Golang、Golang、Golang 真的夠浪,今天我們一起盤點一下Golang並行那些事兒,準確來說是goroutine,關於多執行緒並行,咱們暫時先放一放(主要是俺現在還不太會,不敢出來瞎搞)。關於golang優點如何,咱們也不扯那些虛的。反正都是大佬在說,俺只是個吃瓜群眾,偶爾打打醬油,逃~。
說到並行,等等一系列的概念就出來了,為了做個照顧一下自己的菜,順便復習一下
基礎概念
行程
行程的定義
行程(英語:process),是指電腦中已執行的程式。行程曾經是`分時系統的基本運作單位。在面向行程設計的系統(如早期的UNIX,Linux 2.4及更早的版本)中,行程是程式的基本執行實體;在面向執行緒設計的系統(如當代多數作業系統、Linux 2.6及更新的版本)中,行程本身不是基本執行單位,而是 執行緒 的容器。
程式本身只是指令、數據及其組織形式的描述,相當於一個名詞,行程才是程式(那些指令和數據)的真正執行例項,可以想像說是現在進行式。若幹行程有可能與同一個程式相關系,且每個行程皆可以同步或 異步 的方式獨立執行。現代 電腦系統 可在同一段時間內以行程的形式將多個程式載入到記憶體中,並借由時間共享(或稱 分時多工 ),以在一個 處理器 上表現出同時 平行性 執行的感覺。同樣的,使用多執行緒技術(多執行緒即每一個執行緒都代表一個行程內的一個獨立執行上下文)的作業系統或電腦體系結構,同樣程式的平行執行緒,可在多CPU主機或網路上真正 同時 執行(在不同的CPU上)。
行程的建立
作業系統需要有一種方式來建立行程。
以下4種主要事件會建立行程
- 系統初始化 (簡單可理解為關機後的開機)
- 正在執行的程式執行了建立行程的系統呼叫(例如:朋友發了一個網址,你點選後開啟瀏覽器進入網頁中)
- 使用者請求建立一個新行程(例如:開啟一個程式,開啟QQ、微信)
- 一個批次作業的初始化
行程的終止
行程在建立後,開始執行與處理相關任務。但並不會永恒存在,終究會完成或結束。那麽以下四種情況會發生行程的終止
- 正常結束(自願)
- 錯誤結束(自願)
- 崩潰結束(非自願)
- 被其他殺死(非自願)
正常結束:你結束瀏覽器,你點了一下它

錯誤結束:你此時正在津津有味的看著電視劇,突然程式內部發生bug,導致結束
崩潰結束:你程式崩潰了
被其他殺死:例如在windows上,使用工作管理員關閉行程
行程的狀態
- 執行態(實際占用CPU)
- 就緒態(可執行、但其他行程正在執行而暫停)
- 阻塞態(除非某種外部的時間發生,否則行程不能執行)
前兩種狀態在邏輯上是類似的。處於這兩種狀態的行程都可以執行,只是對於第二種狀態暫時沒有分配CPU,一旦分配到了CPU即可執行
第三種狀態與前兩種不同,處於該狀態的行程不能執行,即是CPU空閑也不行。
如有興趣,可進一步了解行程的實作、多行程設計模型
行程池
行程池技術的套用至少由以下兩部份組成:
資源行程
預先建立好的空閑行程,管理行程會把工作分發到空閑行程來處理。
管理行程
管理行程負責建立資源行程,把工作交給空閑資源行程處理,回收已經處理完工作的資源行程。
資源行程跟管理行程的概念很好理解,管理行程如何有效的管理資源行程,分配任務給資源行程,回收空閑資源行程,管理行程要有效的管理資源行程,那麽管理行程跟資源行程間必然需要互動,透過IPC,訊號,號誌,訊息佇列,管道等進行互動。
行程池:準確來說它並不實際存在於我們的作業系統中,而是IPC,訊號,號誌,訊息佇列,管道等對多行程進行管理,從而減少不斷的開啟、關閉等操作。以求達到減少不必要的資源損耗
執行緒
定義
執行緒(英語:thread)是作業系統能夠進行運算排程的最小單位。 大部份情況下,它被包含在 行程 之中,是行程中的實際運作單位。一條執行緒指的是行程中一個單一順序的控制流,一個行程中可以並行多個執行緒,每條執行緒並列執行不同的任務。在 Unix System V及SunOS 中也被稱為輕量行程(lightweight processes),但輕量行程更多指內核執行緒(kernel thread),而把使用者執行緒(user thread)稱為執行緒。
執行緒是獨立排程和分派的基本單位。執行緒可以為作業系統內核排程的內核執行緒
同一行程中的多條執行緒將共享該行程中的全部系統資源,如虛擬地址空間, 檔描述符 和 訊號處理 等等。但同一行程中的多個執行緒有各自的呼叫棧(call stack),自己的寄存器環境(register context),自己的執行緒本地儲存(thread-local storage)。
一個行程可以有很多執行緒來處理,每條執行緒並列執行不同的任務。如果行程要完成的任務很多,這樣需很多執行緒,也要呼叫很多核心,在多核或多 CPU ,或支持 Hyper-threading 的CPU上使用多執行緒程式設計的好處是顯而易見的,即提高了程式的執行吞吐率。以人工作的樣子想像,核心相當於人,人越多則能同時處理的事情越多,而執行緒相當於手,手越多則工作效率越高。在單CPU單核的電腦上,使用多執行緒技術,也可以把行程中負責I/O處理、人機互動而常被阻塞的部份與密集計算的部份分開來執行,編寫專門的workhorse執行緒執行密集計算,雖然多工比不上多核,但因為具備多執行緒的能力,從而提高了程式的執行效率。
執行緒池
執行緒池 (英語:thread pool):一種執行緒使用模式。執行緒過多會帶來排程開銷,進而影響緩存局部性和整體效能。而執行緒池維護著多個執行緒,等待著監督管理者分配可並行執行的任務。這避免了在處理短時間任務時建立與銷毀執行緒的代價。執行緒池不僅能夠保證內核的充分利用,還能防止過分排程。可用執行緒數量應該取決於可用的並行處理器、處理器內核、記憶體、網路sockets等的數量。 例如,執行緒數一般取cpu數量+2比較合適,執行緒數過多會導致額外的執行緒切換開銷。
任務排程以執行執行緒的常見方法是使用同步佇列,稱作任務佇列。池中的執行緒等待佇列中的任務,並把執行完的任務放入完成佇列中。
執行緒池模式一般分為兩種:HS/HA半同步/半異步模式、L/F領導者與跟隨者模式。
執行緒池的 伸縮性 對效能有較大的影響。
協程
協程,英文叫作 Coroutine,又稱微執行緒、纖程,協程是一種使用者態的輕量級執行緒。
協程擁有自己的寄存器上下文和棧。協程排程切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此協程能保留上一次呼叫時的狀態,即所有局部狀態的一個特定組合,每次過程重入時,就相當於進入上一次呼叫的狀態。
協程本質上是個單行程,協程相對於多行程來說,無需執行緒上下文切換的開銷,無需原子操作釘選及同步的開銷,編程模型也非常簡單。
序列
多個任務,執行完畢後再執行另一個。
例如:吃完飯後散步(先坐下吃飯、吃完後去散步)
並列
多個任務、交替執行
例如:做飯,一會放水洗菜、一會吸收(菜比較臟,洗下菜寫下手,傲嬌~)
並行
共同出發
邊吃飯、邊看電視
阻塞與非阻塞
阻塞
阻塞狀態指程式未得到所需計算資源時被掛起的狀態。程式在等待某個操作完成期間,自身無法繼續處理其他的事情,則稱該程式在該操作上是阻塞的。
常見的阻塞形式有:網路 I/O 阻塞、磁盤 I/O 阻塞、使用者輸入阻塞等。阻塞是無處不在的,包括 CPU 切換上下文時,所有的行程都無法真正處理事情,它們也會被阻塞。如果是多核 CPU 則正在執行上下文切換操作的核不可被利用。
非阻塞
程式在等待某操作過程中,自身不被阻塞,可以繼續處理其他的事情,則稱該程式在該操作上是非阻塞的。
非阻塞並不是在任何程式級別、任何情況下都可以存在的。僅當程式封裝的級別可以囊括獨立的子程式單元時,它才可能存在非阻塞狀態。
非阻塞的存在是因為阻塞存在,正因為某個操作阻塞導致的耗時與效率低下,我們才要把它變成非阻塞的。
同步與異步
同步
不同程式單元為了完成某個任務,在執行過程中需靠某種通訊方式以協調一致,我們稱這些程式單元是同步執行的。
例如購物系統中更新商品庫存,需要用「行鎖」作為通訊訊號,讓不同的更新請求強制排隊順序執行,那更新庫存的操作是同步的。
簡言之,同步意味著有序。
異步
為完成某個任務,不同程式單元之間過程中無需通訊協調,也能完成任務的方式,不相關的程式單元之間可以是異步的。
例如,爬蟲下載網頁。排程器呼叫下載程式後,即可排程其他任務,而無需與該下載任務保持通訊以協調行為。不同網頁的下載、保存等操作都是無關的,也無需相互通知協調。這些異步操作的完成時刻並不確定。
可異步與不可異步
經過以上了解,又是行程、又是執行緒、等等一系列的東西,那是真的難受。不過相信你已經有個初步的機率,那麽這裏我們將更加深入的去了解可異步與不可異步。
在此之前先總結一下,以上各種演進的路線,其實加速無非就是一句話,提高效率。(廢話~)
那麽提高效率的是兩大因素,增加投入以求增加產出、盡可能避免不必要的損耗(例如:減少上下文切換等等)。
如何區分它是可異步程式碼還是不可異步呢,其實很簡單那就是,它是否能夠自主完成不需要我們參與的部份。
我們從結果反向思考,
例如我們發送一個網路請求,這之間擁有網路I/O阻塞,那麽測試我們將它掛起、轉而去做其他事情,等他響應了,我們在進行此階段的下一步的操作。那麽這個是可異步的
另外:寫作業與上洗手間,我此時正在寫著作業,突然,我想上洗手間了,走。上完洗手間後又回來繼續寫作業,在我去洗手間這段時間作業是不會有任何進展,所以我們可以理解為這是非異步
goroutine
東扯一句,西扯一句,終於該上真家夥了,廢話不多說。
如何實作只需定義很多個任務,讓系統去幫助我們把這些任務分配到CPU上實作並行執行。
Go語言中的goroutine就是這樣一種機制,goroutine的概念類似於執行緒,但 goroutine是由Go的執行時(runtime)排程和管理的。Go程式會智慧地將 goroutine 中的任務合理地分配給每個CPU。Go語言之所以被稱為現代化的程式語言,就是因為它在語言層面已經內建了排程和上下文切換的機制。
在Go語言編程中你不需要去自己寫行程、執行緒、協程,你的技能包裏只有一個技能–goroutine,當你需要讓某個任務並行執行的時候,你只需要把這個任務包裝成一個函式,開啟一個goroutine去執行這個函式就可以了
goroutine與執行緒
可增長的棧
OS執行緒(作業系統執行緒)一般都有固定的棧記憶體(通常為2MB),一個goroutine的棧在其生命周期開始時只有很小的棧(典型情況下2KB),goroutine的棧不是固定的,他可以按需增大和縮小,goroutine的棧大小限制可以達到1GB,雖然極少會用到這麽大。所以在Go語言中一次建立十萬左右的goroutine也是可以的。
goroutine模型
GPM是Go語言執行時(runtime)層面的實作,是go語言自己實作的一套排程系統。區別於作業系統排程OS執行緒。
P與M一般也是一一對應的。他們關系是: P管理著一組G掛載在M上執行。當一個G長久阻塞在一個M上時,runtime會新建一個M,阻塞G所在的P會把其他的G 掛載在新建的M上。當舊的G阻塞完成或者認為其已經死掉時 回收舊的M。
P的個數是透過runtime.GOMAXPROCS設定(最大256),Go1.5版本之後預設為物理執行緒數。 在並行量大的時候會增加一些P和M,但不會太多,切換太頻繁的話得不償失。
單從執行緒排程講,Go語言相比起其他語言的優勢在於OS執行緒是由OS內核來排程的,goroutine則是由Go執行時(runtime)自己的排程器排程的,這個排程器使用一個稱為m:n排程的技術(復用/排程m個goroutine到n個OS執行緒)。 其一大特點是goroutine的排程是在使用者態下完成的, 不涉及內核態與使用者態之間的頻繁切換,包括記憶體的分配與釋放,都是在使用者態維護著一塊大的記憶體池, 不直接呼叫系統的malloc函式(除非記憶體池需要改變),成本比排程OS執行緒低很多。 另一方面充分利用了多核的硬體資源,近似的把若幹goroutine均分在物理執行緒上, 再加上本身goroutine的超輕量,以上種種保證了go排程方面的效能。
GOMAXPROCS
Go執行時的排程器使用GOMAXPROCS參數來確定需要使用多少個OS執行緒來同時執行Go程式碼。預設值是機器上的CPU核心數。例如在一個8核心的機器上,排程器會把Go程式碼同時排程到8個OS執行緒上(GOMAXPROCS是m:n排程中的n)。
Go語言中可以透過runtime.GOMAXPROCS()函式設定當前程式並行時占用的CPU邏輯核心數。
Go1.5版本之前,預設使用的是單核心執行。Go1.5版本之後,預設使用全部的CPU邏輯核心數。
goroutine的建立
使用goroutine非常簡單,只需要在呼叫函式的時在函式名前面加上go關鍵字,就可以為一個函式建立一個goroutine。
一個goroutine必定對應一個函式,當然也可以建立多個goroutine去執行相同的函式。
語法如下
func
main
()
{
go
函式
()
\
[
普通函式和匿名函式即可
\
]
}
如果你此時興致勃勃的想立馬試試,我只想和你說,「少俠,請稍等~」,我話還沒說完。以上我只說了如何建立goroutine,可沒說這樣就是這樣用的。嘻嘻~
首先我們先看看不用goroutine的程式碼,範例如下
\#
example
package
main
import
(
"fmt"
"time"
)
func
example
(
i
int
)
{
//fmt.Println("HelloWord~, stamp is", i)
time
.
Sleep
(
time
.
Second
)
}
// normal
func
main
()
{
startTime
:
\
=
time
.
Now
()
for
i
:=
0
;
i
<
10
;
i
++
{
example
(
i
)
}
fmt
.
Println
(
"Main~"
)
spendTime
:
\
=
time
.
Since
(
startTime
)
fmt
.
Println
(
"Spend Time:"
,
spendTime
)
}
輸入結果如下
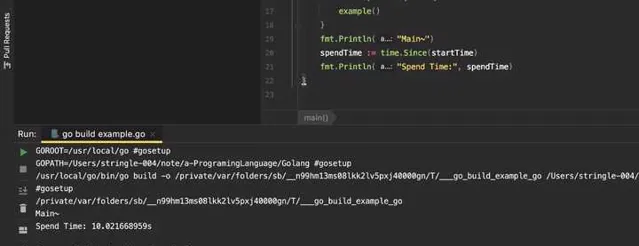
那麽我們來使用goroutine,執行
範例程式碼如下:
package
main
import
(
"fmt"
"time"
)
func
example
(
i
int
)
{
fmt
.
Println
(
"HelloWord~, stamp is"
,
i
)
time
.
Sleep
(
time
.
Second
)
}
// normal
func
main
()
{
startTime
:
\
=
time
.
Now
()
// 建立十個goroutine
for
i
:=
0
;
i
<
10
;
i
++
{
go
example
(
i
)
}
fmt
.
Println
(
"Main~"
)
spendTime
:
\
=
time
.
Since
(
startTime
)
fmt
.
Println
(
"Spend Time:"
,
spendTime
)
}
輸出如下
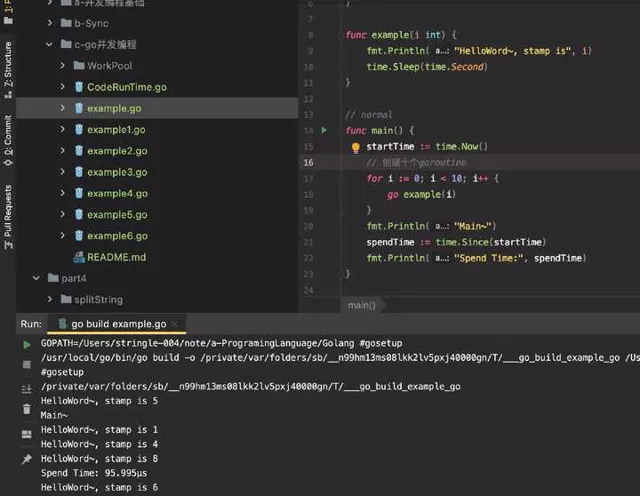
乍一看,好家夥速度提升了簡直不是一個量級啊,秒啊~
仔細看你會發現,7,9 跑去哪兒呢?不見了,盯~
本文分享自華為雲社群【盤點Golang並行那些事兒之一】,原文作者:PayneWu。參考來源:https://www. cnblogs.com/huaweiyun/p /14391939.html











