一、业务背景
前阵子跟业界同行聚会的时候聊到,我们在营销的时候,是分人群投放物料的,但我们物料的排序算法模型却是同一个,这样肯定是有gap的。按人群生命周期管理,例如新手区,我们的目标是成单,而进阶区我们的目标是成大单,排序的产品应该不同。如果按人群训练多个模型,管理起来又非常麻烦。这个问题其实就是千人(千人群)千模的新范式经典问题。目前用meta-learning解决很方便。
我们再来看一个场景:
假设我们是一个电商店铺老板,因为自认为产品性价比好,但没流量不好卖,买了广告流量包成了广告主。一段时间下来,发现广告账户的钱根本花不出去,照样竞争不过那些本来就很好卖的商家。虽然他们产品不好,但还是抢到了流量。
对平台来说,这是一个很有挑战的广告流量分配的问题。一方面,买广告流量的商品一般不是热销商品,他们交互数据少;但平台的排序算法倾向于那些交互数据多的。导致新广告根本没有损耗。这个也可以看做是冷启动问题。其实广泛来说,即使都有交互数,不是冷启动商品,也存在交互不一样的情况。因此也是千人千模问题。一方面,我们需要在顶端流量分发的时候用bandit算法,去给一定流量比例来探索新爆品;但更核心的是,我们需要千AD(广告主)千模,让小广告主排序算法跟大广告主的不一样,达到公平竞争。
这些问题本文提出的方法都能给你解决。
还有一类问题是百度最近发表的。他们2014年就开始做了。现在线上还跑着meta-learning的model。他们用meta learning解决了一个与上面两个场景解耦的问题。因此可以把他们结合起来使用效果更好。百度最近在CIKM2021发表的文章中解决的问题是广告在线学习问题。1)高阶信息的特征交叉可能产生数万亿个特征,这对于在线学习示例来说是稀疏的;2)数据分布的快速变化给准确学习带来了挑战,因为模型必须对新数据进行快速适应。他们用meta-learning的方法来解决老数据、新数据之间有gap的问题。
感兴趣可以看参考文献的第四篇。
二、meta-learning深入浅出
从finetune到元学习
这两个概念是容易混淆的。我这里把他们两个放在一起好好比较一下。
如果是搞CV出身的,我们对finetune的感受是很深的。因为一个高维CNN网络,在
小样本数据集上很难收敛。这个时候需要拿一个在大数据集上训练好的model参数,这些参数可以提取到图片各样式的丰富特征,然后针对目前的小样本,微调一下参数即可。微调的方式可以固定第0层-n-1层layer参数,只微调最后一层都可以。
但这个方法有一个问题,我们训练的时候是在小样本上微调的,我们线上跑的时候呢,是另一个小样本。既然都是小样本,他们的分布是不稳定的,因为不是完全数据集嘛。没有丰富的样本。那么这样微调的网络,在新的小样本数据集上就不一定有效了。
解决这个问题就需要元学习了。这样入手元学习的方式应该比较丝滑吧。
我们在以上面的流程为例,假设原始model的参数是A,我们copy一份为B,把他拿过来在小样本数据集1上finetune,得到参数B1,然后,用这个B1的参数在小样本数据集2上求loss和梯度w,用这个w来更新原始model参数A为A1,这样,新学的A1,相当于是B1在新样本上的信号。这样就是活学活用了。比finetune又更多了一步。
严格的算法说明见下:

算法的解说如下:
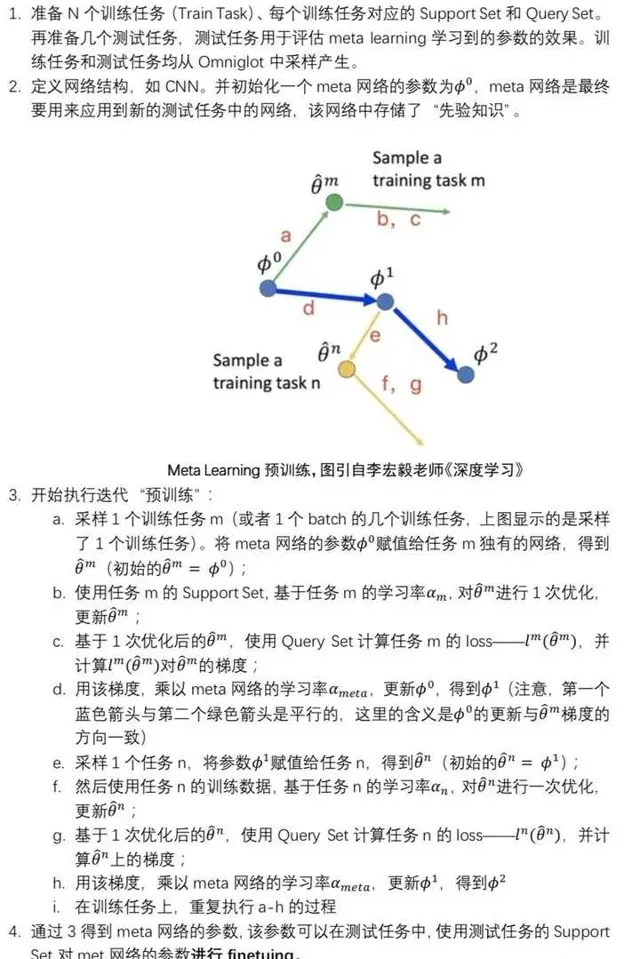
他们两个的区别见下:
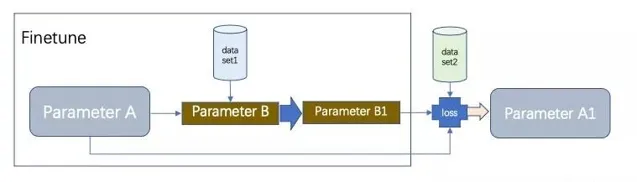
整体是一个meta-learning的过程,前半段是finetune的过程。 参数A和参数B都是共用一个Model,模型的所有的Layers结构都是一样的。参数B一开始是复制的参数A,然后在dataset1上finetune 得到参数B1。根据学到的这个model参数B1,在新数据集2上,会计算得到新的loss。然后按照这个loss去更新参数A的值为A1。这就是整个元学习的过程。
三、千人千模广告算法新范式
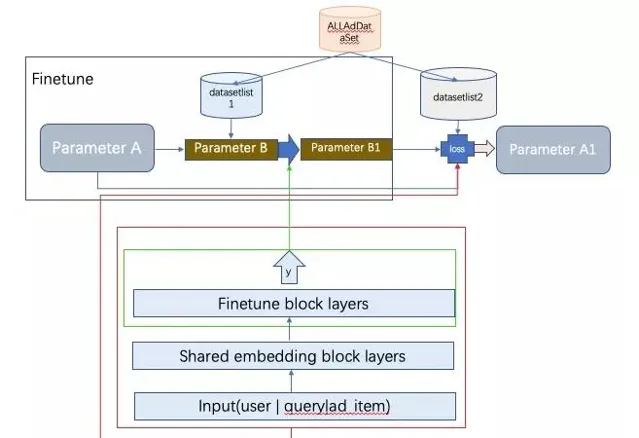
千人千模的整个pipeline架构图如上。广告主会在不同的Adgroup上根据营销目的圈定不同的物料。我们按Adgroup建立数据集。整个数据集由每个Adgroup的单独数据集组合一起而成AllAdDataset。然后,将每个Adgroup的数据集拆分成support set 和query set。所有support set组成datasetlist1,所有query set 组成 datasetlist2。每个Adgroup的数据可以看做是一个任务。接下来仔细讲千人千模的训练过程。 训练:

训练的时候,随机抽多个任务,在每个任务上finetune训练,对应下图中的local update。然后训练好的参数在queryset上计算loss,将计算出来的loss求和更新全局model参数。 更新完后,又重新复制参数A的值到参数B,开始新一轮迭代。 这样的方式保证了finetune的时候单个任务对总模型底盘不动,因而收敛具有稳定性,同时多个任务自由个性化发挥自己的finetune blocklayers的参数。达到千人千模的效果。 部署: 训练好的底盘共享block层部署一份即可,个性化的finetue block layers需要个性化部署。然后实时排序的时候拼接模型打分。初创型公司工程能力弱,可能需要部署千个model了。这个也是一个落地的难点。 今天的分享就到这里。如果你觉得有意思,请点赞、在看、分享到朋友圈。不过分吧?
有触感的解说元宇宙狙击GNN打败deepmind的Graphormer内核情景分析
Transformers4Rec 总结
参考文献
[1] Personalized Adaptive Meta Learning for Cold-start User Preference Prediction AAAI2021
[2] Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings sigir 19
[3] Preference-Adaptive Meta-Learning for Cold-Start Recommendation IJCAI2021
[4] Efficient Learning to Learn a Robust CTR Model for Web-scale Online Sponsored Search Advertising 百度CIKM2021










