邹经纬 马辉/ 国泰君安证券股份有限公司
钟浪辉 陈敏/ 上交所技术有限责任公司
行业现状
证券交易系统中,行情一直是最重要的环节之一。一般情况下,交易所向会员单位提供行情网关程序,会员单位使用行情解码程序,与交易所行情网关程序连接,然后解码收到的行情数据,进行行情处理,最后分发给行情使用者。行情系统包含如下几种类型:传统的集中式行情系统,低延时的组播行情系统和基于FPGA的硬件行情系统等等。
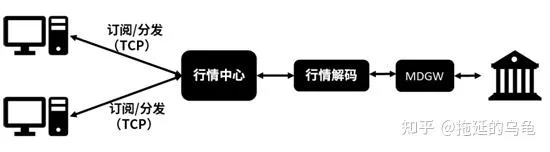
传统的集中式行情分发系统,如下图所示。采用软件实现的行情解码程序,连接交易所行情网关MDGW(Market Data GateWay) ,建立TCP连接。行情解码程序接收MDGW发送的原始行情数据,进行解码,然后将解码后的数据发送到集中的行情中心。行情中心负责行情数据的落地以及分发,将数据落地到历史行情库中,然后将实时数据分发给订阅行情的客户程序。整个链路都是采用软件TCP传输。在这种集中式行情系统中,从交易所MDGW发送原始数据到客户收到解码行情,时延消耗为几百微秒至几毫秒。
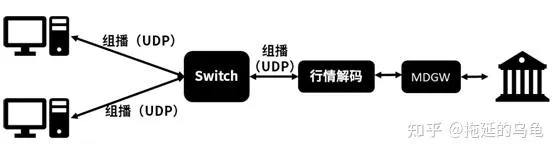
低延时的组播( UDP)行情系统,如下图所示。采用软件实现行情解码,连接交易所 MDGW,建立 TCP连接。行情解码程序将解码后的行情采用组播( UDP)的方式,发送到行情组播私网中,在行情组播私网中的客户将接收到组播行情。与集中式行情系统不同,这种低延时组播行情系统不适用于远距离传输,一般在交易所托管机房内部署。这种行情组播系统多采用低延时网卡、搭配低延时交换机和高性能服务器。行情传输时延能达到几微秒到十几微秒,接近于纯网络通信的时延。
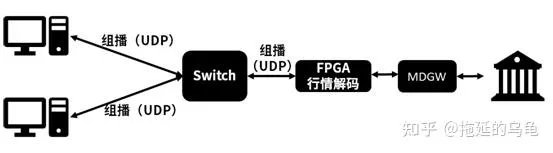
基于FPGA的硬件行情系统,如下图所示。一般采用具备网络通信功能的FPGA板卡和x86服务器构建的异构平台,进行行情解码和行情分发。FPGA一般采用硬件描述语言开发。通过CPU负责行情解码控制面,FPGA负责数据面。FPGA与MDGW建立TCP连接之后,接收原始行情数据,在FPGA卡内进行行情解码和组播分发,不经过CPU处理。最后将行情数据发送到行情组播私网中,加入行情组播私网中的客户将接收到硬件组播行情。由于网络数据不经过CPU侧DDR处理,因此行情传输时延可以到几百纳秒到1微秒。
软件开发人员单纯依靠CPU、低延时网卡和低延时开发套件等,越来越接近时延瓶颈,再考虑到操作系统的调度和时延抖动,很难进入(几)微秒甚至纳秒级的竞争。FPGA(可编程逻辑阵列),作为可编程硬件,可以处理网络数据,内部的大量逻辑资源可以重新「编程」,实现业务逻辑,而且时延抖动小。
异构加速平台
FPGA开发大多采用硬件描述语言,开发周期长、难度大,软件开发者很难进入到这个领域。但是随着FPGA加速应用的普及,Intel(英特尔)和Xilinx(赛灵思)也相继推出了OpenCL(Open Computing Language)和HLS(high-level synthesis) 开发套件,支持采用类C语言进行FPGA开发。
本方案采用的是Intel的PAC(Programmable Acceleration Card)卡和x86 CPU构建的异构加速平台。PAC卡内置的是Arria 10GX FPGA,逻辑资源非常多。该异构平台支持使用OpenCL进行开发和运行。

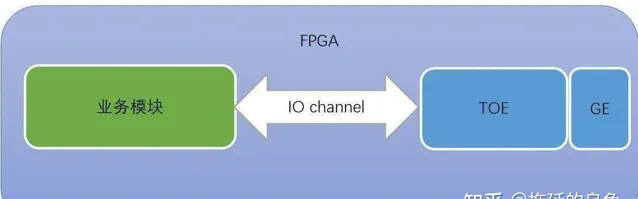
CPU主机侧采用C++开发行情解码控制面程序,FPGA设备侧采用OpenCL C(基于C99)进行数据面开发。将TOE(TCP over Ethernet)IP(Intellectual Property)核嵌入到FPGA中,FPGA就具备了网络通信的功能,可以支持到传输层协议解析,然后将数据交给应用层处理。这里,应用层就是采用OpenCL C开发的业务程序,即行情解码。TOE与业务模块通信,采用IO-channel的方式,数据位宽128bit,也就是16Bytes。
协议分析
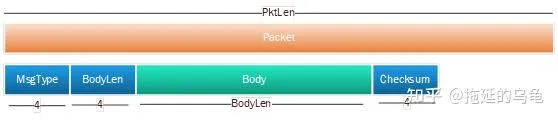
深交所的行情,从MDGW发送给下游的解码程序,采用TCP连接,因此,在应用层采用分包协议。发送给下游的字节流中,分包协议如下所示。每个应用层行情包,是一个完整的业务报文,可以解码出一类行情信息。一个应用层行情包分成三个部分:消息头,消息体和消息尾。消息头包含4字节消息类型MsgType(如300111快照,300192逐笔委托等),4字节消息体长度BodyLength。消息体就是消息类型对应的行情数据。消息尾定义了消息的校验和,计算范围从消息头开始一直到消息体结束。每解完一个应用层行情包,后面紧跟的就是另一个行情包,根据消息类型解析后续的消息体。 行情中所有整数字段均为大端字节序。
以300111行情快照为例,如果解析到MsgType为300111,则后续的消息体使用300111对应的Binary协议进行解析。依次从消息体中解析OrigTime(数据生成时间),ChannelNo(频道代码),MDStreamID(行情类别),SecurityID(证券代码),对应的扩展字段等等。

目前PAC卡中的TOE模块,输出数据的位宽为128bit(16字节),为了充分利用FPGA的流水线处理特性,业务模块从IO-channel中每取到16字节进行一次处理,边接收,边解码,而不是收到一个完成行情包再解析(这样会引入较多的时延)。当然,也可以将16字节拆分成8字节或是1字节进行流水线处理。下图为深交所行情快照按照16字节摆放,每一个时钟周期数据对应的内容。

OpenCL行情解码
异构平台程序分主机程序和设备程序。主机程序指运行于CPU上的软件程序,设备程序指运行于FPGA内部的业务功能模块(OpenCL编写的业务模块,非TOE)。主机和设备通过OpenCL运行框架通信,进行任务分配。网络功能则通过TOE对应的驱动程序,由主机侧调用,通过TOE与交易所的MDGW建立连接。
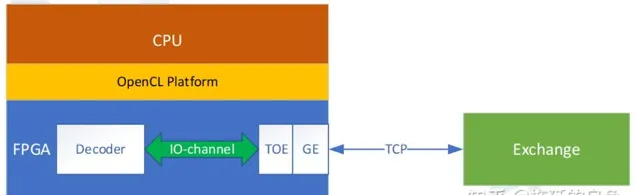
设计上分控制面和数据面。CPU相对灵活,编程容易,适用于逻辑控制。FPGA虽然可编程,但是功能固定,适合高速数据处理。因此CPU负责控制面,FPGA负责数据面。
控制面
- 管理上下游链路。与上游交易所MDGW建立TCP连接,向下游组播私网发送组播行情。
- 管理FPGA上的任务执行。基于OpenCL Platform,下发Kernel任务给FPGA,包括FPGA初始化和释放、MDGW登录、行情解码等等。
- 监控行情解码。监控上下游连接状态,监控行情解码的收发包个数。
数据面
- 对接TOE。利用IO-channel与TOEInput/Output通信,解析和封装TCP/UDP报文。
- 行情解码。进行TCP报文的处理、分包,Binary协议(行情快照、指数快照、逐笔委托、逐笔成交)解析。
软件行情解码,一般是收到一个完整的业务报文,再进行协议解析。由于CPU本身有高速缓存cache,而且主频比FPGA高一个数量级,解包效率非常高。但是,数据是从网卡到操作系统协议栈(若使用kernelbypass网卡,则进入用户态协议栈),再搬移到DDR中,进行行情解析,存在多次数据搬移和拷贝。
FPGA行情解码,整个行情解码过程中,数据从交易所MDGW到FPGA板卡GE口,进入TOE,TOE将数据传入Decoder业务模块,Decoder将解码后的数据又通过TOE、GE口发送到对应的行情组播私网中。数据流只在FPGA板卡内部,不会进入FPGA板卡的片外DDR,更不需要通过PCIe搬移到CPU侧DDR,因此省去很多数据搬移的开销。
Kernel解码逻辑设计时需要考虑到流水线的合理编排,充分利用FPGA硬件资源。TOE和业务Kernel之间的IO-channel通道位宽128bit(16Bytes),即TOE每个周期向IO-channel输入和读取16Bytes数据。为了获得最低延时,业务模块需要同时进行数据接收、行情解码和组播发送。快照解码的伪码如下。
在一个while循环体中,不停的从toe_in这个IO-channel中读取数据,然后进行数据解析。如果这个时钟周期的数据为应用层行情头,即index等于0,则可以从中解析出msgtype、msglen和orig_time字段;收下一时钟周期的数据,可以解析出证券代码SecurityId;收到最后一个时钟周期的数据时,解析完。封装解码后的行情数据,发送到中间的缓存channel(data_out)中。并行运行的发送Kernel就一直从data_out中取数据,取到数据就通过toe_out发送出去。

TOE协议的报文分析。TOE输出的每个应用层报文会包上一个TOE头,用于分包,并提供会话、长度信息。紧接着的数据就是应用报文。TOE头中长度字段在0和1字节,长度的高字节在TOE头的第0字节,长度的低字节在TOE头的第1字节。会话ID(cid)在第二字节,TOE一般支持的会话在128以下。其余13字节都是0x55。TOE输入的数据是大端摆放,如果用uchar16数据缓存TOE IO-channel输入的数据,则uchar16的0~15字节对应的是TOE中的15~0字节,相当于数据翻转了。重新翻转之后的TOE数据如下:

性能调优
在使用OpenCL开发时,第一步是功能实现,第二部是性能调优。因为是使用OpenCL开发,gdb调试,所以功能开发所需要的时间相较传统RTL开发少很多。性能调优占据整个开发流程中的一半时间。
II值和FMAX
性能调优时,除功能外,需要关注的指标主要有两个:II值(Initiation Interval)和FMAX(maximum operating frequency)。
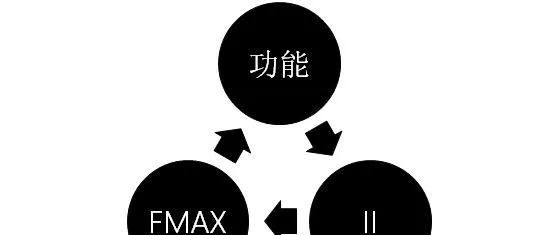
II值表示连续循环迭代之间的时钟周期。FPGA是采用流水线执行任务,一条流水线的吞吐取决于最慢的一个环节,在优化时可以认为II值就是这个流水线中最慢环节所需的时钟周期。如果流水线设计中,某个环节业务过于复杂,无法在一个时钟周期内处理完,则流水线的II值会比较大。II值越大,表明吞吐越低;II值越低,则吞吐越大,时延也越低。一般在低延时应用中,II值目标是等于1,也就是在每个时钟周期都能「吐出」一个任务结果。
FMAX值简单理解就是FPGA运行的时钟频率。FMAX越高,则任务处理越快;FMAX越低,则任务处理越慢。业务模块过于复杂,FPGA在设计和编译时,FMAX就「跑」不上去,导致上板后FPGA时钟频率较低,业务处理慢。
如果FMAX足够低,即时钟周期较长,足够流水线中最慢的环节处理业务,II值总能为1;如果FMAX过高,即时钟周期短,而流水线中最慢的环节无法在一个时钟周期内处理完,则II值大于1,流水线无法在一个时钟周期内输出一个有效数据。如果II值足够大,即流水线中可以容忍在多个时钟周期内执行一次循环迭代(经过多个时钟周期才能输出一个处理结果),FMAX就可以很高;如果要求II值为1,则要求流水线每一个时钟周期都输出一个结果,那意味着FMAX需要降下来,保证流水线的循环迭代能在一个时钟周期内处理完。
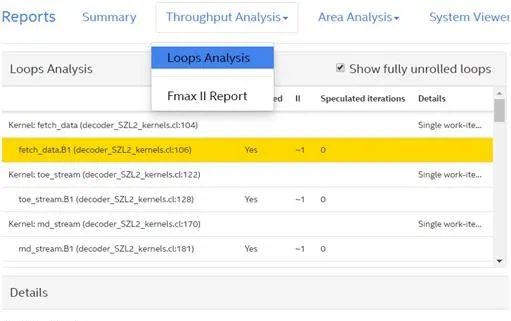
编译器总会在II值和FMAX之间折中。OpenCL程序设计完后,可以在通过Quartus编译生成的报告中查看II值和FMAX。如下图所示,reports中会给出所有模块的II值和FMAX,如果性能不高或者有优化空间,也会指出问题所在。
调优手段
详细的调优手段可以参考Intel官方的【aocl-best-practices-guide】。以下列举在行情解码中用到的一些调优改进方法。
循环展开
使用while进行不定次数的循环,使用for全展开(unroll)进行固定次数的循环。一般低延时应用中,只允许一层不定次数循环,若有嵌套的不定次数循环,II值就不等于1。
例如使用for循环拷贝不定长度的数据。拷贝或者处理num个数据,num<=16,下述写法II值不等于1,因为存在不定次数循环。

改写成如下写法。就能将for循环全展开,且并行执行16个数据的处理。由于逻辑固定,可以在一个时钟周期内完成。

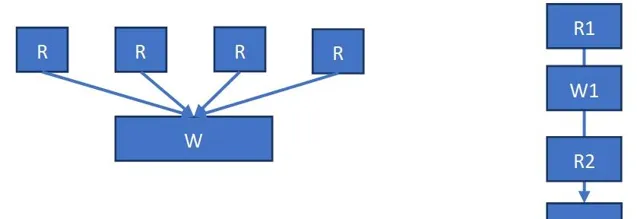
同一变量的读写操作
首先要避免在一个循环体内复用同一个变量(逻辑资源充足,可以定义多个变量)影响编译器优化逻辑依赖关系。
一个循环体内,建议对同一个变量进行多读单写,且写在所有读之前或之后,避免多读多写相互穿插。因为多读单写时,编译器会复制多份变量,这样依赖关系清晰,且多个读代码会并行执行。而多读多写,可能会产生较为复杂的依赖关系,不利于编译器优化。
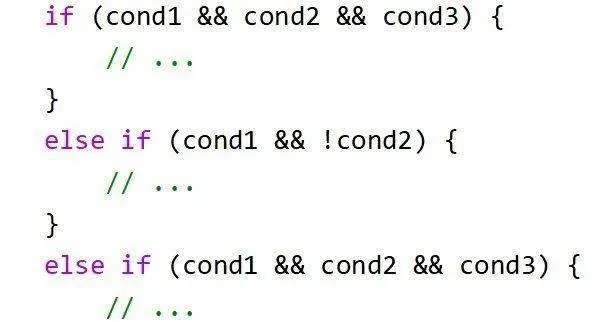
降低IF判断的复杂度
减少if嵌套,循环体内尽量只有1~3层if嵌套,过多的if嵌套不利于编译器理解代码逻辑进行优化。

改写为下面的形式,if中的判断条件会在一个时钟周期内执行完。这样的逻辑更为清晰,便于编译器优化。
结论和展望
基于OpenCL开发的深交所Binary行情解码,是证券领域利用OpenCL进行FPGA低延时应用开发的一次探索,配合高性能低延时的TOE,可以获得接近硬件描述语言开发的性能。使用OpenCL开发FPGA具备很多好处:开发和迭代速度快,可以使用gdb在普通Linux环境进行功能调试;OpenCL编译器也提供详细性能分析报告,便于优化代码性能;还可以调用高性能的HDL或者其他语言开发的库。目前已经完成了深交所Level1/Level2的Binary协议行情解码,包括行情快照(快照和委托队列)、指数快照、逐笔委托和逐笔成交。未来可以在板卡内进行一些指标计算,或者利用Intel的OpenCL FinLib,为客户提供更丰富的行情信息。











