
笛卡爾說:「我思,故我在。」
思考是文明存在的根本,是人類探索未知的永恒追求,現在也成了大模型技術演進的一個重要方向。
自OpenAI在9月中旬悄然釋出o1模型後,一系列推理模型陸續開放測試。比如通義千問的QwQ、deepseek的R1、Kimi的K1以及智譜剛剛釋出的GLM-Zero的初代版本GLM-Zero-Preview(智譜清言同步上線了智能體「Zero推理模型」)。
正好到了年末,我們萌生了舉辦一場推理模型「年終考試」的想法。
在「考試」正式開始前,先來簡單科普下推理模型的特點:相較於基座模型,推理模型在回答問題前會像人類一樣進行更長時間的「思考」,不斷驗證和糾錯,更擅長編程、數學、科學等任務。
所以,這是一場面向「理科生」的考試。
需要說明的是,我們沒有使用AIME2024、MATp00等專業的數據集,也無意對各個推理模型進行專業測評和排名,僅適用於多數人在日常生活中可能遇到的問題。
譬如給孩子輔導作業、應付面試時的「奇葩問題」、和朋友一起玩劇本殺時的推理遊戲等等,和大家一起探索各個推理模型的「長項」和「短板」。
考試規則
一共有六道考題,分別用高三數學的單選題、多選題和計算題測試模型的數學計算能力,用一道常見的編程題目測試模型的編程能力,用一道邏輯問題和一道海龜湯問題測試模型的推理能力。
分數評定分為三個維度,最終根據推理結果(占比60%)、推理過程(占比25%)、推理時間(占比15%)加權平均。考慮到單次測試存在的不確定性,滿分為100分,兜底分數為60分(即使做錯了也有60分)。
考生名單:OpenAI o1、通義千問QwQ-32B-preview、deepseek深度思考(R1)、Kimi視覺思考版(K1)和智譜GLM-Zero。
下面,考試正式開始。
鑒於測試的過程比較無趣,我們把5個模型的測試錄屏放在了影片中,感興趣的小夥伴可以點選觀看,也可以直接檢視最終的「考試」結果。
第一題:單選題

考慮到不少人曾經拿高考真題測試,為了防止可能的「作弊」行為,我們從【2024屆浙江省鎮海中學高三下學期期中數學試題】篩選了一道單選題目進行測試。(難度的話,至少本科畢業十年的我們是不會做的。)
第一題成績揭曉
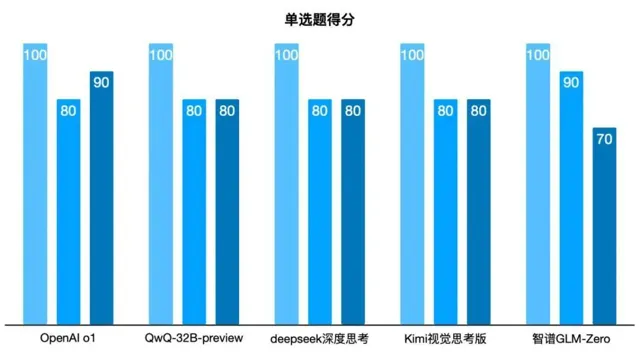
五個推理模型均給出了正確答案。
其中o1模型的推理速度是最快的,推理過程簡單高效,直接給出了計算過程和結果;可能是剛上線的緣故,GLM-Zero的推理速度相對慢一些,但推理過程是最符合人類思維的(在思維鏈中可以清晰地看到自我反思和最佳化、將復雜問題分解,並嘗試用不同方法解決問題),可以作為解題的參考答案。另外三個模型的推理速度比o1稍慢,但在結果和推理過程上可以和o1媲美。
第二題:多選題

題目來源和單選題一樣,難度有所增加,更考驗模型處理復雜問題的能力,以及思考的方式和過程。(PS:我們在考前進行過類似題目的測試,部份模型每次都只給一個答案,所以在正式考試時特意給了多選題的提示。)
第二題成績揭曉

五個推理模型中,只有三個模型給出了正確答案。
o1、GLM-Zero和QwQ回答正確,Kimi視覺思考版只給出了一個正確選項,deepseek深度思考的回答是「沒有正確答案」(排除了影像辨識問題)。在三個回答正確的模型中,GLM-Zero和QwQ表現出了不俗的歸納與演繹能力,提供了詳細的解題過程,並透過反思進行多次驗證,而且GLM-Zero的推理速度比上一題提升了不少。o1沒有顯示思考過程,直接給出了答案。
第三題:計算題
這是一道AI擬定的題目,因為表述有點「模糊不清」,但又不乏邏輯自洽,審題不仔細的話,很可能給出錯誤答案。(畢竟我們當年就在高考試卷上吃過「馬虎」虧,也要讓AI嘗嘗什麽叫審題要認真!!!!)
第三題成績揭曉
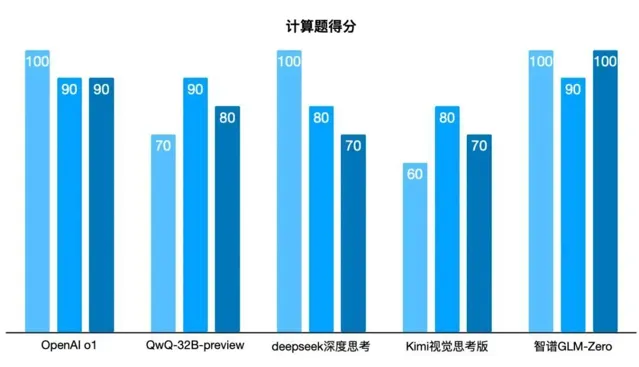
和預料的一樣,有兩個模型「翻了車」。
這道題不僅僅計算,還考驗模型的思考過程,能否辨識中題目中的邏輯漏洞,找到最合理的假設。GLM-Zero在速度上「逆襲」了,整體表現比o1的表現還要優秀。deepseek深度思考的推理過程看起來最完善,考慮到了多種可能,最終給到的是最合理的答案。Kimi和QwQ也考慮了多種可能,但在邏輯漏洞的理解上出現了偏差,最終沿著錯誤的方向進行計算,導致計算結果錯誤。
第四題:編程題
由於我們不是程式設計師,對程式碼的認知停留在了大一的C語言入門階段,所以選擇的編程題目比較基礎,主要考驗程式碼的合理性和可用性。(如果你是程式設計師的話,希望進行更深度的測試,並將結果同步給我們。)
第四題成績揭曉
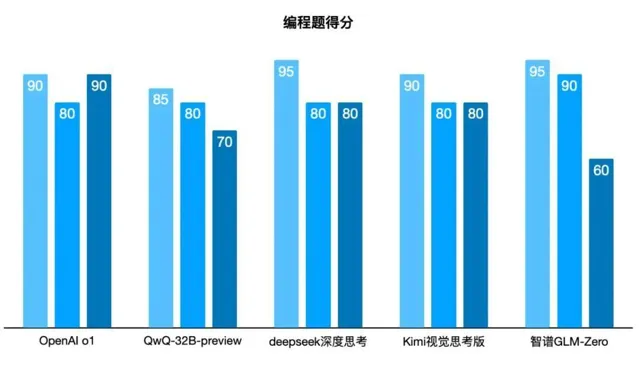
五個推理模型都達到了及格分。
其中GLM-Zero和Kimi的程式碼解釋最為詳細,雖然程式很簡單,依然進行了逐行解釋,對新手程式設計師非常友好。o1模型照舊簡單高效,deepseek給出了兩種不同的實作方式,且均測試有效。就推理速度來看,GLM-Zero考慮到了更復雜的測試情形,反復推理驗證,導致耗時比其他模型長了不少。
第五題:推理題
據傳是微軟的面試題,主要考驗面試者的邏輯思維和判斷能力,推理模型能否透過微軟的面試呢?(本來打算用「牛過橋」的問題,據說是華為的面試題,考慮到邏輯性和答案的一致性,最終還是選擇了燈泡問題。)
第五題成績揭曉

也許是問題過於「經典」,五個模型均順利過關。
其實也意味著,五個模型在推理上都有著不錯的能力。就細節上來看,Kimi「不小心」出現了格式混亂,GLM-Zero和o1都在極短時間裏給出了合理的推理過程和正確答案。之所以在得分上有差距,原因是deepseek和QwQ都特意補充「確保燈泡是白熾燈」,彌補了題目本身的缺陷,在邏輯上更加合理。
第六題:海龜湯題
海龜湯問題的答案通常是開放的,涉及不同領域的知識,模型需要對語言細節進行精確理解,並在回答中清晰地表達推理過程。同時需要從表面資訊推匯出隱藏的邏輯,要求模型能夠分析隱含的資訊並進行深度推理。
第六題成績揭曉

海龜湯題沒有標準答案,主要考的是推理結果的合理性。
o1模型終於「翻車」了,將問題理解為了「腦筋急轉彎」,而且推理幾乎沒有邏輯;deepseek陷入了思考死迴圈,等待了4分多鐘後,我們被迫停止了測試;kimi、GLM-Zero和QwQ的表現不相上下,只是Kimi再次出現了格式混亂。遺憾的是,作為「理科生」的推理模型,都沒有進行富有創造性的故事描述。
考試小結
我們按照文初提到的考試規則,進行了平均分的計算,考慮到單次測試的偶發性(比如將多選題拆解為單選題,進一步測試兩個「翻車」的模型,最終都給出了正確答案),可以說各個推理模型並未拉開太大的差距,並沒有陷入同質化,而是各有所長。
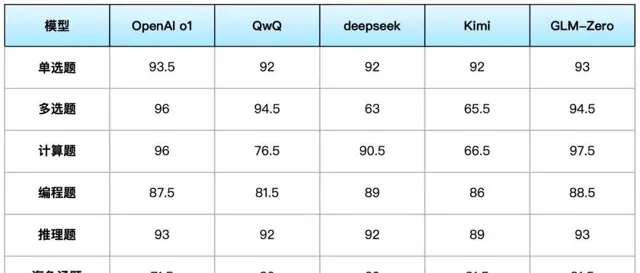
o1模型勝在推理速度和推理正確率;QwQ-32B-preview的表現中規中矩;deepseek深度思考在數學計算和編程方面表現優秀;Kimi視覺思考版「自我反思」能力強,在發散問題上的邏輯自洽性最佳;GLM-Zero在數學計算、編程和推理上的綜合表現不輸o1,可以說是目前國內最好的推理模型。
不過,Open AI已經釋出了o3模型,整體效能比o1提升了20%,國內的幾個推理模型仍然有很大的提升空間。其中智譜已經公開表態將持續最佳化叠代強化學習技術,並將推出正式版的GLM-Zero,將深度思考的能力從數理邏輯擴充套件到更多更通用的技術。
寫在最後
正如OpenAI的介紹o1模型的網誌文章裏所提到的:「我們通往AGI的路上,已經沒有任何阻礙。」
推理模型不僅能夠模仿人類思維,還能跨越知識領域,將資訊整合並生成新的知識,這正是AGI實作通用性的基礎。
相較於我們的「單題測試「,推理模型在產業中落地的可能更大。比如在金融、醫療、法律等決策過程常涉及多變量權衡的領域,推理模型可以分析大量數據、找出相關性,並提供最佳化的解決方案。
以醫療場景為例,基於推理的診斷模型可以幫助醫生快速排查可能病因並建議治療方案,從而提高診斷效率;再比如智譜在AutoGLM上示範的人機協作場景,推理模型能夠更好地理解人類的意圖、預測需求、並主動提出建議,將進一步提升Agent的能力,幫助使用者解決更多類別的問題。
可以預見,2024年是大模型落地套用的元年,在推理模型的賦能下,2025年將是AI進一步提質增效的一年。











