這取決於怎麽定義「效能」,以及怎麽定義「天花板」 。
我們目前討論的消費級CPU設計,往往不是無限功耗(隨意超頻)或者無限的芯片面積,往往更傾向於在特定功率範圍(約為65W)和特定芯片尺寸(約為100mm2)下,怎麽設計出更好的CPU。所以,在這個問題下考慮超頻效能是不公平且有失偏頗的。
如果要系統回答這個問題,我們應該從CPU效能影響因素開始講起。
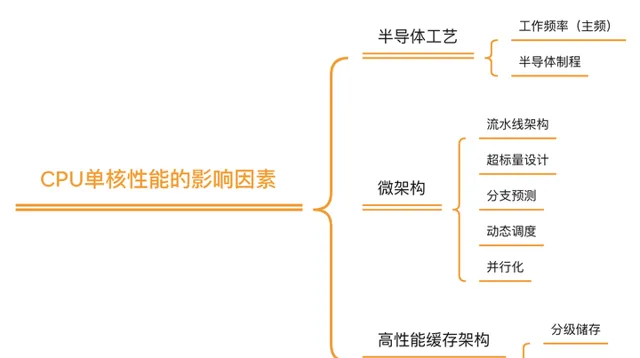
如果我們以目前大家預設的CPU效能衡量標準(CPU單核運算效能)來講, 理論上CPU效能主要由三方面決定:
就CPU效能,一個非常普遍的觀點是,即使(基於矽)的半導體工藝可以繼續演進,但納米級晶體管尺寸帶來的量子效應也已經變得越來越不可忽視, 所以半導體制程帶來的CPU效能提升可能會在5nm左右(就是現在)出現收益遞減 [2] , 這是「CPU效能達到天花板」這一觀點的基礎 。
但是,這一觀點是片面的,因為這種說法僅著眼於工藝進步的邊際效應, 而芯片本身的效能進步並不局限於工藝本身 。在硬件,微架構,緩存架構,芯片驅動軟件等等方面都有太多地方可以對CPU 晶體管利用率,能耗比,極限效能,芯片極限面積,甚至芯片軟件開發時間等等方面做出最佳化,這些最佳化都會對傳統意義上的「CPU效能」產生積極影響。
我可以把它們分為幾類分別討論,期望能夠給大家一個關於芯片效能的更全面的視角。
1. 硬件 –--制程提升帶來的邊際效應越來越明顯,下一步是什麽?
1959年,諾貝爾獎獲得者Richard Feynman在對美國物理學會的大會演講上曾這麽說過,「電腦效能的進步大多來自於電腦元件的小型化,(這些進步)在底部依然有足夠的空間」 [3] 。這裏的「底部」其實就是在說CPU這類通用計算芯片。
考慮到CPU的小型化大多依賴於更小的晶體管尺寸和半導體制程的進步,這條評論本身也其實正在間接暗示摩爾定律推動CPU效能進步(註:這句話早於摩爾定律十幾年)。而在過去五十年時間裏,芯片的發展一直符合這個觀點,或者說,
摩爾定律 。
摩爾定律預測,預計18個月會將芯片的效能提高一倍(即更多的晶體管使其更快。我們可以在這裏解釋的更加詳細一點。眾所周知,半導體電路(特別是CMOS電路)的電路功耗和工作頻率成正比,而工作頻率的提升意味著芯片效能的直接提升(大家可以想象超頻給電腦所帶來的效能增長)。
但是,正如我們之前所說,大多數情況下的消費級CPU在設計時都存在一定的功率範圍。這種功率範圍既不能太高導致整體耗電急劇增長(或觸碰功率墻),也不能太低導致計算能力低下,所以,有沒有一種可能讓半導體芯片在功率不變的情況下直接提升效能工作頻率?
換句話說,我們在期望能透過某些設計來提升CPU的能量效率?
答案是肯定的。

這也是1970年左右,Dennard (MOSFET)Scaling Law 產生的基礎: 在半導體芯片裏,每代將會使晶體管尺寸減少30%,並且同時保持晶體管裏各處的電場恒定 。晶體管尺寸減少(也就是制程提升)會帶來很多好處:
Dennard Scaling Law 帶來的直接預測結果是,在每一代半導體制程進步中,晶體管的密度都翻了一番,效能將提高 40%,而整體系統功耗幾乎保持不變。 如果配合摩爾定律,幾乎等同於每18個月,芯片的每瓦效能將會翻一倍 (見下圖 [4] ) 。
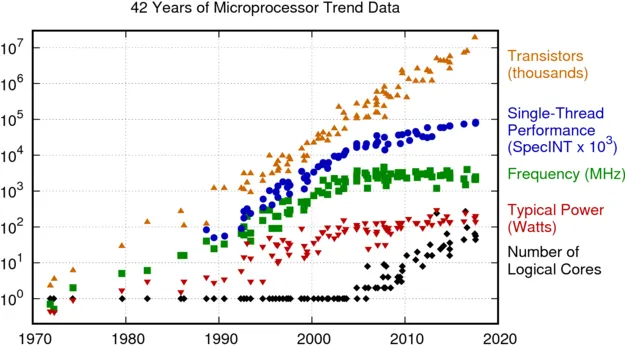
這也是過去二十年間,推動芯片制程進步的主要動力:芯片設計師利用晶體管密度來設計更復雜的架構和晶體管速度以提高頻率,而得益於晶體管密度的提升,設計師們有足夠的空間在合理的功率和能量範圍內同時獲得復雜的架構和更高的頻率。以一種簡單粗暴的思路,甚至可以只依靠晶體管的小型化簡單粗暴添加更多內核,然後透過制程進步帶來的更多「免費」核心來提升CPU效能。
從另一方面來說,更先進的芯片制程不止影響了技術進步,它們也間接影響了電腦的價格(同樣的錢能買到更多晶體管,也意味著能買到更多計算效能)。
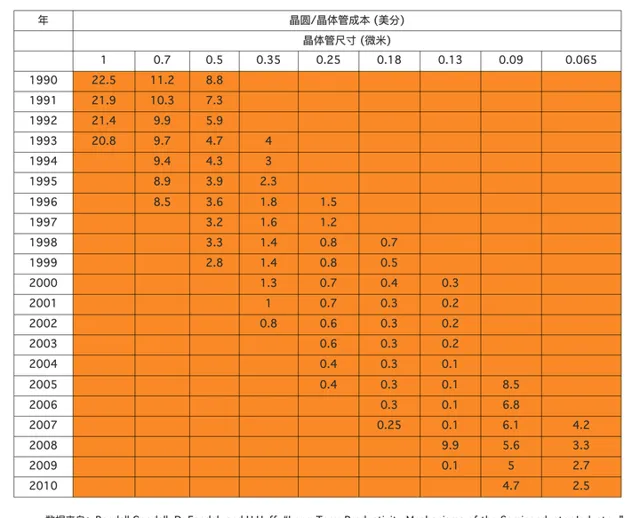
實際上,在20世紀60年代初,一個晶體管要10美元左右,但隨著晶體管越來越小,小到一根頭發絲上可以放1000個晶體管時,每個晶體管的價格只有千分之一美分。據有關統計,按運算10萬次乘法的價格算,IBM704電腦為85美分,IBM709降到17美分,而60年代中期IBM耗資50億研制的IBM360系統電腦已變為3.0美分,具體統計數據見下圖(數據收集自論文 [5] )。
但是在未來,大概率並非如此。
一些觀點認為這代表著是摩爾定律的終結,即「後摩爾時代」的到來。這可以透過芯片領域的國家自然基金重點專案指南得到確認(見下圖): 我們需要在「後摩爾時代」解決低功耗器件,新材料工藝和新架構的芯片設計問題。

從目前來看,在「後摩爾時代」,晶體管制程的進步仍會繼續,但正如之前所說,單位面積晶體管密度增長會不斷放緩,從而對整體芯片效能的影響越來越小。既然如此, 架構方面和軟件方面 的提升就成了目前的效能提升重點,比如更有效的異構多核架構和領域客製處理器,以及目前的一些研究熱點,非馮·紐曼體系結構、存內計算、多芯片封裝等等。
答案是非常正確的,且有很多例子可以證明這一點。這也是芯片設計中的一種比較重要的設計思想---發現程式中的共性特點,並以硬件設計加速相關共性計算 [6] 。
在電腦歷史上, 領域客製處理器 最經典的例子是獨立顯卡的出現。隨著當年影音和影像處理業務越來越多,通用的CPU不能非常有效的處理圖形影像所需要的浮點型數據運算,所以顯卡就此誕生。
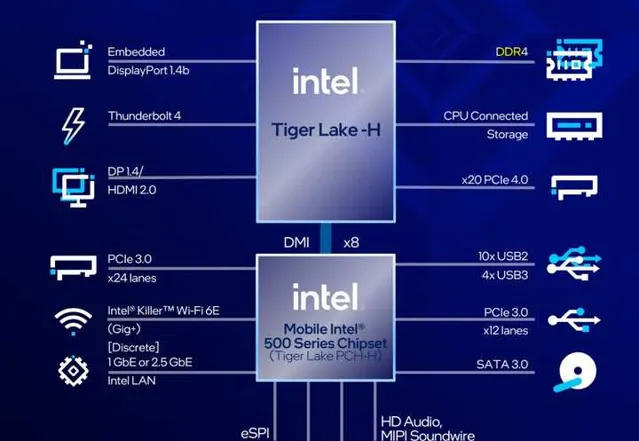
此後也隨著多媒體內容逐漸增多,顯卡市場也得到了更蓬勃的發展,而且所支持的指令集和顯卡架構也在不斷升級。在Intel前幾天釋出的第11代英特爾酷睿處理器高效能移動版(p5)芯片組裏,Iris Xe 整合顯卡可以支持更快捷的影片轉碼和多媒體處理,這類領域客製處理器(整合顯卡)可以幫助p5完成影片處理的硬件加速,並且透過更多的智能加速引擎為影音處理和遊戲提供更好的效能。

領域客製處理器 另一個非常典型的例子是人工智能芯片的興起,以及(通用處理器)中對人工智能相關指令集的支持力度加大。在芯片設計領域,判斷一類套用是否需要專用芯片支持,需要非常大規模的熱點代碼分析。
08年左右人工智能相關演算法方興未艾,但是一些公司曾經透過大規模的代碼分析出人工智能程式碼運算正在大振幅增加,所以需要設計專用硬件架構來提升人工智能計算效率。同樣,在Intel 第11代英特爾酷睿處理器高效能移動版(p5)芯片組裏,Intel也透過抽象出Advanced Vector Extensions指令集來大振幅加速電腦所需要的人工智能影像套用,透過Gaussian & Neural Accelerator (Intel® GNA)來提升人工智能語音處理速度。
隨著制程提升帶來的邊際效應越來越明顯,硬件方面的提升更多的可能會著眼於在特定面積下的領域客製處理設計,以及更有效的多核心通訊方式;當然,半導體材料和工藝的飛躍性進步依然有可能。
2. 演算法以及緩存
在很早之前(2010年左右),白宮總統科技咨詢委員會就曾經做出過論斷,在CPU效能最佳化上,演算法帶來的增益已經遠遠超過提升處理器速度所帶來的增益 [3] 。所以,一個普遍的觀點是, 上層的演算法和排程方法會成為CPU效能提升的下一個關鍵點 。
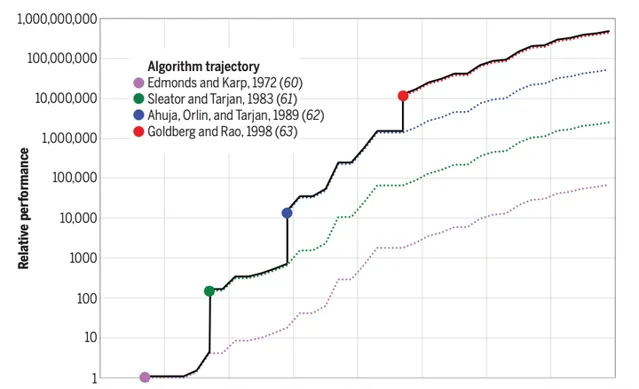
而另一個原因是,演算法實作嚴重依賴於數學領域的建模和抽象,大多數問題往往無解或者暫時無法建模,只有少量問題有演算法加速的空間。換句話說,演算法的最佳化不同於芯片制程進步,它是離散而且充滿了偶然性,這給相應的CPU效能提升帶來了一定的偶然空間。
可以這麽說,演算法部份能夠給CPU效能帶來多少提升,很大程度上依賴於這段時間內解決了多少問題。如果大家看上圖,就會發現在某些年份裏,CPU效能提升是呈現階梯狀的,這正是因為當年演算法領域出現了突破性進展。
作為主要研究演算法的科研民工,其實我可以在這裏加上一句,大多數演算法進步也往往會因為假設條件過強,導致無法直接套用於實際工業中,演算法和實作之間依然存在非常巨大的鴻溝。
但是,即使如此, 我們依然可以想象到,演算法的進步空間並沒有受限,它依然可以給CPU效能帶來更多提升空間 。
3. 軟件和生態
如果大家對軟件行業有所了解,就會發先隨著電腦普及,高級程式語言(特別是非常簡單的手稿語言)變得越來越流行,比如Python。但是,這些程式碼本身其實是非常低效的。
前段時間Science上的一篇文章 [3] 曾經指出,目前的高級程式語言的執行效率非常低下,如果我們用硬件實作相應的計算方式(以矩陣計算為例),那麽速度提升可以達到數萬倍,這是非常巨大的提升空間(見下圖)。
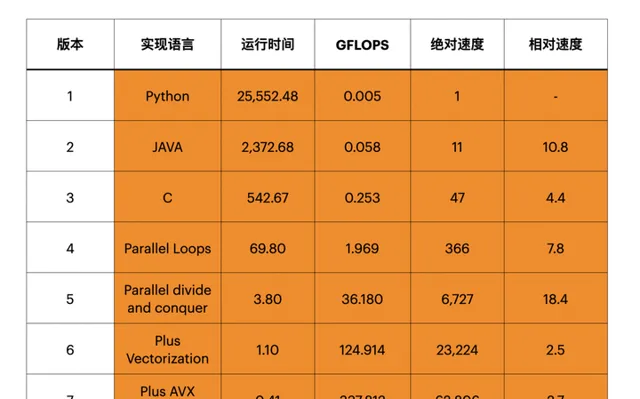
高效能程式碼對CPU的效能提升有著極大的幫助,但是因為其耗時比較長,目前暫時沒有太多關註。這導致我們即使能夠看到這些效能提升空間,也暫時難以有效利用。
其中一個非常重要的原因是,演算法設計需要人工思考,而且大多數人無法熟練從高級程式語言掌握到組合語言,如果我們所有的演算法都透過設計專用電路來加速的話,流片成本高昂到無法承受。
此外,隨著目前的芯片硬件架構設計越來越領域化,高效能的程式碼可能會更加難以編寫。所以,如果摩爾定律或者CPU效能越來越難以進步,可能會出現更多硬件和軟件工程師共同設計程式碼,來最佳化相應的軟件效能 [7] 。
從另一方面上說,芯片本身需要軟件驅動,而軟件的執行速度並不是唯一衡量指標。事實上,對於越來越多的軟件開發者來說,他們更需要的是減少軟件開發時間,而不僅僅是「高效能」的計算水平。
這就是「CPU生態」的一種。CPU和芯片公司總是可以透過向開發者提供更簡單的開發套件, 來提升(或者有人說是壓榨)CPU效能 。大公司往往有更加充足的精力來建設相應生態,Intel應當是其中非常值得提及的例子。
p5提供了20通道的PCI-E介面,以及外置WiFi6芯片,這些外置介面和套件都可以為軟件開發者提供更簡單的開發方案和開發套件,從用更簡單的指令集支持更多套用。從指令集來看,基於X86的指令集可以給第11代英特爾酷睿處理器高效能移動版(p5)提供非常良好的編譯器生態,這又大大降低了開發成本,也可以透過原生提供更多豐富的介面,可以原生支持更多器材,從而方便使用者擴充套件。
從另一方面來說,對生態的擴充套件也可以抽象出更多行業共性軟件需求,提供更多有價值的高效能程式碼和指令集,從而進一提升和挖掘CPU效能,這是另一種CPU效能提升空間。
例如,大多3A遊戲都深度支持Intel的指令集,從而提升軟件使用效率;透過與Killer網卡的深度支持,也可以提升CPU與網卡之間的排程效率,提升使用者的遊戲體驗。

Ending:
或許在可見的未來,芯片微架構,片上網絡通訊,領域客製處理器,或者本文中未提到的更多芯片最佳化技術可以給CPU帶來更多效能提升。這些最佳化技術曾經在過去幾十年內,在intel CPU中整合了數十上百種,例如超純量,亂序執行,超執行緒,硬件虛擬化,大頁面等等。
又或許,在未來幾年內,演算法部份和高效能程式碼研發會出現更多突破性,直接影響到使用者的體驗。目前科研領域可能會期望更多來自材料領域的進展能夠實際使用,影響到消費級CPU,這些都是未來可能的發展方向。
正如大多數芯片從業者都認為,目前的摩爾定律正在接近末尾,但是這並不意味著CPU的效能提升就會停止。未來雖然不可知,但是CPU效能的提升並不會因為制程的收益緩慢而停止。
參考
- ^ Borkar S, Chien A A. The future of microprocessors[J]. Communications of the ACM, 2011, 54(5): 67-77.
- ^ R. Merritt, 「Path to 2 nm may not be worth it,」 EE Times, 23 March 2018.
- ^ a b c Leiserson C E, Thompson N C, Emer J S, et al. There’s plenty of room at the Top: What will drive computer performance after Moore’s law? [J]. Science, 2020, 368(6495).
- ^ Rupp K. 42 years of microprocessor trend data[C]. GitHub. 2018.
- ^ Randall Goodall, D. Fandel, and H.Huff, 「Long-Term Productivity Mechanisms of the Semiconductor Industry,」 Ninth International Symposium on Silicon Materials Science and Technology, May 12–17, 2002, Philadelphia, sponsored by the Electrochemical Society (ECS) and International Sematech.
- ^ a b 多核之後,CPU 的發展方向是什麽? - 包雲崗的回答 - 知乎 https://www.zhihu.com/question/20809971/answer/1678502542
- ^ President’s Council of Advisors on Science and Technology, 「Designing a digital future: Federally funded research and development in networking and information technology」









