前段时间腾讯的 AI 「绝艺」 在野狐围棋越杀越勇,胜率接近90%,战绩一片红色,充分展示了强化学习自我进化的威力。但就在2月10日画风突变,被几位棋手连杀几局,随后就下线调整去了:
细看棋谱,职业棋手很有想法,确实找到了电脑的一个比较本质的缺陷。例如这盘,电脑持白,对持黑的潜伏(柯洁九段):
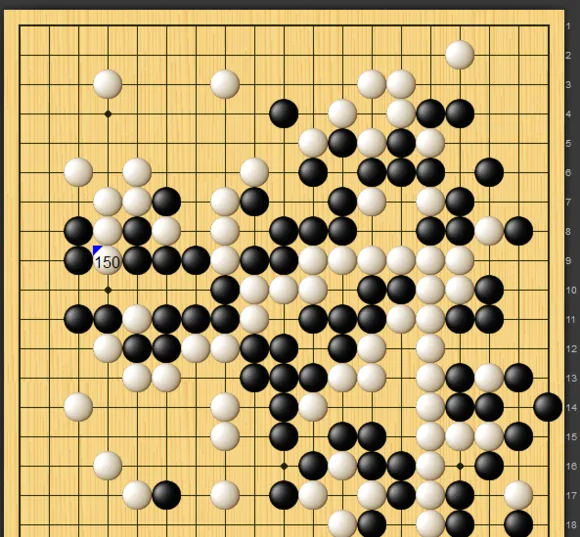 白棋的大龙从右下被黑棋紧盯着杀到中腹,最后竟然做不出两眼,郁郁而亡。其余几盘也均是以电脑大龙被杀告终。
白棋的大龙从右下被黑棋紧盯着杀到中腹,最后竟然做不出两眼,郁郁而亡。其余几盘也均是以电脑大龙被杀告终。
这是深度卷积网络的一个 BUG: 电脑对于局部的死活很敏感,但是对于大龙的死活不一定看得清。 最近我在训练网络时也发现,深度卷积网络 在此有一个"信息传递困难症"。这首先有两个原因:
第一,AlphaGo v13 的网络层数实际是不够的。如果按照 AlphaGo v13 的架构,5x5往上面长11层3x3,相当于27x27,看上去够大了吧? 错,这样的半径只有14。因此,如果大龙的长或宽超出14,那么它的尾就和头没有任何直接联系了 。实际上,卷积核 要至少长到37x37才保险,也就是16层3x3才够。
第二,由于网络的结构是往上一层层生长,如果只长几层,一般不会丢失重要信息,但如果一直长上去,就会越来越容易出现问题。所以,
大龙甚至都不用长到14,电脑就已经不一定"知道"自己的大龙是一条联通的大龙了。
举个与之相关的例子:按照 AlphaGo v13 的架构,如果大龙只在一端有两个真眼,另一端就甚至不一定知道自己已经活了(它只会知道自己有两口气,而这是网络输入告诉它的)...... 不可思议吧,我自己训练时看到这个现象也很惊讶,然后一想确实是这样。
以上这两个问题,电脑换成足够深的残差网络
或许就可以基本解决,不过意味着要重新训练。
但实际还有两个问题:
第三,如果仔细看网络本身输入的特征设计 ,会发现网络容易被带入一个误区: 它会倾向于认为气很多的棋块就是活的。 对于局部死活,这没有问题,但对于大龙死活,这是不足够的。 网络实际并没有清晰的眼位概念。
第四,这里的局面在人人对局中少见,在电脑自我对局中也会同样少见。关键在于,棋块小的时候,可能出现的形状不多,而且许多形状经常在对局中出现,因此容易被神经网络学会。而大龙越大,其可能出现的形状就越多,网络不一定能学会。事实上,目前的深度卷积网络并不擅长学会拓扑概念。 细长的大龙、分叉的大龙、卷曲的大龙,会尤其是它的弱点。棋手可以多尝试让电脑或自己的棋变成这样,电脑就会更容易看不清死活。
以上两个问题,电脑也可以通过有针对性的训练改善自己。具体效果如何,我们看「绝艺」上线后的表现。
顺便一提,如果读者对于 AlphaGo 与围棋 AI 感兴趣,我正在写一个系列,其它几篇的传送门 :











