編輯:編輯部 HYZ
【新智元導讀】馬斯克建超算速度,被中國這家公司用120天復刻了。119個貨櫃,像搭積木一樣拼出一座算力工廠。這不是科幻電影,而是浪潮資訊交付的驚艷答卷。一個全新的AI時代,正在這裏拉開序幕。
120天,119個貨櫃,一座算力工廠拔地而起。
馬斯克速度,竟被國內這家公司完美復刻了!

上面這座算力工廠,采用了浪潮資訊專為AI時代提出的預制化AIDC解決方案。
他們以「搭積木」方式,向世界詮釋了驚人的基建速度。
它不僅將長達18個月的建設周期,大幅縮短至4個月,甚至還實作了高效節能、彈性擴容、按需客製、便捷運維等技術創新。
更為重要的是,這座算力工廠能夠完全滿足scaling大模型的算力需求。
不論是訓練,還是套用部署,預制化AIDC解決方案全面支持了AI大模型創新研發和套用。
而現在,這座元腦「算力工廠」正式投入營運。
AI猛吞算力,還需破局之道
算力,就是這個AI時代的「命門」。眾所周知,AI大模型對算力的需求,遠超乎所有人的想象。
不論是OpenAI、微軟,還是谷歌等科技巨頭們堅信的是,scaling law仍在繼續。
2024年12月,堪稱過去一年AI含金量最高的一個月,從中便可瞥見一二。
OpenAI十二天Devday連更,為所有人送上了滿血版o1、o1 Pro、Sora、高級語音功能,以及初次亮相的o3系模型。
大批網友上線直接把ChatGPT搞崩了
與之激烈對打的谷歌,更是戰績連連,憑借Gemni 2.0 Flash、Veo 2直接殺出重圍。
邁入2025年,Grok 3、Llama 4、完整版Gemni 2.0等眾多模型,也即將迎來新一輪大戰。
可以預見的是,每一代新模型都在瘋狂「吃」算力,訓練參數呈指數級增長。這種瘋狂擴張的態勢,讓人不禁要問:我們的數據中心基建,還能支撐多久?
實際上,當前的數據中心正面臨著最核心的「三重困境」。
1. 建設周期長,無法及時彌補高算力需求
作為算力的核心載體,數據中心的建設非一蹴而就。
一般來說,傳統數據中心的建設是一個復雜的工程,需要經過設計、土建、機電安裝、偵錯等多個階段。其中,光規劃和建設就要3-5年時間,占到了整個生命周期的約1/3。
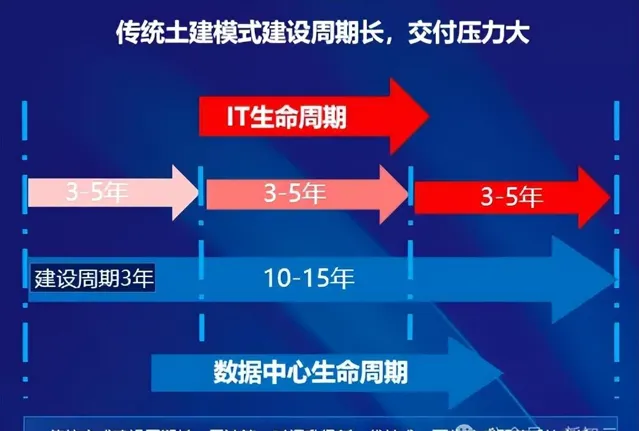
老黃同樣說過,「建造一個超算通常需要3年的規劃時間,外加1年裝置交付和偵錯時間」。
而我們所看到的,馬斯克10萬塊GPU建設速度,甚至即將要建的100萬塊GPU搭建的超算,也只是個例。
3年,這一時間跨度,對於快速發展的AI時代顯得尤為漫長。
比如,3年前規劃的數據中心普遍采用5-10kW/標準櫃,而如今單台AI伺服器的功耗就已突破10kW。
顯而易見,AI叠代與基建建設的速度,嚴重不匹配,導致數據中心還未建成就已落後於時代。
同時,這種「建設慢,需求快」的矛盾,不僅影響了產業發展速度,還直接影響了投資方資金報酬周期,形成了惡性迴圈。

2. 功耗攀升,能源利用率低
其次,隨著算力需求的暴增,數據中心的能耗問題也愈發突出。
AI大模型訓練的耗電量,堪比一個小城市的用電量。而這樣比比皆是的報道,也早已家喻戶曉。
平均而言,ChatGPT查詢所需的電力是谷歌搜尋的近10倍。高盛研究估計,到2030年,數據中心的電力需求將增長160%。
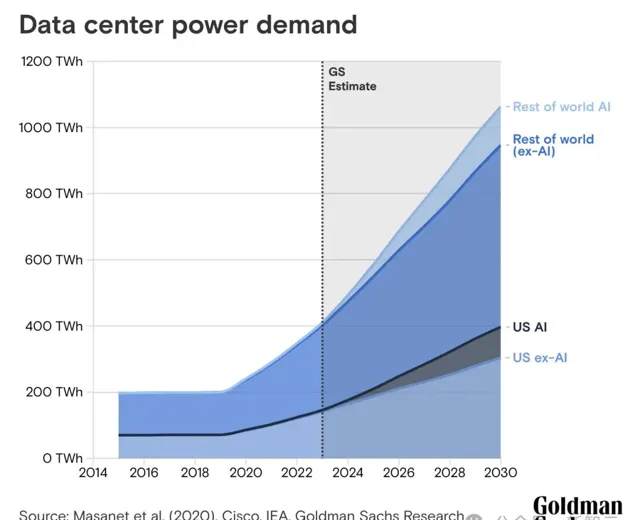
從2023年-2030年,AI數據中心功耗的增長將達到每年200Twh
另一方面,數據中心功耗也面臨著巨大的挑戰。
從芯片設計方面來看,CPU熱設計功率(TDP)在過去十年幾乎翻倍,GPU熱設計功耗從2008年不足200W飆升至現如今1000W。
再加上,集群越來越大,高密度伺服器部署來帶的散熱壓力,與日俱增。
與此同時,信通院釋出的【中國綠色算力發展研究報告(2024年)】顯示,中國數據中心的平均電能利用效率(PUE)在2023年時為1.48,而新的國家政策規定,新建數據中心的PUE不得超過1.25。
如何保持高效能計算的同時,達到節能標準,已經成為一大難題。
而當前,智算中心需要探索的是,與綠色電力深度融合,實作能源高效利用,讓算力向智力有效轉化。

3. 擴容難題,升級有限,無法第一時間進行升級
不僅如此,AI快速叠代對數據中心的靈活性,提出了更高的要求。
然而,傳統數據中心的固定架構,限制了升級空間,無法及時采用新一代技術,難以快速響應業務需求的變化。
另一方面,數據中心還將面臨建成即落後、供不應求的窘境,投資報酬率難以保障。
針對這些挑戰,這些年,一些企業打造的預制模組化數據中心套用而生,並將成為主流模式。
根據規模不同,可分為單元級(Unit)、包間級(Pod)、建築級(Stack Cube)、園區級(Base)等細粒度。
在AI時代下,我們就需要專為AI而生的預制化AIDC。
浪潮資訊,便是這個方案的引領者。

算力工廠,全方位為AI而生
算力工廠是一種創新的數據中心全生命周期服務模式,核心是透過規(劃)、建(設)、運(營)一體化的「交鑰匙」工程。
其總體架構自下而上,由算力底座、算力支撐、算力營運三部份組成。
算力底座
首先,算力底座,就是我們可以直觀看到的算力中心。
元腦「算力工廠」這座智算中心采用創新的預制化AIDC解決方案,僅需119個預制化貨櫃單層拼接,4個箱體即可實作千卡規模AI算力。
正如之前所述,它書寫了驚人搭建速度的傳奇,直接將同等規模數據中心的建設周期,從18個月縮減至4個月。
這種創新方案,可以說完全顛覆了行業常規。
具體來說,它具備了以下幾點優勢:
- 快速交付,工期可縮短80%左右
因為采用了預制化貨櫃建設方式,同等規模數據中心的建設周期從18個月縮減至4個月,工期縮短了近80%。
- 高效節能,PUE可低至1.1以下
因為創新地套用了液冷、光伏、儲能、余熱回收等節能技術,提高了散熱及能源利用效率,PUE可降至1.1以下,全年節省電費近2億元,營運成本大幅降低。
- 靈活擴充套件,最高可擴容至5層,實作全場景覆蓋
預制模組化疊箱體系建設模式可根據業務規模,分期高效地進行水平及豎向擴容,有效節省前期投入成本。
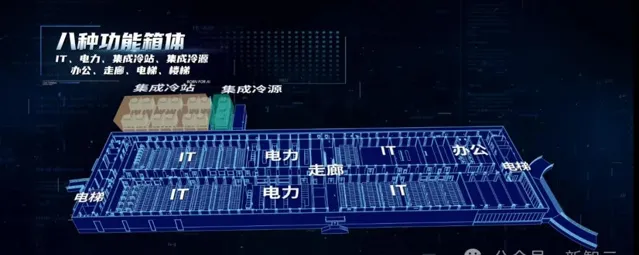
同時,八種模組化的功能箱體可根據不同場景、規模靈活組合,並按照功率區段分區部署,實作風冷/液冷、AI/通用/高密度等多種形態靈活相容,匹配智算算力、通用算力、邊緣算力等多種套用場景。
元腦算力工廠包含了數據處理、AI大模型、業務套用、研發測試等多個集群,為全球伺服器壓力測試、大模型開發套用等多種業務套用,提供了綠色高效的算力支撐。
算力營運
如前所述,在大模型時代,算力需求呈爆發式增長,但高效營運AI算力卻面臨著諸多的挑戰。
該如何排程資源?如何控制成本?如何保障算力平台穩定性和可用性?如何讓AI算力效能持續最佳化?
在大規模AI訓練場景下,算力資源排程堪稱一大難題。
一方面,不同AI任務對於算力需求各不相同;另一方面,如何在多使用者、多工場景在實作資源最優分配,避免算力的浪費,都是亟待解決的問題。
不僅如此,隨著算力規模的擴大,營運成本也會隨之攀升。諸如電力消耗、運維人員等各方面成本,都是企業面臨的挑戰。
另外,對於企業級AI套用來說,對算力平台穩定性提出了高標準、高要求。
然而,集群規模擴大管理只會愈加復雜,硬體出現故障的風險就會增加,隨之帶來的是系統效能波動頻繁,數據安全隱患增高。
還有需要考慮到的一點是,AI算力效能必須持續最佳化。這當中也涉及到了多個層面,比如硬體協同最佳化、軟體架構改進、演算法效率提升等等。
為了應對這些挑戰,元腦算力工廠為企業提供了全方位的營運方案。

- AI基礎設施管理平台
AI基礎設施管理平台面向金融、通訊、互聯網等多行業的數據中心,可實作前所未有的一體化管理。
平台突破性解決了IT基礎設施管理與動力環境管理割裂的痛點,帶來了全新的管理體驗。
首先,它實作了智算中心全生命周期的統一納管,運維效率提升100%。
平台還創新實作了高密單排微模組2D/3D、核心制冷部件遠端調控等5大功能,安全效能飆升30%,為超大規模數據中心穩定高效執行提供重要保障。
- 人工智慧開發平台AIStation
作為深度學習開發平台,AIStation能夠為企業客戶提供強大的開發支持。
比如,統一管理和精細排程AI計算資源,全面整合計算資源、訓練數據和開發工具。
不僅如此,AIStation還提供了完整的AI軟體棧和敏捷標準化的開發流程,降低資源投入同時,大大提升開發效率。
基於系列平台的創新與整合,對於企業來說,算力的高效穩定營運也不再是難題。
大規模AI訓練與套用
既然有了這樣一個堪稱「黑科技」含量最高的解決方案,對於大模型時代下的訓練和部署,意味著什麽?
當前,AI大模型正在經歷著前所未有的前進演化:從單一語言模型走向多模態;突破長文本限制;引入MoE架構;強化學習能力不斷提升。
不僅如此,大模型前進演化Scaling Law仍在繼續,老黃還在CES大會上首次提出了AI時代三個Scaling Law。
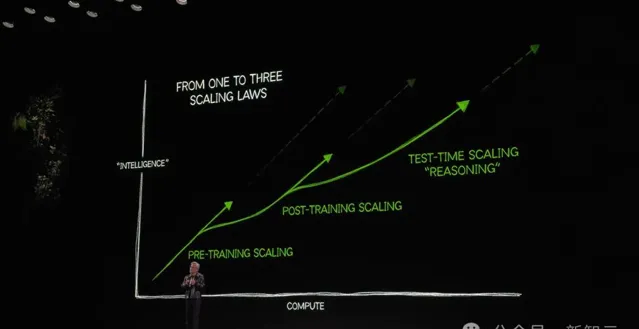
這暗示著,大模型的突破未來有著更加廣闊的空間,唯一的限制,就是如何構建出強大的算力基礎設施。
如今,AI大模型的參數規模已經從千億級別攀升到了萬億級別。AI大模型廠商紛紛投建大規模算力資源,壓縮大模型訓練周期。
顯而易見的是,隨著算力規模的不斷擴充套件,單顆芯片的效能瓶頸愈發明顯,整個AI系統的通訊效率成為焦點之一。
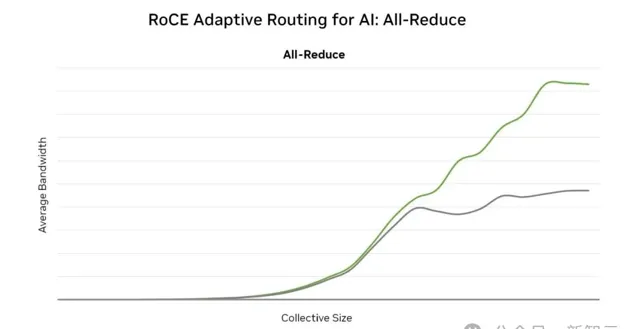
大型AI模型訓練過程中,網路通訊通常占據整體訓練時間的20%到40%,這造成了大量算力資源浪費,最佳化網路通訊效率,成為AI大模型發展的關鍵議題。
然而,目前的傳統RoCE網路面臨著網路效能不足、難以滿足多樣化AI系統網路需求、部署周期長、可靠性低、管理難度大等問題。
對此,元腦算力工廠采用了專門面向生成式AI打造的超級AI乙太網路交換機——X400,大幅降低網路通訊占比,革命性地提升了大規模GPU訓練效能;同時,采用浪潮資訊 ICE智慧雲引擎,實作智慧化的網路管控。
這,就成為了新型的AI訓練網路解決方案,打造業界領先的AI Fabric。
超級AI乙太網路交換機X400,采用AR自適應路由、RTT CC擁塞控制、亞毫秒級故障自愈等技術,擁有高效能(高吞吐量、高頻寬、低延遲)、高可靠性、快速部署、靈活拓展等核心優勢。同時,它還具備多租戶隔離、多業務並行支持的能力,以應對AI模型訓練的復雜需求。
效能方面,X400的吞吐量達到了業界最高的51.2T,較上一代產品提升了4倍。在4U空間可提供128個400Gb/s的高速網路埠,相比傳統RoCE網路效能提升了1.6倍。
值得一提的是,其對AI網路的頻寬利用率可達95%以上,同時還可將通訊時延降低30%。
綜上,X400的套用將大幅提升大模型的訓練效率,縮短訓練時長,降低訓練成本。
此外,在 AIGC 時代,網路管理已不再是傳統的裝置配置與監控,而是面向未來的智慧化、自動化以及視覺化的平台。
浪潮資訊ICE智慧雲引擎正是這一趨勢下的先行者,基於數位孿生技術,打造網路虛擬仿真和最佳化驗證平台,並利用人工智慧技術實作自動化管理和智慧化監控,提升管理效率與故障響應速度,讓企業在復雜環境中實作高效、可靠的網路運維,助力企業充分釋放AIGC潛能。
系統性創新,三層無縫銜接
算力基礎設施有了之後,如何解決算力與套用之間斷層問題?
在此之前,浪潮資訊早已給出了完美的解決方案——企業大模型開發平台「元腦企智」EPAI。
它猶如一座「橋梁」,透過提供軟體棧及綜合服務,賦能算力挖潛、模型最佳化和套用開發。
這次,元腦算力工廠直接搭載了EPAI,連線了多元算力、多元模型、套用層,直接加速LLM套用落地。
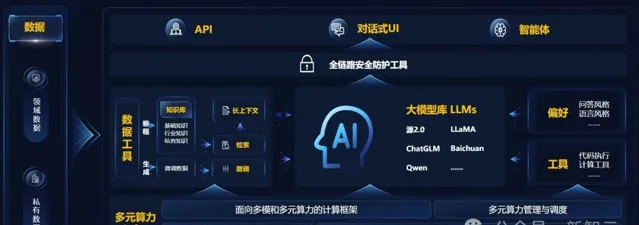
元腦企智EPAI的完整架構
EPAI可實作百萬token、千億參數、領域大模型的高效微調,可以更好地適應具體行業場景下的任務需求,快速打造領域LLM。
與此同時,它還提供面向多元多模的計算框架,讓LLM套用在跨算力平台上無感遷移。
這個過程,就降低了多模、多元的適配與試錯成本,為企業使用者根據實際場景需求,選擇開發部署適合自己的大模型,提供了極大便利。
透過EPAI,企業可以高效地開發部署生成式AI套用,打造智慧生產力。
在AI時代浪潮下,算力基建正成為決定創新速度、深度的關鍵要素。
基於預制化AIDC解決方案的算力工廠,不僅僅是一次技術創新,更是對這整個產業發展模式的革新。
算力工廠重新定義了算力釋放的價值與效率,實作了基建與算力的強繫結,是以算力為中心來確定建設模式和內部的算力模組,所有設計都是算力的一部份,實作了投入即產出。
這一次,浪潮資訊向世界真正展現了,中國速度與中國智慧的完美融合。
算力工廠的模式將成為智算中心建設的主流。











