2023年全球最大的科技变革,来自于Open AI推出Chat GPT,不仅是自然语言处理技术的飞跃,更带来了人机交互方式的变革。意味着机器可以通过深度学习,模仿人类思维,能够更好地理解问题,同时给出较为准确的答案。除了能回答问题,还可以写作、绘图、制表、数据分析、图片分析等等,之所以Chat GPT无所不能,都离不InstructGPT算法架构开发的大型预训练语言模型。那大模型如果应用到汽车上,是否会带来自动驾驶机会的快速迭代。

1、马斯克与Open AI的「感情纠葛」不断,成立xAI开始大模型训练,反哺特斯拉自动驾驶能力
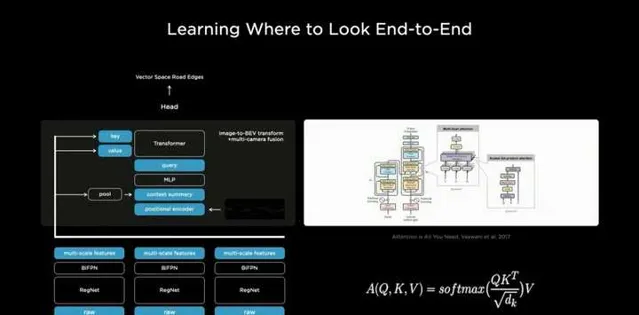
自动驾驶领域,特斯拉率先引入BEV+Tranformer大模型,与传统2D+CNN小模型相比,不仅车辆的提高感知能力,让模型不在机械的学习,而是学会总结归纳而不是机械式学习。以便快速在复杂环境中做出合理决策。
但马斯克并为止步,2015年马斯克与OpenAI现任首席执行官奥特曼合作,建立了自己的人工智能实验室,早期阶段,马斯克和奥特曼显然十分默契,两人一致认为,拥有大量相互竞争的人工智能系统更有利于构建人工智能安全体系。2018年马斯克离开了OpenAI的董事会。时隔多年后,马斯克在一次采访指出,OpenAI脱离了他原本的想法,开始以营利为目的并将代码闭源。

于是,2023年7月马斯克创办人工智能公司xAI,最初的12名员工中有7名来自于谷歌和OpenAI。马斯克也公布了他对xAI的一系列规划,包括新公司即将发布一款工具,将和特斯拉、推特协同合作,并抛出了xAI的宏大目标,即了解宇宙「到底发生了什么(what the hell is really going on)」。

xAI将在前沿芯片领域、AI软件方面与特斯拉进行合作,包括特斯拉自研的Dojo超级计算机,特斯拉一直使用户车辆视频和数据来训练这套超算系统。xAI还将使用推特的数据来训练自己的模型,借此构建「最具好奇心」的AI系统和产品。而这种「互惠互利」的关系,也会加速特斯拉自动驾驶能力的不断进化。

2、大模型应用下NOA快速落地,L3及以上自动驾驶进程有望加快
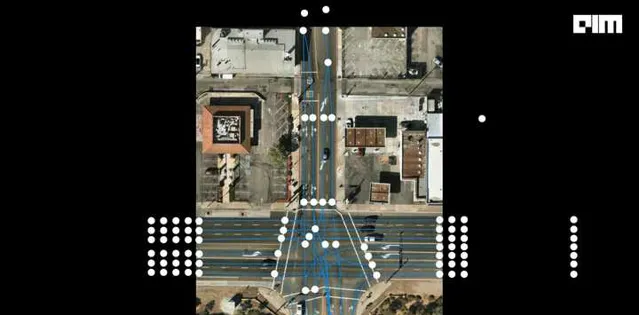
目前特斯拉Model3/Y、小鹏的G6/G9/P7i 、阿维塔11、阿维塔12、问界M5、问界新M7、阿尔法S HI、理想L7/L8 /L9 、智己L7/LS7、腾势N7、蔚来全新车型基本都把高速NOA标配,同时提供城市NOA选配。而且大部分车企开始向不依赖高精度地图的技术路线转变,比如特斯拉的FSD V12、华为的ADS2.0等,可以不依靠白名单,特斯拉Occupancy Networks可实现BEV从2D到3D的优化,可实时预测被遮挡物体的状态;华为ADS 2.0利用道路拓扑推理网络,识别障碍物。
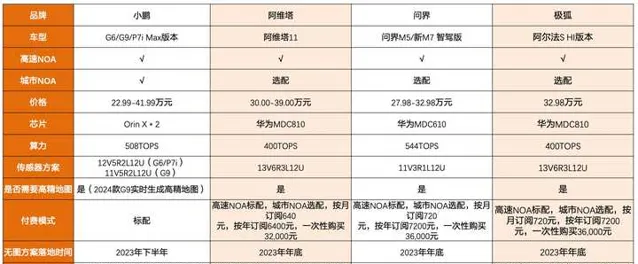
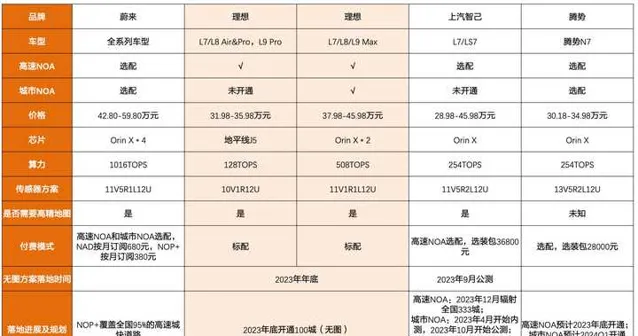
为什么越来越多的厂家放弃了高精度地图?一方面高精度地图成本非常高,华为曾经在上海用了2年时间,采集9000公里地图,仍旧没有把上海覆盖,要是把全国地图都采集下来成本会非常高;二是高精地图作为国家重要的战略信息,不允许完全开放,几个月才允许车企刷新一次,但是大家都知道中国是基建狂魔,道路变化特快,没有办法做到泛化。不依赖高精度地图,才能让高阶的自动驾驶广泛的泛化使用。

3、大模型应用下,对算力和芯片提出更高要求
不依赖高精度地图和白名单的情况下,只依靠普通导航地图,车辆就需要像老司机一样看路识图,像人的眼睛一样看交通标志、看路线,自己推理道路的结构、预判可能发生的情况,大模型催化下,NOA不断从高速道路向城市道路提升。
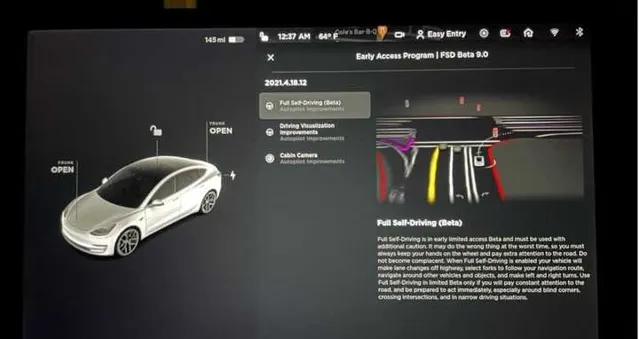
高速道路场景和物体相对固定,比如车道保持、定速巡航、主动刹车、上下匝道、自动变道、超车主动避障等,而城市道路不仅是车主最主要出行场景,而且环境复杂度更高,需要自主识别交通标志、进出环岛、识别车位泊车、红绿灯通行、掉头、并线、自主切换车道、自主切换路线、代客泊车等等,需要同时提升物体识别、感知融合和系统决策算力需求。

实现L2级自动驾驶只需10Tops以下的算力,实现L4级自动驾驶也只需100Tops左右的算力,真正无人驾驶的L5级,则需要1000+Tops的算力。现实中OEM具备城市NOA高阶智能驶功能的车型,算力大多在200-500TOPS左右。模型优化或可降低算力要求,但考虑到未来场景复杂度的增加,数据量增加,以及视觉感知占比增加,车端算力或将翻倍达800TOPS以上。
算力需求与车企高阶智能驾驶渗透率相关,预计到2025年,算力需求将达到14-43 EFLOPS。以吉利为例,从单车算力需求角度进行测算。星睿智算中心算力预计2025年达到1200PFLOPS,可支持350万辆在线车辆并行计算,预测到2025年总算力需求为14 EFLOPS。而小鹏扶摇算力可支撑未来2年每辆车每天10TB数据量的训练算力, 预计2023E/2024E/2025E中国乘用车销量分别为2380/2428/2485万辆,2023E/2024E/2025E中国L2及以上级别智能驾驶渗透率为 50%/70%/80%,到2025年算力需求达到46 EFLOPS。

以Transformer大模型为例,同时对芯片效能有更高要求。主要体现在CNN模型以卷积和矩阵乘等计算密集型算子为主,而Transformer是以访存密集型算子为主的,对带宽和存储有较高要求。Transformer是浮点矢量矩阵乘法累加运算,而目前智能驾驶芯片基本均针对INT8的。智能驾驶芯片厂商正在加强芯片对Transformer的适配,如英伟达在新一代GPU中特别增加了Transformer引擎。












