最近忙找工作,一直没更新文章。。。
本文链接:https:// arxiv.org/pdf/2008.1146 9.pdf
首先介绍一下问题背景:
多人绝对距离姿态估计是人体姿态估计里一个比较特殊的分支,其特殊之处在于对于图片中的人体,不光要输出单位为毫米的三维姿态,还要给root节点分配一个距离相机的距离。我们知道,单张图片求解深度距离是一件非常困难的事情,一般来说,我们需要人的真实尺寸以及图中的尺寸信息和相机的内参。但是在实际使用的时候,相机内参并不容易获取,且由于场景的多样性,导致数据域和训练时可能大不一样。
本文贡献:
提出了一种3D人体绝对距离姿态估计的方法,通过监督2D关键点+PAF(Openpose的方法)、根节点深度、和身体部分相对深度来解决该问题。
下面直接上pipeline图:
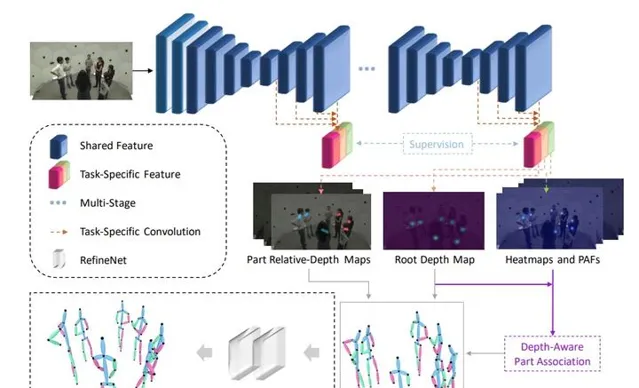
蓝色的部分是Stacked Hourglass,然后在Stacked Hourglass每一个模块之后将原来的关键点热力图给扩充成N个关键点热力图+2(N-1)个PAF+(N-1)个相对深度图+1个关键点深度图。
接下来分析损失函数:
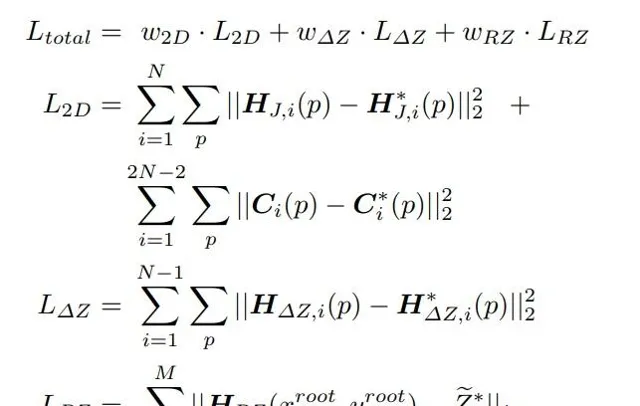
Loss Func分为三个部分,第一个部分是2D关键点相关的,即监督关键点热力图和PAF,第二个部分是各个关键点相对root深度,最后一个是root点深度。
在这个基础上,为了易于训练,本文归一化了两个参数,1. 预测根节点深度, 2. 最大骨长限制。
根节点深度的归一化比较神奇,一般来说焦距(focal length)的单位是毫米,但是本文使用的焦距单位是像素(pixel),经过搜索,我找到了这样的解释:

但是显然CCD_SIZE在数据集里面是没有的(至少Human3.6M没有),所以文中Human3.6M的结果不知道是不是随便给的一个CCD_SIZE算出来的。
第二个归一化的参数是骨长限制,这个就是经验了。
关于本文其实存在一点不太清楚的地方:
- 关于深度的热力图是怎么构建出来的,如果和关键点一致,感觉上只有数值不同,那为什么不直接输出数值,一下子能省64*64*(N-1)的空间。
- 深度是怎么监督的?注意到损失函数第三项是取对应位置的深度值做监督,但是训练过程中这样做非常耗时,而且存在一个监督信号稀疏的问题。
经过代码的一个阅读,我得到了答案。
首先是以像素为单位的焦距,其实仔细看上图,是直接把以毫米为单位的焦距和它进行数值上的等同的。所以直接用就好。
其次是深度的热力图,这个地方我想复杂了,实际上只需要在生成标签的时候,把root的位置移动到最近的格点(这么做比较糙)就可以了,然后训练的时候直接监督对应的热力图位置的值。











