「端到端」是不是撕開完全自動駕駛的那道裂縫?
流量/聲量這麽大,大家都創造條件上,

辣應該是的光吧,至少是在聚光燈下的。
說是曙光/微光,是因為這道光真的能照進來的話。
可能意味著:
最終世界模型的路,真有可能走通
。
一個可解釋的一端式端到端,效能表現類人類、穩定、可靠的話。
確實是一道微光。
和現在搭積木(場景),以量取勝的自動駕駛相比。
端到端最大的區別在於。
有一點點摸到,
直接理解物理世界的那道坎
。

就像,看劇,不需要字幕組:
直接生吞物理世界這個「生肉」是生吞, 全量的、瞬息萬變的、包含小概率事件 的現實世界。
怎麽生吞的:
「端到端」是透過一個
單一
的神經網絡模型直接從傳感器輸入到控制輸出。
這樣能簡化多個模組之間的復雜互動和資訊傳遞過程。誤差積累也就少了,計算效率也提升了。
對比現在傳統的架構:用分模組的方法,將感知、預測、規劃和控制等任務分別由不同的演算法模組處理,每個模組之間透過介面傳遞數據。
雖然降低了開發難度,但容易導致資訊傳遞損耗、誤差累積以及計算延時。
可以快速的搭起下限不低的自動駕駛,但是天花板隱隱也就在上頭了
。
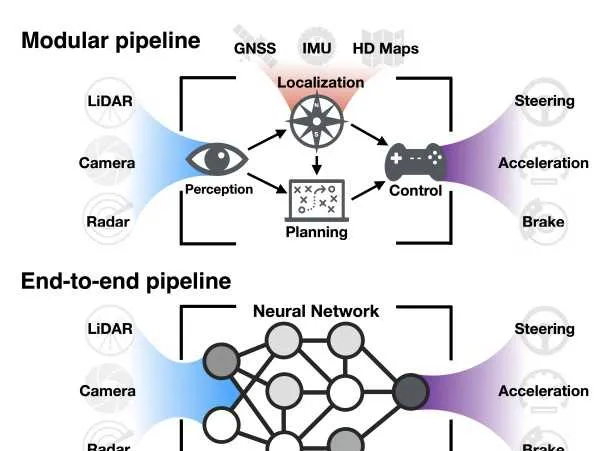
而端到端架構則透過深度學習模型直接處理原始傳感器數據。
關鍵,衍生出了
全域最佳化和泛化
的能力
所以,端到端,是隱隱摸到
但為什麽是
隱隱摸到
,能不能生吞現實世界?
八戒吃人生果那樣可不行。
得
可解釋
,這是目前最大的難題。
目前也有一些方案來攻克 可解釋性
多模態大模型
:
牛津大學提出的RAG-Driver透過使用多模態大模型的上下文學習,提供人類可理解的解釋,增強自主決策的可信度和透明度。
類似於給程式碼寫一個閱讀性很強的文件?
從演算法建模前、中、後三個階段插手
:
在演算法模型建模前、建模中與建模後三個階段賦予模型從始至終的可解釋性。
類似於,每一個模組都「打印」出來,做過程檢驗?
但,這與一段式端到端是不是背離的。
但是底層的,需要超量的高質素數據及仿真/實車驗證。
要靠時間,不能壓縮的時間。
希望,這道光快點照進來吧。











