1.三維幾何學基礎知識
關於基礎知識,首先要了解的是剛體運動的基本內容。三維空間的剛體運動通常包括六個自由度,對應的轉換矩陣的表達方式在不同的文獻中有不同的方式,而在學術寫作的時候,不管用哪一種,重要的是一定要保持格式的統一和連貫。此外,轉換矩陣所描述的不是某種運動,而是點在不同座標系的轉換。第二個比較重要的基礎知識是本質矩陣和對極幾何。考慮下列場景:我們用兩個網絡攝影機可以同時觀測到一個特征點,利用匹配的特征點,我們將可以建立對極約束,當匹配的特征點足夠多時,我們將可以求解本質矩陣,比如使用常用的八點法,當求解完成後,我們就可以從本質矩陣中分解得到兩個相機位置相對的位移和旋轉。值得註意的是本質矩陣的自由度是5,因為在位移上,我們遺失了一個自由度的尺度資訊。

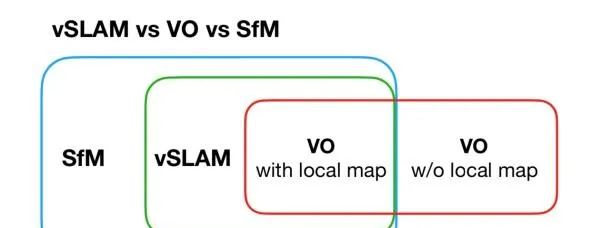
而關於SLAM,它是英文「同時定位與建圖」的縮寫。而有時候,我們還會聽到VO,SfM等概念,而因此容易混淆。對於這些概念,我的理解是,sfm用於基於影像的三維重建,過程可以是線上或者離線,影像的順序可以是連續的,也可以是亂序的;視覺slam一般處理的影像是連續的,並且過程也是線上的;視覺裏程計中有局部地圖生成的模式其實就是slam,而沒有地圖的模式就是單獨的裏程計。雖然我們接觸到的大部份視覺裏程計都是有對應的地圖,但是,也有些情況,比如現在的一些深度網絡可以透過兩張圖片直接訓練輸出相對位姿,這就是單獨的裏程計資訊。
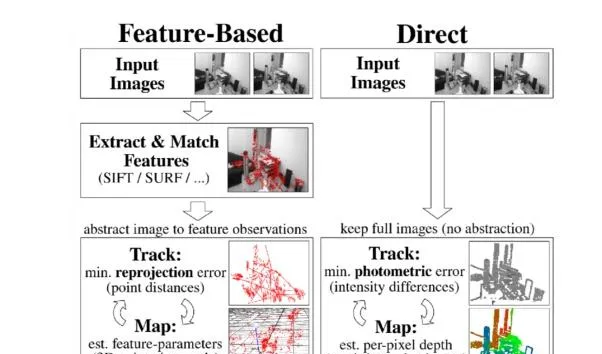
接下來我們來看看特征點法和直接法直接的對比。關於特征點法,通常我們在兩張圖片上找到特征點以及對應的匹配特征點,從而求兩幀影像之間的相對位姿以及特征點的三維位置。當有一個初始的相對位姿估計時,我們可以計算特征投影到另一幀影像的位置,從而可以建立重投影誤差。相比於使用兩張圖片,當使用多張圖片時,重投影誤差則包括所有特征點在所有可被觀測到的幀上的誤差。而針對直接法,我們所關註的誤差稱為光度誤差。如果說特征點法關註的是像素的位置差,那麽,直接法關註的則是像素的顏色差。總結一下,特征點法通常會把影像抽象成特征點的集合,然後去縮小特征點之間的重投影誤差;而直接法則透過warp function直接計算像素點在另一張影像上的顏色差,這樣就省去了特征提取的步驟。
2.直接法的套用
關於直接法的套用,主要介紹的是DSO和大範圍DSO。首先關於直接影像對齊(direct image alignment),針對每一個影像的每一個點,我們需要計算像素點顏色的變化,對應點的尋找需要利用warp function,就是將一個點透過相機的內外參數轉換到另一個相機的座標系中,更周全的考慮還需要將兩張圖的亮度進行一致化處理。然而單目相機還是需要面對一個很棘手的問題,那就是無法恢復尺度資訊,並且往往會出現尺度漂移的現象。為了解決這個問題,一種方式是采用雙目網絡攝影機,對此我們需要使用新的能量函數,添加的最佳化量就是雙目相機另一個網絡攝影機投影到它上面的誤差,值得註意的是,雙目網絡攝影機的相對位置需要已知,並且,透過雙目項的添加,會自然的得到尺度的約束。而實際上,隨著雙目相機和對尺度約束的引入,相比於ORB-SLAM2和深度LSD,大範圍DSO在KITTI等室外場景具備了更好的裏程計效果,而經過反思,我們認為透過將雙目相機用「聰明」的方式加以利用,我們確實可以得到正確的尺度資訊。除了支持裏程計資訊的獲取,雙目DSO還能很好的支持三維重建。

在實作了比較好的三維重建後,接下來值得繼續研究的方向之一就是語意重建。基於視覺SLAM的語意重建的流程包括實作定位和地圖後,透過點雲資訊來進行語意分割,基於分割好的點雲,我們將進一步參數化,抽象化。總之,我們希望實作對於點雲比較簡潔的參數化描述。我們接下來的一個工作是試圖從輸入的影像直接得到想要的語意資訊。對應的輸入包括雙目相機獲取的左右影像,初始的位姿和形狀估計,以及物體的語意分割結果。而誤差的計算則包括兩張圖片光度投影的誤差,和將物體估計的形狀投影到影像上的誤差,以及關於車的形狀和位置的先驗知識。利用構建的誤差,我們可以透過高斯牛頓法進行最佳化。而這裏,涉及到的問題包括構建車輛的模型來進行參數化表達,一種方式是利用有效距離場對於形狀以高維度向量的形式進行描述,然後采用PCA模型進行降維壓縮。而在利用能量函數建立最佳化問題後,我們需要計算亞可比進行二階最佳化,由於待最佳化的變量較多,所以亞可比推導很復雜,不過在我們的論文 DirectShape: Direct Photometric Alignment of Shape Priors for Visual Vehicle Pose and Shape Estimation中,對於所有最佳化變量的亞可比的求解都進行了推導,從而提供了最佳化問題的閉環解,感興趣的同學可以自行閱讀。而實驗效果也實作了很好的場景描述效果,包括在物體被部份遮擋的情況下。

接下來一個主題是關於特征點法和直接法的結合,第一個工作是結合特征點實作的相機的線上光度標定。要理解光度標定,就要理解數碼攝影機的成像過程,首先光源發射到物體上的光會反射到鏡片上,經過鏡頭後,光亮會發生變化,然後打到傳感器上,一定時間內形成能量積累,經過響應函數的處理從而得到對應的光照強度。從物體表面反射的光通常稱為輻射亮度(radiance),而發射到傳感器上的光通常稱為輻射照度(irradiance)。這一過程涉及到三個參數,包括是鏡頭的暗角V,曝光時間E,鏡頭的響應函數f。
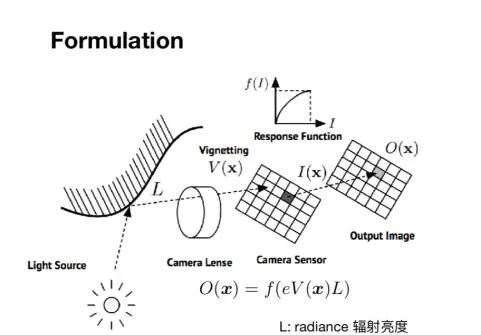
而相機的光度標定的目標就是求得相機的三個參數,並利用這三個參數對於影像進行矯正,從而確保輸出影像的光度一致性。
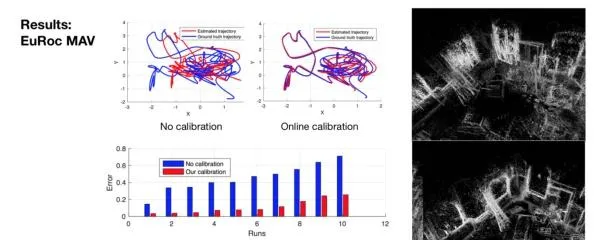
為什麽我們要進行光度標定呢?因為直接法SLAM的假設就是光度的一致性,即對應的點在不同的影像中顏色要一致。已有的方法在進行光度標定時,我們需要至少10分鐘的時間完成全部的復雜操作。而當相機安裝在無人機上,或者曝光時間無法控制時,操作將更加復雜。我們所提出的線上光度標定的方法是基於特征點在不同圖片中對應的觀察,能量函數是所有的點在所有影像中的實際顏色與模型估計出的顏色的誤差和。在定義了能量函數後,我們需要怎樣進行建模呢?首先對於響應函數的建模還是利用主成分分析,我們收集一百個相機的響應函數進行PCA,任意一個相機的響應函數都可以用四個主成分的線性組合來進行描述。對於暗角的建模是基於暗角是完全對稱的假設,並用四階多項式來描述。在對能量函數進行參數化後,我們就可以進行最佳化求解。而實際的效果也證明最佳化參數可以很快收斂成真值。在進行光度標定後,DSO在Euroc等數據集上也實作了更好的定位和建圖效果。
最後一個分享的課題是:如何在采用直接法的同時進行回環檢測?直接法中因為沒有描述子,所以很難利用進行數據關聯和回環檢測,一種思路就是對部份采樣的點添加描述子,在高翔博士的工作LDSO:Direct sparse odmetry with loop closure中,我們把采樣的點一部份換成角點,對於角點我們會建立描述子,從而得到整個影像的描述子,然後就可以檢測回環,進行全域的位姿圖最佳化。而實際效果說明,特征的替換並不會影響DSO的效果,並且還增加了新的回環檢測的功能。此外,還有一種思路是透過直接法得到的點雲進行三維特征點的檢測,並且抽取局部特征點的描述子,從而合並成全域特征點的描述子。
3.未來的工作方向
而關於直接法的局限性,我認為直接法做全域的最佳化是很有挑戰性的,因為沒有描述子,做回環檢測和地圖的重定位不是很直觀。而且在極端的光照條件下,它的魯棒性沒有保證,還有一點就是目前的直接法采樣點都是隨機采樣,這就意味著采樣沒有決定性,這就會為之後的重定位引入誤差。此外,直接法得到的點雲如何得到更具備實際意義的表述形式?因為目前得到的點雲還是無法直接使用的。直接法需不需要儲存歷史影像?特征點法只需要保留特征點和描述子,而直接法如果需要全域最佳化,那麽就需要儲存影像與歷史資訊進行對照,而一旦儲存影像,就會導致儲存數據的增加,那麽這個問題該如何解決?
關於直接法未來的研究方向,一個可行的工作是增加點的描述性,如果能將之前不具備描述性的影像的顏色資訊,換成具備描述性的描述子資訊,那麽將可以開展很多新工作。有了這些東西,我們就可以進行跨季節,跨時間,跨天氣的回環檢測。此外,直接法獲取的點雲質素通常較高,但現在依舊沒有充分挖掘這些點雲資訊的潛力,所以未來如果能夠提取這些點雲的描述子,並且和影像的描述子結合,那麽就可以對場景實作更好的描述性,點雲還有可能的潛在用途就是提供簡潔的場景描述。此外,目前點的采樣具有隨機性,而未來,是否可以實作具有確定性的點的采樣?從而實作更準確的重定位?還有就是直接法的全域地圖該如何更新和維護,現在還沒有解決。











