我統計了這個問題下的13619個回答,希望能給這個問題一個基於數據的、科學客觀的分析。

1. 動機
我最初看到這個問題,是因為我點進了這個問題下的一個高贊回答。隨後,我又閱覽了另外幾個高贊回答。每個高贊的回答都有不同的特點,有些真的能喚起人的共鳴(我也是00後),有些則很有趣,有些則打動人心,有些能引人深思。
我相信大多數看到這個問題的人和我是一樣的,我們都被高贊回答吸引而來,並且只看到了一些高贊的回答。然而,高贊答案不過是寥寥幾十個,然而世界上有那麽多的00後,我相信,這些高贊僅僅是廣大00後群體的冰山一角。
那麽,有意思的問題來了: 00後,作為一個廣大的群體,他們的憂慮到底都有哪些?
解決這個問題的一個思路,就是分析更多的樣本。 高贊答案不過是幾十個,然而,這個問題下總共有一萬多個回答。雖然這一萬多個回答跟廣大的00後群體相比依然只是滄海一粟,然而我認為如果我們能夠分析這一萬多個回答,我們或授權以對00後群體有更清晰的認知。
因此,我收集了台北時間2月6日下午3點之前所有回答的數據。數據獲取過程中有極小量數據遺失(約1%),最後我獲得了 13619 個回答。我決定利用這13619個回答,來探索00後群體到底在憂慮什麽。
2. 初步分析
首先,先看看答主們寫了多少。我把這 13619 個回答按照字數的數量級歸類,畫出了直方圖和餅圖。
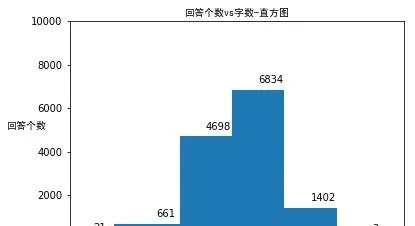
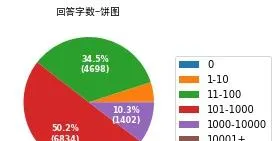
我們發現大部份答主的回答在10-1000字的區間,而100-1000字的答主占了超過總數一半的回答。1000字以上的回答也不少,超過了10%, 說明至少在字數層面上,有不少答主是在很用心的寫作的 。如果我們認為超過100字的回答算比較認真的回答的話,那麽有超過60%的答主都在認真回答問題。
隨後看一下點贊的情況。我們並不意外地發現: 高贊回答僅僅占據了全部回答的極小部份 。這進一步也說明,高贊回答僅僅是冰山一角,這數十個高贊答案背後,是上萬個不容易被大家看到的小於10贊的答案。
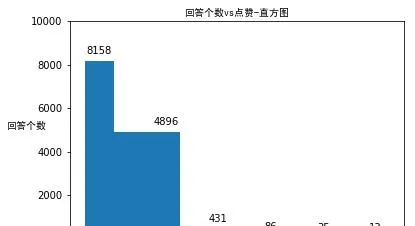
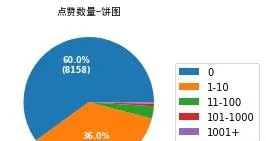
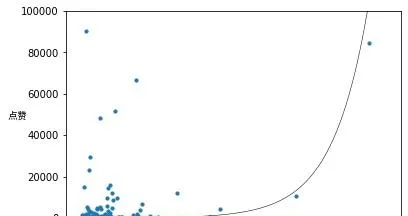
我們接下來可以看看字數和點贊數的相關性。憑直覺我們會覺得字數越多應該點贊越多,但其實這兩個關系其實不是很強。

左上角的回答:00後在憂慮什麽?
右上角的回答:00後在憂慮什麽?
右下角的兩個回答:00後在憂慮什麽?(這個還有1w贊),00後在憂慮什麽?(這個竟然只有5個贊)
用帕松回歸擬合一下,發現Pseudo R^2是0.2255(Pseudo R^2表示關系的強烈程度,取值0~1,越接近1越強)。 這說明字數和點贊數是有關的,但是關系不是很強。
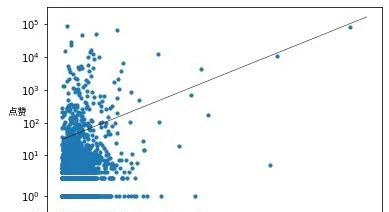
(應評論區要求,我報一下p值。通俗地來說,p值表示置信程度,一般p值越小越可信,通常p值小於0.05就是足夠可信的結論。因為我的數據量很大,所以p值都非常小。上述模型中線性擬合的F值的p值,也是唯一預測變量字數的p值,是6.67e-123。帕松回歸程式跑出來的 LLR的 p值是0,截距和字數的p值也都是0,實際p值應該是大於0的,應該是計算精度誤差導致的。不過這些足以說明上述兩個模型的置信度都是非常高的。)
另外, 這13619個答案加起來一共有 532.6萬 字。我們可以看看不同贊數區間的答主各自貢獻了多少字數。
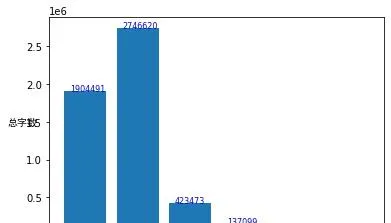
這說明,這個問題下的大部份文本量,都來自於低贊(0-10贊)回答。
這個回答下有很多答主在傾述自己的憂慮。所有回答共計寫了數百萬字,然而,它們之中的絕大部份並不是高贊,想必這些內容也不容易被別人看到。我們容易看到的高贊(1000+贊)回答,從文本量上來看,僅僅占據這全部文本的2%。
因此,我們有必要想辦法分析這一萬多篇沒有很多贊的回答,去分析這不容易被看到的幾百萬字,去挖掘冰山在水下潛藏的巨大山體。
3. 答主年齡分析
在分析這幾萬篇共計幾百萬字的回答之前,我們先有必要分析一下這些回答的作者。
「00後」這個詞一般是指00-09年出生的人。但是,我們能感覺出來,這個回答下的各個00後的年齡並不是均勻分布的,所以我們可以先研究一下答主們的年齡分布。
有很多答主在回答的時候都會提到自己的出生年份。因此,我們可以用正規表式來匹配這些資訊。
([09][0-9])(年|的|高中|大學|出生|生|女|男)
這個正規表式表示我們想要匹配形如XYZ的內容,其中X為0或9,Y為任意數位,Z為「年」、「的」、「高中」、「大學」、「出生」、「女」、「男」。
這個匹配方式可能會有一些誤判,但是基本還是準確的。
匹配之後,我們發現總共有 3498個 回答暴露了自己的出生年份。把數據視覺化,我們能看到:
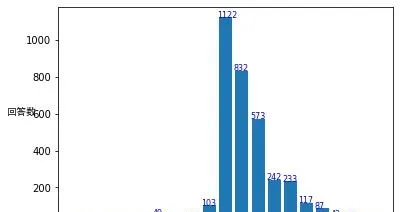
可以看到,這個分布是非常傾斜的。00-09年出生的人中,出生越早的答主越多。 不過也可以理解,畢竟目前08、09的孩子們還太小。還有99年生的人回答得也不少,我覺得也是可以理解的。99年和00年、01年的也沒什麽本質區別。
所以我認為, 到目前為止這個問題下的回答所反映的情況,更多還是99-06年生的人在目前的情況,尤其是00-02年生的人的情況。
我們用這些答主的答題年份,減去他們的出生年份,便可以估算出他們回答問題的時候的年齡。

我們可以看到,大多數答主在回答問題的時候是在20歲左右。 其中20歲的人最多,15-19歲的也有很多,而且年齡越大則越多。其中21歲也有一些,22歲以上的很少。 可以看出,答主們的年紀主要還是大學生年紀,以及少部份的高中生年紀,還有極少量的其它。
4. 文本分析—00後們的憂慮是什麽?
如何了解廣大的00後群體到底在憂慮什麽呢?
我們可以有兩個思路,第一種是高頻詞——統計每個詞在所有回答中的出現次數。這種統計非常直接,也能很好的反應一個概念在這個問題下被提到的次數。這種統計方式或許能大致可以反應00後最憂慮的事物。第二個思路就是統計每個詞在多少個回答之中出現,這種統計方式大致可以反應被最多的00後關心的事物。
我們使用spacy的 zh_core_web_lg 進行分詞。統計的時候要去掉各種虛詞,比如的、地、得這些(嚴格來說是stopwords)。
4.1 統計每個詞的在所有回答中的出現次數。
我們對 所有回答(13619個) 進行統計,出現頻率前10的詞是:
1 憂慮 頻率: 24.11 次/萬字
2 生活 頻率: 15.18 次/萬字
3 父母 頻率: 13.8 次/萬字
4 真的 頻率: 13.69 次/萬字
5 錢 頻率: 12.91 次/萬字
6 00後 頻率: 12.09 次/萬字
7 未來 頻率: 12.09 次/萬字
8 學習 頻率: 11.85 次/萬字
9 大學 頻率: 11.83 次/萬字
10 工作 頻率: 11.82 次/萬字
按照順序,接下來的40個詞依次是:努力, 學校, 焦慮, 孩子, 喜歡, 社會, 買, 家裏, 媽, 高中, 感覺, 爸, 考, 成績, 時間, 專業, 家庭, 老師, 希望, 兩, 東西, 學, 世界, 高考, 同學, 事情, 壓力, 次, 歲, 擔心, 高, 天, 朋友, 一點, 畢業, 吃, 事, 時代, 城市,只能……
這個結果是我個人感覺是很合理的。前10個高頻詞,去掉題目裏出現的「憂慮」、「00後」,再去掉副詞「真的」,剩下7個詞是:生活、父母、錢、未來、學習、大學、工作。考慮到回答問題的人應該主要是大學生,其次是高中生, 我覺得這些詞是能很好的概括00後目前所憂慮的事情的 。
4.2 統計每個詞在多少個回答中出現
我們對 所有回答(13619個) 進行統計:
1 憂慮 出現在了: 5368 個回答之中
2 生活 出現在了: 4059 個回答之中
3 未來 出現在了: 3796 個回答之中
4 父母 出現在了: 3374 個回答之中
5 工作 出現在了: 3355 個回答之中
6 大學 出現在了: 3332 個回答之中
7 真的 出現在了: 3268 個回答之中
8 學習 出現在了: 3091 個回答之中
9 00後 出現在了: 3075 個回答之中
10 努力 出現在了: 3050 個回答之中
接下的40個詞是:錢, 學校, 感覺, 社會, 家裏, 焦慮, 考, 高中, 喜歡, 家庭, 希望, 孩子, 買, 時間, 東西, 成績, 高, 兩, 畢業, 高考, 專業, 學, 世界, 事情, 只能, 壓力, 一點, 歲, 事, 能力, 天, 同學, 發現, 朋友, 媽, 次, 老師, 城市, 吃, 走, 人生……
有沒有發現很眼熟?沒錯,你會發現,兩種統計方式得到的高頻詞表,是非常的相似的。對比咱們之前得到的全體答案高頻詞表,前10的詞匯中,有9個是重合的。「憂慮」、「生活」、「未來」、「父母」、「工作」、「大學」、「真的」、「學習」、「00後」。而這次出現在前十而上次沒有出現在前10的「努力」,在上一個列表裏正好是第11。而上次進前十而這次沒進的「錢」,這次也正好是第11。 這說明兩種統計方式得到的結果是非常相似的。
而透過這兩種統計方式得到的結果,一定程度上也能反應現在00後的憂慮。
我把所有答案的前50高頻詞(第一種統計方式得到的結果)拿出來,去掉一些沒什麽實際意義的詞,去掉一些跟「憂慮」本身有關的詞(「焦慮」、「壓力」),剩下的高頻詞差不多是這些:
父母, 錢, 未來, 學習, 大學, 工作, 努力, 學校, 喜歡, 社會, 買, 家裏, 媽, 高中, 爸, 考, 成績, 時間, 專業, 家庭, 老師, 學, 世界, 高考, 同學, 朋友, 畢業, 時代
我個人總結一下,簡單分個類,就是:
家庭 :父母,家裏,媽,爸,家庭
學業 :學習,大學,學校,高中,考,成績,專業,老師,學,高考,同學,畢業
社交: 同學,朋友
經濟/工作/社會: 錢,工作,買,社會
年輕的煩惱: 努力、未來、時間,世界,時代
其實仔細看一看,00後的煩惱也沒有很出乎意料。雖然我本人是00後,但我覺得80後、90後在他們這個年紀的時候,他們的憂慮應該也差不多就是這些:家庭、學業、朋友、工作、社會,以及自己年輕的理想、思想與抱負。
這只是前50詞,如果我們再多用一些詞,比如前100詞,然後用 Li, Shen等人的詞向量 GitHub - Embedding/Chinese-Word-Vectors: 100+ Chinese Word Vectors 上百種預訓練中文詞向量 把詞轉譯成向量,然後用t-SNE視覺化,就可以得到回答開頭的那張圖:
跟我剛才手動整理的50詞相比,100詞看上去包含的內容更加全面一些。除了我之前總結的幾個方面外,我們還能看到「吃」、「玩」等娛樂消費相關詞匯,「能力」、「改變」、「優秀」等有關個人發展的詞匯,還有「房子」、「結婚」等這種代表00後以逐漸步入成年的詞。
然而,和剛才一樣,這些詞感覺也沒有非常的特別。依然是很合理的年輕人會有的煩惱。
或許每一個00後都有自己復雜的煩惱,然而,當我們站在宏觀的來看,00後作為一個群體,應該也沒有很多特殊之處。
我也是個00後,我現在有個小小的憂慮。我希望我的這篇答案能被更多人看到,因為我用數據科學的方法分析了13619個回答,這可以給大家關於00後更全面、宏觀、客觀的認識。
給我點個贊再走好嗎?
(雙擊螢幕有驚喜)
5. 額外內容:高贊能很好地代表00後們嗎?
這是一個很有趣的問題。正如我在一開始所說,我相信大多數人都是被高贊回答吸引而來,並且只看到了一些高贊的回答。因此,我們想知道,這為數不多的數十個高贊回答,是否能很好地代表廣大的00後。
為了解決這個問題,我們的思路是——統計高贊的詞頻,並把高贊詞頻和全體答案的詞頻對比。
5.1 統計每個詞的在所有千贊及以上的回答回答中的出現次數。
我們統計 所有千贊及以上的回答(48個) 的高頻詞:
1 00後 頻率: 14.17 次/萬字
2 生活 頻率: 11.37 次/萬字
3 喜歡 頻率: 10.32 次/萬字
4 孩子 頻率: 9.45 次/萬字
5 真的 頻率: 9.27 次/萬字
6 努力 頻率: 8.31 次/萬字
7 父母 頻率: 7.87 次/萬字
8 工作 頻率: 7.44 次/萬字
9 錢 頻率: 7.35 次/萬字
10 高中 頻率: 7.26 次/萬字
按照順序,接下來的40個詞依次是:學校, 爸, 社會, 兩, 時代, 憂慮, 寫, 時間, 買, 焦慮, 希望, 事, 一點, 世界, 學習, 大學, 媽, 東西, 好像, 次, 天, 吃, 回答, 歲, 問, 老師, 未來, 家裏, 家庭, 高, 發展, 走, 教育, 成績, 同學, 更新, 前, 壓力, 感覺, 理解……
我們對比全部回答的高頻詞,和高贊回答的高頻詞。我們發現,兩者雖然不完全一致,但是依然是有很大重疊的。 比如前10高頻詞就有6個是重疊的:「00後」、「生活」、「真的」、「父母」、「工作」、「錢」。所有回答的前10高頻詞剩下的四個:「憂慮」、「未來」、「學習」、「大學」在高贊回答的前50高頻詞列表裏也有出現;而高贊回答剩下的四個高頻詞:「喜歡」、「孩子」、「努力」、「高中」也在所有回答的前50高頻詞列表裏。
5.2 統計每個詞在多少個千贊以上回答中出現
所有千贊及以上的回答(48個):
1 生活 出現在了: 34 個回答之中
2 努力 出現在了: 30 個回答之中
3 00後 出現在了: 28 個回答之中
4 憂慮 出現在了: 28 個回答之中
5 未來 出現在了: 27 個回答之中
6 世界 出現在了: 27 個回答之中
7 兩 出現在了: 26 個回答之中
8 大學 出現在了: 26 個回答之中
9 希望 出現在了: 26 個回答之中
10 社會 出現在了: 25 個回答之中
接下來的40個是:工作, 父母, 時代, 真的, 時間, 吃, 學習, 買, 高, 歲, 事, 越來越, 錢, 發現, 孩子, 高中, 學校, 天, 喜歡, 東西, 人生, 前, 回答, 現實, 事情, 寫, 只能, 家庭, 焦慮, 教育, 總, 家裏, 次, 走, 能力, 一點, 第一, 城市, 想法, 問……
我們繼續對比全部回答的高頻詞和高贊高頻詞,前10個詞依然有個6個是重合的:「生活」、「努力」、「00後」、「憂慮」、「未來」、「大學」。 在統計每個詞在多少個回答中出現的情況下,全部回答的高頻詞和高贊高頻詞依然有比較高的相似程度。
因此,我們發現:高贊回答和全體回答的詞分頻布是比較相似的。
這說明: 這個問題下的數十個高贊回答,在一定程度上,還是可以代表這上萬個回答。無論贊數多少,寫回答的00後們的憂慮大體都是相似的。
雖然寥寥數十個高贊回答只是這一萬多個回答的冰山一角,然而,這冰山一角還是有一定代表性的。本回答從大規模數據分析的角度分析了00後的憂慮,角度比較宏觀。如果你想更加具體地了解一些具體的00後們的憂慮,這些高贊回答也是可以作為很好的例子的。
如果還有什麽想要挖掘的資訊,請在評論區留言並追更,我會盡量加上的!
點個關註吧,謝謝大家!











