元学习 (Meta Learning)或者叫做 「学会学习」 (Learning to learn),它是要「学会如何学习」,即利用以往的知识经验来指导新任务的学习,具有学会学习的能力。
元学习的概念、主要方法以及模型等内容,在 【百面深度学习】 这本书的第7章给了我们较为详细的讲解,有兴趣的同学可进行阅读。
下面人邮君和大家一起来了解一下。
由于元学习可帮助模型在少量样本下快速学习,从元学习的使用角度看,人们也称之为 少次学习 (Few-Shot Learning)。
更具体地,如果训练样本数为 1,则称为一次学习(One-Shot Learning);训练样本数为 K,称为 K 次学习;更极端地,训练样本数为 0,称为零次学习(Zero-Shot Learning)。另外,多任务学习(Multitask Learning)和迁移学习(Transfer Learning)在理论层面上都能归结到元学习的大家庭中。
当前的深度学习大部分情况下只能从头开始训练。使用Finetune来学习新任务,效果往往不好,而Meta Learning 就是研究如何让神经元两个很好的利用以往的知识,使得能根据新任务的调整自己。

瑞士Dalle Molle人工智能研究所的联合主任Jürgen Schmidhuber在1987年毕业论文【Evolutionary principles in selfreferential learning. (On learning how to learn: The meta-meta-... hook.)】中最早提出了元学习的概念。在 1992 和 1993 两年里又借助循环神经网络进一步发展元学习方法。
元学习适合哪些学习场景?
在人工智能系统的背景下,元学习可以简单地定义为 获取知识多样性 (knowledge versatility) 的能力 。作为人类,我们能够以最少的信息同时快速完成多个任务;例如人类在有了世界的概念之后,看一张图片就能学会识别一种物体,而不需要向神经网络一样一切都得从头训练;又例如在学会了骑自行车之后,可以基本在很短时间里无障碍地学会骑电动车。
目前的 AI 系统擅长掌握单一技能,例如 Go , Jeopardy 甚至直升机特技飞行。但是,当你要求 AI 系统做各种简单但又略有不同的问题时,它会很困难。相比之下,人类可以智能地行动和适应各种新的情况。
元学习要解决的就是这样的问题 : 设计出拥有获取知识多样性能力的机器学习模型,它可以在基于过去的经验与知识下,通过少量的训练样本快速学会新概念和技能。
例如完成在非猫图像上训练的分类器可以在看到一些猫图片之后判断给定图像是否包含猫帮游戏机器人能够快速掌握新游戏
使迷你机器人在测试期间在上坡路面上完成所需的任务,即使它仅在平坦的表面环境中训练
与多任务学习以及迁移学习看似相同其实不尽相同的元学习?
元学习虽然从适应新任务的角度看,像是多任务学习;从利用过去信息的角度看,又像迁移学习。不过相对比二者还是有自己的特殊性。
相较于迁移学习元学习模型的泛化不依赖于数据量。而迁移学习微调阶段还是需要大量的数据去喂模型的,不然会很影响最终效果。而元学习的逻辑是在新的任务上只用很少量的样本就可以完成学习,看一眼就可以学会。从这个角度看,迁移学习可以理解为元学习的一种效率较低的实现方式。
对比多任务学习元学习实现了无限制任务级别的泛化。因为元学习基于大量的同类任务 ( 如图像分类任务 ) 去学习到一个模型,这个模型可以有效泛化到所有图像分类任务上。
而多任务学习是基于多个不同的任务同时进行损失函数优化,它的学习范围只限定在这几个不同的任务里,并不具学习的特性。
meta-learning与有监督学习强化学习具体有哪些差别?
我们把 有监督学习 和 强化学习 称为 从经验中学习 (Learning from Experiences) , 下面简称 LFE ; 而把元学习称为 学会学习 (Learning to Learn) , 下面简称 LTL 。两者的区别如下。
LFE的训练集面向一个任务,由大量的训练经验构成,每条训练经验即为有监督学习的(样本,标签)对,或者强化学习的回合(episode) 而LTL的训练集是一个任务集合,其中的每个任务都各自带有自己的训练经验。
LFE的预测函数可写成
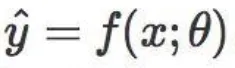
其中 \theta 是给定任务的模型参数;而LTL的预测函数可写成
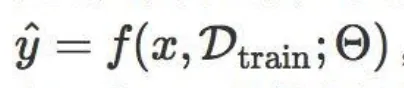
其中 \Theta 代表元参数,它不依赖于某个任务, D_{train} 是单个任务的全部训练数据,它与一个测试样本 x 共同作为 f 的输入。
LFE的目标函数是给定某个任务下最小化训练集 D_{train} 上的损失函数,即

而LTL的目标函数考虑所有训练任务 t\in\ T_{train} ,最小化它们在各自测试集 D_{test}^{t} 上的损失函数之和,即
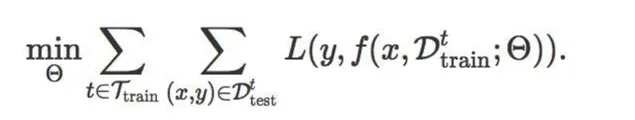
LFE的评价指标是在给定任务的测试集 D_{test} 上的预测准确率,即

而LTL的评价指标是在测试任务集 T_{test} 的每个任务 t 上,利用它的小样本训练集 D_{train}^{t} , 在测试集 D_{test} 上做预测,然后计算所有任务的预测准确率之和,即
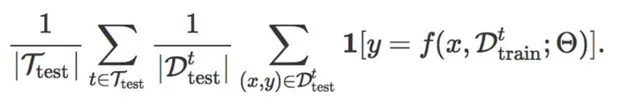
LFE是基层面的学习,学习的是样本特征(或数据点)与标签之间呈现的相关关系,最终转化为学习一个带参函数的形式;而LTL是在基层面之上,元层面的学习,学习的是多个相似任务之间存在的共性。不同任务都有一个与自己适配的最优函数,因此LTL是在整个函数空间上做学习,要学习出这些最优函数遵循的共同属性。
LFE的泛化目标是从训练样本或已知样本出发,推广到测试样本或新样本;而LTL的泛化目标是从多个不同但相关的任务入手,推广到一个个新任务。LTL的泛化可以指导LFE的泛化,提升LFE在面对小样本任务时的泛化效率。
LFE只关注当前给定的任务,与其他任务没关系;而LTL的表现不仅与当前任务的训练样本相关,还同时受到其他相关任务数据的影响,原则上提升其他任务的相关性与数据量可以提升模型在当前任务上的表现。
————
更多关于元学习的内容,例如元学习的 主要方法、数据准备、模型 等,请见 【百面深度学习】 。
【百面深度学习】 由Hulu的近30位算法研究员和算法工程师共同编写完成,专门针对 深度学习领域 ,全面收录 135道真实算法面试题 ,直击面试要点,是【百面机器学习:算法工程师带你去面试】的延伸。

【百面深度学习】仍然采用 知识点问答 的形式来组织内容,每个问题都给出了 难度级 和 相关知识点 ,以督促读者进行自我检查和主动思考。书中每个章节精心筛选了对应领域的不同方面、不同层次上的问题,相互搭配,展示深度学习的「百面」精彩,让不同读者都能找到合适的内容。
元学习已经被大家研究了几十年,可我们对他的探索依旧方兴未已,各种神奇的想法层出不穷,但是真正的杀手级算法还未出现,未来元学习也将有更多的可能。










