开篇
今天的文章还是由一个我亲身经历的故事来开篇。在一次面试中,面试官问我怎么处理「新用户冷启动」的问题,当时,我是从算法的角度来回答的,比如通过online learning,加快线上模型的更新频率;再比如,我当时想把PinSAGE由item-2-item升级为user-2-item,这样只要新用户点击过一个item A,我就可以将A的信息、点击过A的其他user的信息、点击过A的其他用户点击过的item信息、......都聚合到新用户身上。巴拉巴拉讲了一堆,面试官显得不是很满意,只见他大手一挥,中气十足地说到:「没那么复杂,处理新用户,归根结底就一句话,
尽可能多地找这个用户的数据!!!
」。当时我还是有点小受震撼的,感叹道,面试官一眼看到问题本质,怪不得是人家面试我呢。于是,我立刻切换到产品思路,比如构建产品矩阵,从其他产品了解用户;通过弹窗问卷的方式,收集用户的兴趣爱好;......,这下面试官方才满意,于是面试愉快地进行下去。
现在回过头来,重新思考「新用户冷启」这个问题。毫无疑问,针对我们所知甚少的新用户做推荐,是一个极其困难的问题,尽一切努力收集用户信息,也绝对是top priority。但是,因此我们算法就无事可做,等着产品和前端同学把新用户的数据送过来?
根据我近年来的经验,新用户的数据是极其重要的,但是并非问题的全部。比如,新老用户在app中的行为模式有很大不同(e.g., 比如一些产品设计不允许新用户做点赞、评论等动作)。但是,在训练的时候,老用户的样本在数量级上碾压新用户的样本(本来dau就主要是由老用户贡献,再加上一个老用户能够贡献多条样本),导致
模型主要拟合老用户的行为模式,忽略了新用户
。在这种情况下,增加几个对新用户友好的特征(比如年龄、性别等),因为主导模型的老用户不care(影响老用户推荐结果的主要是其过去历史,而非人口属性),加了也是白加。
噢,看似是一个样本不均衡的问题,也不是毫无办法。比如:
给新用户的样本加权
。行是行,但是有两个问题不太好解决,一是如何设定给这些新用户的权重,二是,毕竟老用户才是给我们贡献KPI的主力,给新用户加权,等于变相削弱老用户,可能得不偿失。
干脆分家,就只拿新用户的数据单独训练一套模型,只服务新用户
。也不是不行。但是,也有两问题不好解决,一是新用户数据量少,底层embedding和中间的dense weight可能训练不好;二来,单独训练,单独部署,有点浪费资源。
对付新用户,以上方法虽然简单,但是真的不妨一试。如果也觉得以上方法的缺点无法接受,不妨向下读,看看本文替你总结出的一些从算法层面助力新用户冷启的技巧。
正文开始之前,先提前声明几点:
本文中所提及的新用户是一个泛称,未必是第一次登录、毫无动作的纯新用户,也包括那些虽然距首次登录已经过去许久,但是鲜有活动的用户。其实,文中的概念算是「低活用户」,但是为了行文方便,下文中还是用「新用户」统一称呼这些用户;
本文中所提观点,和「
收集用户信息是新用户冷启top priority
」的观点并不矛盾。相反,以下算法技巧的目的,就是为了能够让模型更重视那些对新用户友好的特征,让这些特征真正发挥作用。
算法毕竟是实验科学,就像股票点评之后总要加上一句「不构成投资建议」一样,以下介绍的技巧未必颗颗是银弹。究竟哪个管用,就让GPU和AB平台告诉我们答案吧。
加强重要区分性特征
既然我们通过数据分析,先验已知新老用户的行为模式有着较大差异,我们希望把这一先验知识告诉模型,让模型对新老用户能够区别对待。至于如何注入这样的先验知识,我已经在我的另一篇文章【
先入为主:将先验知识注入推荐模型
】介绍过了,简述如下。
首先,我们要构造能够显著标识新用户的特征,比如:
一个标识当前用户是否是新用户的0/1标志位
用户是否登录
首次登录距今时间
交互过的item的个数
......
强bias特征加得浅
可以把这些强bias特征加得离final logit近一些,让它们对最终loss的影响更直接一些。比如:Logit_{final}=Logit_{ordinary} + Logit_{bias}
由其他特征获得Logit_{ordinary},
需要经过复杂且深的DNN结构
而由以上强bias特征贡献的Logit_{bias}
,只是将这些强bias特征通过一个LR或一层fully connection就得到
强bias特征当裁判
方法二,将这些强bias的特征,喂入SENet或或LHUC(Learn Hidden Unit Contribution,如下图所示),用来决定其他特征的重要性
 强bias特征作为LHUC的输入,经过sigmiod激活函数后,输出是一个N维度向量,N是所有fileld的个数
N维向量就是各field的重要性,将其按位乘到各field的embedding上,起到增强或削弱的作用。比如:
比如产品设计不允许未登录用户点赞、评论,那么新用户样本中的相关特征的重要性「应该」为0
用户点击哪个站外广告被引入app,这个信息只对新用户有用(权重应该大),对老用户意义就不大了(权重应该小)
加权后的各field embedding再拼接起来,喂入上层DNN
强bias特征作为LHUC的输入,经过sigmiod激活函数后,输出是一个N维度向量,N是所有fileld的个数
N维向量就是各field的重要性,将其按位乘到各field的embedding上,起到增强或削弱的作用。比如:
比如产品设计不允许未登录用户点赞、评论,那么新用户样本中的相关特征的重要性「应该」为0
用户点击哪个站外广告被引入app,这个信息只对新用户有用(权重应该大),对老用户意义就不大了(权重应该小)
加权后的各field embedding再拼接起来,喂入上层DNN
这样做,相比于将所有特征「一视同仁」、一古脑地喂入DNN最底层等候上层DNN筛选,更能发挥那些对新用户友好的重要特征的作用。
借鉴多领域学习
正如开篇所说,
为了避免新用户数据被老用户淹没,干脆分家,用新用户的数据单独训练一个模型只服务新用户
。但是有两个问题不好解决,一是新用户数据少,单独训模型可能训不好;二是,单独训练+部署,有点浪费资源。
其实这个问题属于
multi-domain learning
的解决范畴。不要和multi-task learning相混淆,multi-domain learning研究的是如何将多个相关渠道的数据放在一起训练,而能够相互促进,而非相互干扰。这方面的工作并不多,让我们看看阿里近年来在这一领域发表的两篇文章。
提醒读者,尽管两篇文章的初衷都不是针对新用户,但是在阅读过程中,我们可以代入new user domain vs. old user domain的场景
。
STAR结构
一篇是【One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction】。这篇文章研究的是,如何训练并部署一个模型,就能胜任「首页推荐」、「猜你喜欢」等多个领域。前两个改进也很「直觉」(嘿嘿,知道我模仿的是谁吗?)
每个域学习各自的batch normalization
 \gamma
, \beta
是要全局学习的scaling和bias
\gamma_p
, \beta_p
是某个domain "p"独有的scaling和bias
将domani id这样的bias特征,通过一个浅层网络,加得离final logit近一些。这一点就是我们在上一章节介绍的技巧。
\gamma
, \beta
是要全局学习的scaling和bias
\gamma_p
, \beta_p
是某个domain "p"独有的scaling和bias
将domani id这样的bias特征,通过一个浅层网络,加得离final logit近一些。这一点就是我们在上一章节介绍的技巧。
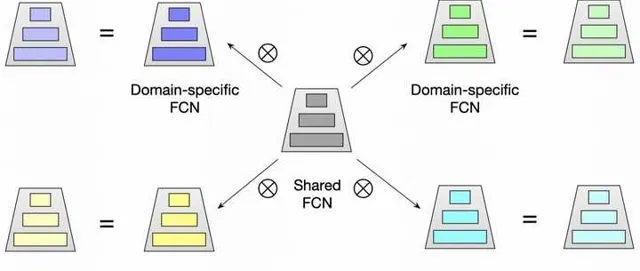
第三个改进,就是所谓的星型拓扑结构,也就是论文标题的来源。简单来说,
就是每个domain要经过的final dense weight是domain specific part和shared part融合而成
。
 W_p^*
是domain 'p'的样本最终要经过的final weight,
W_p^*
是domain 'p'的样本最终要经过的final weight,

W_p
是domain "p"独有的weight,只让domain "p"的样本参与迭代更新
W是shared weight,所有domain的数据都要参与更新。
\otimes
是element-wise multiplication
我有点不太好评价这种结构。其实想结合domain specific information与shared information也不算什么新概念,比如下面两种:
domain specific weight与shared weight是并联的关系,样本信息同时经过domain specific weight和shared weight向上传递,Logit_{final}=Logit_{domain}+Logit_{share}
模仿早先multi-task learning中常见的share bottom结构,先有共享的底层shared weight,各个domain再在上面串联上domain specific weight。预测时,样本先经过shared weight,再经过domain specific weight向上传递,Logit_{final} = F_{domain}(F_{share}(x))
文中并没有给出W_p \otimes W
这种融合方式,相对于我在上文提出的两种融合方式的优势,或许没啥大道理,又是实验得出的结论。我自己给出的理由只能是:
无论是domain specific weight与shared weight是并联还是串联,前代回代中,信息所经过的每一层,都只属于单一通道(要么是domain specific,要么是share),融合得并不彻底;
而W_p \otimes W
,信息流过的每一层都是domain specific weight和shared weight融合后的,融合得更充分。
HMoE结构
AliExpress的文章【Improving Multi-Scenario Learning to Rank in E-commerce by Exploiting Task Relationships in the Label Space】聚焦于多国家场景下的推荐。这个场景,和我们新用户的场景更加类似一些,多个国家的人口迥异,市场进入有早有晚,相对于先发国家庞大的用户基数和丰富的行为,
后发国家的用户少、行为少,可以类比于「新用户冷启」的场景
。
这篇文章提出的HMoE与STAR完全相反,没有所谓的shared weight。其原理假设是:
A国家中,有些用户a的行为和B国的用户很像,所以,让B国的DNN给a打分也很靠谱,异域模型打分的借鉴意义大;反之,异域模型打分的借鉴意义小。
回到我们新用户的场景下,
用老用户模型给新用户打分,可能对部分新用户也是大有裨益的
。
具体做法上:
无论哪个域的样本,都要经过所有domain的DNN打分(下面公式中的S),
最终得分,是在各个域打分上的加权平均。权重(下面公式中的W)由一个gate netowrk根据输入样本,个性化决定。
 训练时,
domain=t的样本,只能更新自己的DNN_t
,对其他domain的DNN都要stop gradient
。这一点也相当直觉,毕竟其他domain的DNN帮domain t打分是副业,不能强求其他domain的DNN为domain t上的loss负责。
训练时,
domain=t的样本,只能更新自己的DNN_t
,对其他domain的DNN都要stop gradient
。这一点也相当直觉,毕竟其他domain的DNN帮domain t打分是副业,不能强求其他domain的DNN为domain t上的loss负责。

获得对新用户友好的初值
这种方法的思路是,新用户训练困难是因为数据少。但是,
如果新用户的初始值并非随机,而是已经非常靠谱了,通过少量数据+几次迭代,就能收敛到不错的用户表示
,岂不妙哉!
强烈吐槽MeLU
上述思路简直就是为
MAML
(Model-Agnostic Meta-Learning)量身定做的。MAML主打的招牌就是Fast Adaptation
先通过多个task的学习,将参数学习到一个不错的状态\theta
;
有了新任务1(or 2 or 3),该新任务只需要提供少量数据,就能够从\theta
出发,快速收敛到这个新任务的最优参数\theta_1^*
(or \theta_2^*
or \theta_3^*
)

于是基于MAML,韩国人提出了MeLU想学习出对新用户友好的初始值。文章的细节,我就不多说了,因为如果基础错了,剩下的实现细节也就毫无价值,浪费笔墨罢了。
我就问两个问题:
注意上图中的\theta_1^*
、 \theta_2^*
、\theta_3^*
是从\theta
派生出三组完全不同的参数。而MeLU中的task粒度是每个用户算一个task。这也就意味着,哪怕\theta
真有fast adapation的能力,
来了N个新用户,就要衍生出N组不同的参数
?!想想在一个真实的推荐系统中,\theta
要包括所有dense weight和一些能够跨user共享的embedding(e.g., tag embedding之类的),参数量还是不小的,
而MeLU竟然要为每个新用户都学习出单独的一套出来???!!!
新用户训练和预测的难点就在于,他的一些特征是之前从来就没出现过的。比如一个用户最具个性化的特征就是user id embedding,新用户的user id embedding压根就不会在\theta
中出现,
\theta
adapt to nowhere !!!
我也就纳闷了,
这种脱离推荐系统实际、毫无实战价值的文章,是怎么被KDD录入的?还被那么多讲新用户冷启的文章引用!简直是误人子弟!!!
用Group Embedding代替新用户的Id Embedding
介绍一种我自己设计的方法,用来获取良好的new user id embedding初值,在一些场景下的效果还不错。
我的方法的前提假设是:
user id embedding是最具个性化的特征输入,在老用户推荐中发挥了极其重要的作用,DNN也非常重视这个特征(e.g., 接在user id embedding上方的weight比较大)。
但是问题就在于,由于新用户的user id embedding出现次数少,经过有限次训练,
new user id embedding还离最初随机初始化的结果不远
;而在预测的时候,由于PS有特征准入规则,新用户的id embedding压根就没有被PS收录,
导致inference server向PS请求该新用户的id embedding时返回一个全0向量
,导致DNN所期待的重磅特征user id embedding落了空。
既然user id embedding那么重要,而
新用户的user id embedding质量却那么差(训练时得到的随机向量,预测时得到的是全0向量)
,那么能不能找到一个替代方案?这时,Airbnb的经典文章【Real-time Personalization using Embeddings for Search Ranking at Airbnb】给我提供了一种思路。在Airbnb的实践中,由于booking这个行为太稀疏,所以绝大多数用户都是「新用户」,而Airbnb的思路就是根据规则将用户划分为若干用户组(比如,
「讲英语,使用苹果手机」的用户群,和「讲西班牙语,使用Android手机」的用户群
),然后
用user group embedding代替单独的user id embedding参与后续训练与预测
。

基于以上假设,解决思路是:
将user id embedding(无论新老用户)拆解成E_{uid} = E_{InitGroup} + E_{PersonalResidual}
E_{InitGroup}
是「初始的用户群」的embedding。
注意这个分群是「初始用户群」,划分时,只能依靠那些对新用户友好的特征
,比如:年龄、性别、安装那些(种类)的app,是被哪个(类)广告拉新进来的、......
E_{PersonalResidual}
代表自用户进入app之后,随着在app内部行为越来越丰富,他距离当初「初始用户群」embedding的个性化残差
对于老用户,原来的方法是直接学习每人各自的user id embedding,现在是改学E_{PersonalResidual}
,所有个性化信息都包含在这个个性化残差里了。
对于新用户
训练时,尽管一开始E_{PersonalResidual}
还是随机向量,但是
毕竟是在已经训练好的E_{InitGroup}
周围
(怎么训练,下面会讲),对于上层的DNN来说,也算是一个不错的初始值
预测时,inference server遇到纯新用户,由于未收录该新用户的E_{PersonalResidual}
从而返回全0向量,结果从DNN的角度来看,
E_{uid} = E_{InitGroup}
。也就是,新用户的user id embedding被用户群embedding代替
,强于之前模型用全0向量填充的方法。
目前还遗留一个问题,就是E_{InitGroup}
怎么得到?我的方法是采用
预训练
的方法
如上所述,分群是「初始用户群」,划分时,只能依靠那些对新用户友好的特征,比如:年龄、性别、安装那些(种类)的app,是被哪个(类)广告拉新进来的、......
借鉴Airbnb的方法,用类似word2vec的方法获得各E_{InitGroup}
,具体来说,
正样本:某个新用户的E_{InitGroup}
,与其交互过的item embedding,在向量空间上应该足够近
负样本:随机采样一些item embedding
注意,在我的实践中,进行以上预训练,
只采用新用户的数据,不用老用户的数据
。
这么做是因为,老用户交互的item,主要是由推荐系统根据用户历史推荐出去的,和用户的初始元信息(比如,年龄、性别、App等)关系已经不大了。引入老用户数据,反而引入了噪声
预训练完毕,将各init user group embedding保存起来
注意,在正式训练的时候,
E_{InitGroup}
对于老用户要stop gradient
,毕竟年代久远,init user group embedding不应该再为老用户推荐结果上的loss负责。也防止规模巨大的老用户数据,将已经训练好的E_{InitGroup}
带偏
至于新用户,最好对E_{InitGroup}
也stop gradient
,一来新老用户一致,方便实现;二来,我们希望信息都积累在E_{PersonalResidual}
上,而不是在group embedding上。
最后提一下,既然要利用new user friendly feature分群,再用user group embedding代替新用户的user id embedding,那为什么不直接将这些特征接入DNN,直接让DNN学习不就完了,何必这么麻烦?如果有小伙伴能够想到这一层,首先要为你自己的独立思考能力点赞。
问题的关键还是这些new user friendly feature的接入位置
:
就像我在开篇中所说,直接将new user friendly feature接入DNN底层,很可能起不到提升的作用。还是因为老用户数据已经主导了模型,模型对新用户特征压根不重视(e.g., 接在这些特征的weight都很小)。
但是模型是非常重视user id embedding这个特征的(e.g., 接在它上面的weight都很大),因此
只有将user group embedding接在user id embedding相同的位置,才能真正发挥作用
。
总结
本文聚集于新用户冷启这一让推荐算法工程师头疼的问题,从以下几个方面总结了我个人的看法与经验:
对于新用户冷启,top priority肯定还是尽力收集用户的数据。
但是仅靠收集数据也是不够的。比如:在一个成熟的app中,老用户的样本碾压新用户样本,主导了模型。徒增了几个new user friendly的特征,模型也不会重视。
因此,也还需要一些算法上的技巧,让收集到的新用户信息,能够真正发挥作用。
技巧1:要把new user friendly特征加到合适的位置,比如加得离loss更近一些,再比如作为gate的输入,衡量其他特征的重要性。
技巧2:将新老用户看成两个domain,借鉴multi-domain learning的经验,让老用户模型能够助力新用户,又不至于过分主导。
技巧3:新用户的初值非常重要。先吐槽了MeLU这种毫无实战价值、误人子弟的文章;接着介绍了我自己设计的用user group embedding代替user id embedding的算法,帮大家打开思路。
本人的其他文章,感兴趣的小伙伴可以继续阅读:
负样本为王:评Facebook的向量化召回算法
无中生有:论推荐算法中的Embedding思想
万变不离其宗:用统一框架理解向量化召回
先入为主:将先验知识注入推荐模型
久别重逢话双塔
少数派报告:谈推荐场景下的对比学习
刀功:谈推荐系统特征工程中的几个高级技巧
- END -











