JUST團隊-隋遠
一、問題背景
近些年,網購已經成為人們一種重要的生活方式。據中國互聯網路資訊中心第45次中國互聯網路發展狀況統計報告顯示,截止到2020年3月,中國網民規模為9.04億,互聯網普及率達64.5%,網路購物使用者規模達7.1億,2020年網路購物交易規模達11.76萬億元 [1] 。618和雙十一這種購物狂歡節,更是各大電商的必爭之地,如何透過有趣的套用吸引使用者並成功引流成為每個電商平台這一階段的重要任務。在此背景下,希望有一款基於訂單數據的APP,可以讓使用者快速檢視附近人的商品購買排行,以及自己在其中的購買力排名,這對於區域經濟分析來說很重要,也能夠有很大的趣味性。由於每個訂單數據都帶有空間位置資訊,如:GPS報點資訊或地名地址資訊。同時,訂單又天然包含下單時間。因此訂單數據的分析是典型的時空資料探勘問題。那麽,如何快速地在數以億計的訂單數據中找到空間鄰近、時間也鄰近的訂單數據,同時保障C端使用者高並行的操作是此套用要解決的關鍵問題。
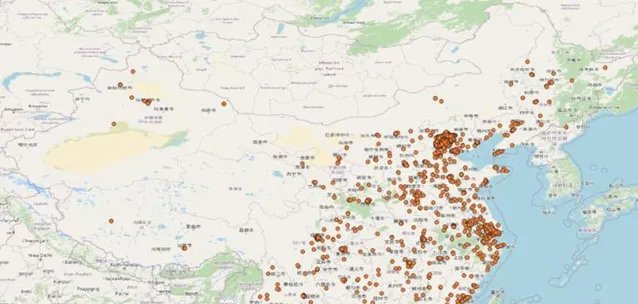
經過對數據的探查發現,全國的訂單數據分布很不均勻。比如:某個比較繁華的社群在近7天可能有幾萬個訂單數據,各種商品類目及畫像數據都很豐富,不同排名都可得到top10數據。但有些人口比較稀少的地區7天內可能只有幾個訂單,甚至沒有訂單,這樣會導致排名結果為空,影響使用者體驗。透過從歷史柯瑞對7天內的全國訂單進行隨機采樣,可以看到這種分布情況。如圖1北京及東部沿海地區的訂單量非常密集,中部地區相對較少,西部地區則非常稀少。
二、現有方案
針對上述場景,我們需要找到一種對時間和空間維度都能高效過濾的查詢方案,以保障使用者能快速獲取近期「附近」的購物數據。同時為了確保每次查詢返回的數據足夠進行分析排名,「附近」變成了一個可變的參數。能否合理的定義「附近」的大小也將影響產品的體驗。基於已有技術我們嘗試了如下兩種方案。
2.1基於關系型空間資料庫的KNN查詢方案
以最流行的開源空間資料庫PostGIS為例,需要進行兩個步驟。首先透過KNN查詢出給定位置周圍足夠數量的訂單(比如5000個)。這個過程可以稱為一級過濾。然後,對查詢結果進行時間過濾。將KNN查詢出的5000條數據根據時間欄位進行過濾,得到最近7天的最終訂單。這個過程可以稱為二次過濾。
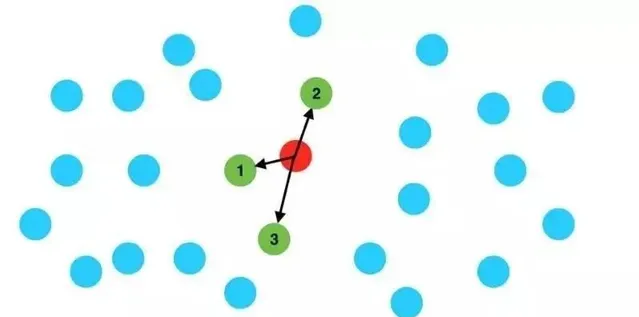
圖2KNN查詢示意圖
以上過程透過實踐分析後,發現存在兩個缺陷:
1、一次過濾是純空間過濾,得到的候選訂單極有可能並不在目標時間內。比如,我們透過KNN查詢得到了附近5000個訂單,這些訂單可能全部或大部份產生於7天前,這樣會導致我們二次過濾後剩下的結果非常少。當然,針對這種情況,有兩個改進方案。第一種,可以將一次過濾的K值放大,比如查詢50000個附近的訂單,這樣二次過濾剩余的數據量很可能會增加,但是,這種方案仍然不能保證一定能查詢到足夠的數據。同時,增加K值還會造成效能的降低。第二種方案,先進行時間過濾,再進行KNN。我們的訂單數據在7天內可能有上千萬或者更多數據,時間過濾後的結果,在記憶體中進行KNN會有非常大的效能開銷和效率問題。這種方案一級過濾的效果太差導致難以實作。
2、PostGIS作為關系型資料庫水平擴充套件性天生比較有限,雖然有pgpool和pg-xl這種外部元件支持集群模式。但是,每天千萬級數據量的寫入,還是會讓PostGIS有些力不從心。
2.2 基於分布式資料庫和時空索引的查詢方案
利用GeoMesa引擎,將訂單數據匯入之後,建立時空Z3索引,透過一步查詢即可實作時空過濾。但是,此方案存在比較明顯的缺陷,我們無法確定查詢的空間範圍。因為,GeoMesa的時空查詢必須指定查詢的空間與時間範圍。時間範圍可以預先設定比如最近7天,而空間範圍因為第一節講過每個區域的訂單分布極不均勻,如果使用固定的空間範圍,非常有可能出現兩種情況,第一是某些區域查詢到非常多的數據比如10w個訂單,這會導致回傳到客戶端的數據量很大,增加客戶端壓力,最終導致整體效能的下降;另一種情況是某些區域因為訂單量很少,導致無法獲取足夠的訂單。因此,固定空間範圍的方案是不可行的。
三、解決方案
我們的方案基於分布式時空引擎JUST [2] 來實作海量數據的儲存,並在此基礎上建立時空索引,與GeoMesa的Z3索引不同的是我們使用最佳化的Z2T索引 [3] 。另一方面,為了解決2.2節中無法固定空間範圍的問題,本方案透過動態統計的手段,建立每天全國範圍的查詢區域索引,每次使用者查詢會根據區域索引獲得合理的空間檢索範圍,保障最終查詢結果數據的合理性。
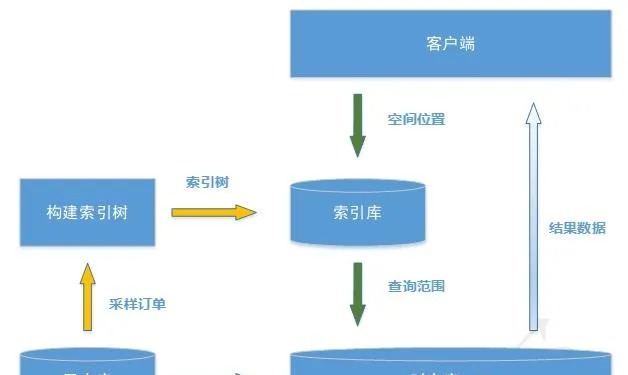
本方案分為兩個流程,索引建立流程和數據檢索流程。架構如圖4所示。其中黃色箭頭代表我們建立空間索引的數據流,綠色箭頭為查詢檢索數據流。
3.2.3 索引建立流程
索引的建立流程可以看成是原始數據的預處理過程。一般情況下,訂單數據是T+1模式,即每天淩晨匯入前一天的所有訂單數據,白天查詢到的數據是昨天及昨天以前的數據。我們的索引建立就是在數據匯入之後進行,整個過程如圖5所示。下面詳細介紹一下裏面幾個關鍵流程。
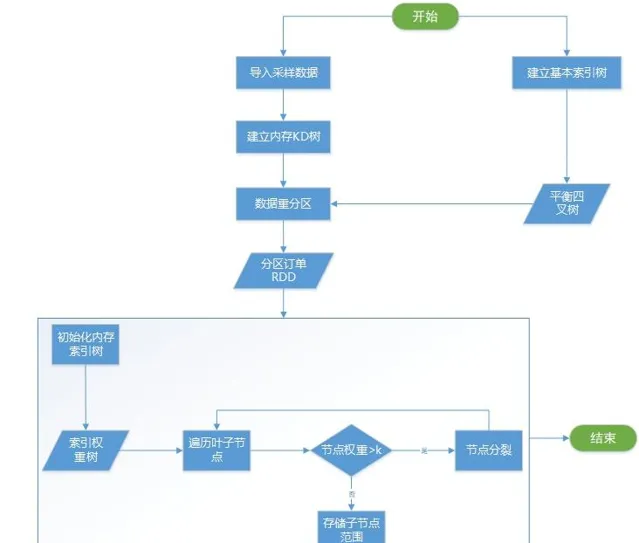
1、數據采樣並建立KD樹索引。
因為套用需求裏時間範圍固定為7天。因此,為了得到合理的索引樹,我們需要根據前7天數據的分布進行構建。但是,7天的數據量可以達到數億,全部放到記憶體計算會非常耗時。為了可以快速完成索引構建,同時避免過多損失精度。最終使用隨機抽樣1%作為輸入數據。獲取到所有抽樣訂單後,建立一棵記憶體KD樹,用於後面索引建立。
2、建立基礎索引樹。
所謂基礎索引樹,是一棵平衡四叉樹。它是我們記憶體範圍索引的構建基礎,他的最大最小級別可以配置,葉子節點的空間範圍是索引構建的初始範圍。假設初始級別為2,先把二級葉子節點全部建立好,並計算好每個葉子的空間範圍。
3、構建緩存索引。
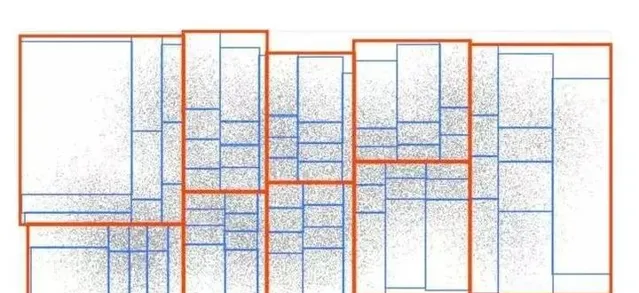
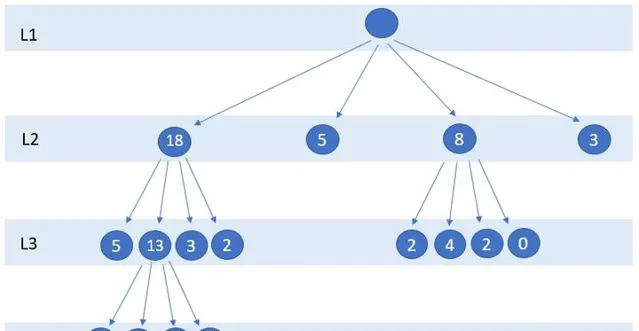
構建索引樹分為兩步;第一步,遍歷所有基礎索引樹的葉子節點,將葉子空間範圍作為查詢範圍搜尋KD樹獲得範圍內的訂單個數orderNum,如果訂單個數大於閾值k,則進行分裂,否則停止分裂。這一過程如圖6所示,假設k為5,所有大於5的節點會繼續分裂為4個子節點,直到不存在節點範圍內訂單數大於5為止。第二步,將索引樹儲存到Redis緩存中。
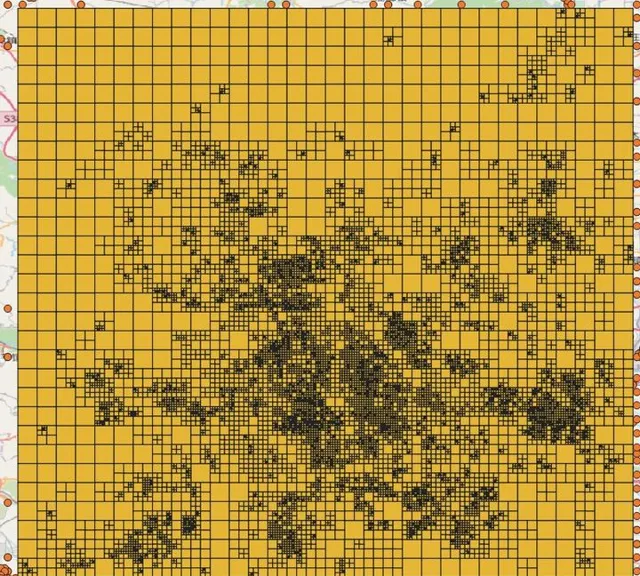
透過對某一天統計的北京地區索引樹進行視覺化分析如圖7,並將索引樹和訂單采樣數據進行分布疊加如圖8,可以看到我們的索引樹可以很好的模擬訂單分布情況。

3.2.3 數據檢索流程
數據檢索流程相對簡單,首先,從Redis內取出最新構建的索引樹,利用輸入的地理位置在構建好的索引樹中獲取到對應的葉子節點空間範圍。然後,利用搜尋範圍去JUST內進行空間查詢即可得到統計計算需要的訂單數據。
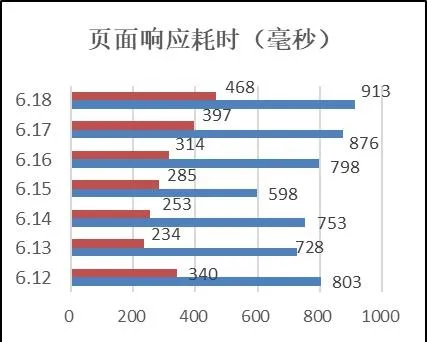
經過對一個星期的查詢進行統計如圖9,可以看到最長的查詢響應也在1秒內。
四、總結
本文介紹了一種基於JUST時空數據引擎的時空篩選方案。適用於基於訂單數據的時空鄰近查詢場景,既能保障查詢的效率,同時可以返回合理數量的數據供伺服端分析展示。除訂單數據外,基於這種時空鄰近查詢方案,還可以擴充套件出非常豐富的套用場景,比如:最近n天在附近發生的重大事件查詢,最近n小時,附近道路口車流量查詢等。
參考
- ^ [1] http://www.cac.gov.cn/2020-04/27/c_1589535470378587.htm
- ^ [2] http://just.urban-computing.cn
- ^ Li R , He H , Wang R , et al. JUST: JD Urban Spatio-Temporal Data Engine[C]// 2020IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020.











