答 - 知乎 https://www.zhihu.com/question/20809971/answer/1678502542
- ^ President’s Council of Advisors on Science and Technology, 「Designing a digital future: Federally funded research and development in networking and information technology」









