在強化學習模型中嘗試不同的策略對於開發最佳應用程式至關重要,然而,資源的占地可能會對系統的能耗產生重大影響,從而引發對計算效率的再度思考。
深度學習的高昂成本
有沒有因為空調太冷而穿上毛衣? 在去睡覺之前忘了關掉另一個房間的燈?雖然在辦公室所做的一切都可以透過筆記電腦在家裏完成,但是你每天依然會花費半個多小時的通勤時間去上班,目的只是為了 「填補辦公室的座位」?
在強化學習中,透過樣本和計算效率之間的反直覺權衡,選擇正確的前進演化策略可能比看起來更為有效。
現代生活充斥了各式各樣的效率低下,然而深度學習的能源成本並不是那麽顯而易見。 在辦公桌上搭建一個高功率的工作站,冷卻風扇吹出的熱氣流不斷地提醒人們正在持續耗費大量的能量。 但是,如果把工作推播給大廳下面的共享集群,那麽要直觀地感覺到設計決策對電費的影響程度,便顯得有點困難了。 如果在大型的專案中用到了雲端運算,那麽能源的使用量和隨之而來的後果就會離你關註的物件漸行漸遠。 但是,看不見、摸不著並不是一個專案可行的決策,在碩大規模的極端情況下,可能意味著這些專案的能源支出要比汽車的整個產品周期內的能耗更大。
訓練深度學習模型的能耗需求
Strubell 等人關註了2019年訓練現代深度學習模型的實質效能源需求,他們主要針對一種稱為transformer的大型自然語言處理模型,其論文中考慮到的因素和討論得出的結論,與在類似硬件上訓練深度學習模型占用的時間基本一致。
他們估計:利用scratch訓練具備大量變量的Vaswani transformer,釋放出二氧化碳的量,大約為從紐約飛往舊金山航班釋放出二氧化碳的量的10%。這個預估值在主要雲提供商公布的能耗假設基礎上得出,且財務成本小於1000美元(雲端運算的假設)。 對於商業專案來說,可能這是一個劃算的支出,但是如果把最佳化和實驗等因素一並考慮進來之後,能耗賬單便輕易地乘以10或更大的系數了。
Strubell和他的同事估計,在NLP模型開發中添加神經架構搜尋(NAS)會增加數百萬美元的價格成本,及與之對應的碳足跡。 雖然許多大型的模型利用了專用硬件,如谷歌的TPU,進行訓練,從而將能源成本降至30~ 80倍,使得訓練價格略為降低,但這仍然是一筆巨大的支出。 在本文所關註的強化學習領域,效率低下的訓練的後果可能會使一個專案、產品或業務胎死腹中。
使用星際爭霸II(Starcraft II)的DeepMind訓練範例
在過去的44天時間裏,經過Deepmind訓練的代理,在多人即時策略遊戲星際爭霸II(Starcraft II)中,三場可玩的比賽中都達到了大師的地位,http:// Battle.net 排名擊敗了99.8%的所有玩家。 OpenAI的主要遊戲大師專案Dota2進行了10個月(約800個petaflop/天)的實戰訓練,目的是為了擊敗人類玩家的世界冠軍。
由於采用了TPU、虛擬工人等技術,要準確地估計這類遊戲玩家的能耗成本的確有難度。訓練出Alphastar和OpenAI Five的冠軍,估計大約需要有1200萬至1800萬美元的雲端運算成本。 顯然,對於一個典型的學術或行業機器學習團隊來說,這是遙不可及的。 在強化學習領域,低效的學習會引發另一個危險:一個探索性和樣本效率低下的中等復雜程度的強化學習任務,可能永遠找不到可行的解決方案。
利用強化學習(NL)預測蛋白質結構
在這裏,選取一個中等復雜程度的強化學習任務作為例子:從序列中預測蛋白質結構。一個由100個胺基酸連線在一起的小蛋白質,就像一條有100個連結的鏈,每個連結是21種獨特的連結變體中的一種,根據每個連結之間的角度依次形成結構。 假設每個胺基酸/鏈環之間的鍵角有9種可能的簡化構型,則需要

次叠代以檢視每個可能的結構。 這100個連結蛋白大致類似於一個強化學習環境,每個步長由100個時間步長和9個可能的動作組成,它們組合呈爆炸態勢。
當然,強化學習代理不會隨機抽取所有可能的遊戲狀態。 相反,代理將透過進行最佳猜測、定向探索和隨機搜尋的組合來生成學習軌跡。這種生成經驗的方法,稱之為典型的「on-policy」學習演算法。 對能找到局部最優方法的代理來說,可能會永遠停留在那裏,重復相同的錯誤,永遠解決不了整個問題。
從歷史上看,強化學習盡可能地將問題表述為類似監督學習的問題,並從中獲益,例如讓學生帶著三個綁在頭上網絡攝影機徒步旅行,左邊的網絡攝影機生成一個帶有訓練標簽 「右轉」的影像,而右邊的網絡攝影機被標記為「左轉」,中間的網絡攝影機標簽為 「筆直前行」。
最後,將獲得一個帶標記的數據集,適合於訓練導航森林小徑(quadcopter to navigate forest trails)。 在下面的章節中,我們將討論類似的概念(例如,模仿學習)和基於模型的RL如何能夠大大減少代理學習任務所需的訓練範例的數量,以及為什麽這並不總是一件有益的事。
事半功倍:讓強化學習代理從範例中學到最好的東西
深度強化學習是機器學習的一個分支,它受到動物和人類認知、最優控制和深度學習等多個領域的啟發。 有一個明顯的類似動物行為的實驗,其中動物(代理)被放置在一個特定情形之下:它必須學會透過解決一個問題來獲得食物 (獎勵)。 在動物開始將一系列動作與食物獎勵相關聯之前,只需要舉出幾個類似的範例,然而,為了實作代理參數的穩定更新,對於每個epoch,深度強化學習演算法可能需要考慮10到10萬個時間步長。
大多數強化學習環境都是按步長制定的。 環境會生成一個觀察,在此基礎上,由代理來決定套用於環境的動作。 環境根據其當前狀態和代理選擇的操作進行更新,在本文中將其稱為時間步長。 學習所需的時間步長或「樣本」越少,演算法的效率就越高。
大多數現代強化學習演算法的重要程度取決於其核心,這是一種試錯的形式。 對於一個未使用明確的探索技術得學習代理,其隨機活動偶爾也會做出一些正確的事情(random activity should occasionally do something right),否則,如果沒有得到積極獎勵的話,這個代理可能會與環境(本質上)永遠互動下去。 事實上,近端策略最佳化是一種在一系列基準中實作競爭效能的演算法,在OpenAI的程式生成的環境套件中,在硬探索模式下完全失敗。可以想象,對於廣泛的相關任務來說,這將是一個問題。
學習玩電子遊戲的代理可能會經歷一個積極的獎勵與隨機行動(又叫按鈕砸),這是便是Atari套件是受歡迎的強化學習基準的原因。 對於更為復雜的任務,比如:如何打一個復雜的結,機器人不太可能偶爾找出解決方案。 無論允許多少次隨機互動,達到預期的結果的可能性都不會很大。
正如以前在學習魔術方塊操作的討論中所看到的,透過手動編程打繩結的自訂綁結機器人,從scratch開始學習這樣做的強化學習代理仍然無法實作。 不言而喻,人類也不會透過scratch學習打結。 如果將一個蹣跚學步的孩子獨自留在滿是解開運動鞋的房間裏,他自己很難打出標準的「兔子」結(「bunny rabbit」 knot)。與思維實驗中的蹣跚學步的孩子一樣,強化學習代理可以從範例中更好地學習,以便完成諸如打結這樣的復雜任務。
利用強化學習教機器打結例項
透過將物理繩索的自主學習與真人演示相結合,柏克萊的研究人員解決了教機器打結的問題。 首先,這一部份可以模擬:機器人與桌面上繩子的隨機互動,目的是為了了解它們是如何工作的,從而學習出一個合理的模型。在代理的自主學習周期裏,顯示出了想要的動作:打一個簡單的結。在不出錯的情況下,代理能夠模擬所需的動作。 自主學習世界動力學模型(在上面的例子中,一個帶有繩子的台面)和人類要做的動作緊密結合。 模仿學習和相關的逆強化學習代表了一些最符合樣本效率的RL方法。
綁結是一項比較深奧的任務(顯然超出了許多學習演算法的能力),但我們可以透過它,來對不同學習演算法套用於更多標準任務的樣本效率進行比較。在謝爾蓋.萊文柏克萊的深層RL課程第21課,第29頁投影片中,透過對比公開發表的HalfCheetah 任務的結論,給出了各種RL演算法的相對樣本效率。alfCheetah是一個2D運動任務,用機器人模糊地模擬貓的動作。HalfCheetah可以在Mujoco(需要付費特許)和Bullet(開源,免費)物理模擬器中實作。
根據投影片的內容,我們期望總時間步長對應的前進演化策略的樣本失效率最低,基於模型/逆向強化學習的效率最高。 下面轉載了投影片中的估值,以及文獻中的具體範例。

HalfCheetah機器人在Py Bullet中仿真,目標盡可能快地前行。 雖然是在3D中呈現,但運動被限制在2D平面上。 就像獵豹一樣。
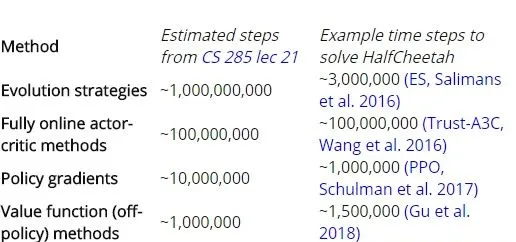
表1:各種RL演算法的相對樣本效率。
樣本效率在同一類演算法中的實作之間有很大的差異,我發現投影片中的估值相對於文獻中的特定範例來說可能有些誇大。 特別是,OpenAI的前進演化策略論文提出了一種比TRPO具備更高的樣本效率的方法,即一種策略梯度方法,用它來與TRPO作比較。報告稱: HalfCheetah 的解決方案花費了300萬個時間步長,遠遠低於Levine的10億個步長的估值。
此外,UberA I實驗室發表的一篇相關論文,將遺傳演算法套用於Atari遊戲,其樣本效率約為10億個時間步長,約為Levine課程估值的5倍。
在某些情況下,多即為少——從前進演化中學習
在上面討論的範例中,前進演化策略是樣本效率最低的方法之一,通常需要比其他方法至少多出10倍的步長來學習給定的任務。另一個極端情況是,基於模型方法和模仿方法則需要最少的時間步長來學習相同的任務。
乍一看,它似乎是與基於前進演化的方法相反的案例,但當你對計算進行最佳化而不是對樣本效率進行最佳化時,會發生一件有趣的事情。 由於執行前進演化策略的開銷減少,甚至不需要反向傳播通行證,實際上它們需要較少的計算,從本質上來看,計算也是平行的。 由於群中的每一episode或單個代理不依賴於其他代理/節點的結果,因此學習演算法變得相對並列。 有了高速的仿真器,它可以在更短的時間內(根據墻壁上的時鐘來測量)解決給定的問題。
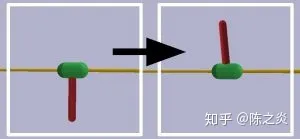
InvertedPendulumSwingup任務的起始狀態和目標狀態。 綠色膠囊沿著黃色桿滑動,目的是使紅色桿平衡直立。
為了對計算效率進行粗略的比較,我在PyBullet中對推車式擺動任務(cart-pole swing-up task )倒置擺擺子BulletEnv-v0上執行了幾個不同學習演算法的開源實作。 具有代表性的前進演化演算法和共變異數矩陣自適應的原始碼,可在Github上找到,而其他演算法都是OpenAI的深度RL資源的一部份。
策略體系結構均保持不變:一個前饋密集的神經網絡,共16個神經元,每個神經元有兩個隱藏層。 我在一個單核Inteli5,2.4GHz CPU上執行全部演算法,可以得到對比結果:在沒有任何並列化加速情況下,訓練時間存在差異。 值得註意的是,OpenAI在10分鐘內利用前進演化策略對1,440名工人進行了MujoCo類人訓練,得出如下結論:如果具備並列CPU核,並列能真正實作提速,的確有利可圖。

表2:不同的學習方法的wall-clock時間和樣本效率對比表
上表很好地說明了不同演算法所需資源之間的相對關系:樣本效率最高的演算法(soft actor-critic)需要大約一半的步長,但消耗了34倍的CPU時間。 雙延遲DDPG(又稱TD3)和soft actor-critic演算法的穩定性低於其他演算法。
由於缺乏開源工具,在執行表2中的實驗時沒有考慮基於模型的RL演算法。 對基於模型的RL的進一步研究受到封閉源開發和缺乏標準環境的影響,但許多科學家為基於模型的RL演算法標準化做出了不懈的努力。 他們發現,大多數基於模型的RL方法能夠在大約25,000個步長中解決 「鐘擺」的任務,與上表中報告的策略梯度方法(policy gradient methods)類似,但是,訓練時長卻是策略梯度方法(policy gradient methods)方法的100到200倍。
雖然深度學習似乎仍然傾向於「花哨」的強化學習方法,但基於前進演化的方法一直在卷土重來。 OpenAI的「前進演化策略是強化學習的一個可延伸的替代」自 2016年起,參與了2017年的大規模演示遺傳演算法:學玩Atari遊戲。 在沒有高級RL演算法的花哨的數學裝飾情況下,前進演化演算法的概念十分簡單:建立一個人群並為群中每個人設定某些任務,最好的玩家可以成為下一代種子,迴圈重復,直到滿足效能閾值。 由於它們背後的一些簡單的概念和它們固有的並列化潛力,可以發現前進演化演算法將是您最稀缺的資源:可以大量節省開發人員時間。
對計算和樣本效率需要了解的幾點附加說明

在單個任務上,不同RL演算法之間的計算和樣本效率的直接比較並不完全公平,因為實作起來可能存在許多不同的變量。 一種演算法可能收斂得更早,但卻達不到其它、較慢的演算法相同的分數,在通常情況下,我可以和你打個賭,在任何已發表的RL專案中,作者花費了比任何其它演算法更多的精力來最佳化和實驗他們的新方法。
透過上文討論的例子,對於從強化學習代理中期望獲得什麽這一問題,給出了一個很好的答案。 基於模型的方法雖然很有前途,但與其他選項相比並不成熟,不值得為之付出額外的努力。或許,神奇的是:前進演化演算法在各種任務上都表現得很好,不應該被忽視,即便它們被認為是「過時的」或「太簡單」。當考慮到所有可用資源的價值及其消耗時,前進演化演算法的確可以提供最好的回報。









