朱华荣朱总这两条建议我并不能苟同,甚至从中看到了双方「屁股」坐的到底有多不同。
朱总一共提到了两条,咱们分别来拆解一下。
一、明确个人信息的界限
朱华荣提出以下改善建议:一是明确汽车数据中个人信息的界限。车辆自身及零部件工况类数据,道路、天气等与外部环境有关的数据,无法识别到具体个人,应不属于个人信息的范畴;车控类数据及应用服务类数据中的不同数据与个人的关联性存在很大差异,需要从立法层面进一步予以明确。
乍一看,挺好的。然后越琢磨越不对。
这里能看到,「车辆自身及零部件工况类数据,道路、天气等与外部环境有关的数据,无法识别到具体个人,应不属于个人信息的范畴」
这些真的无法识别到个人吗?往日常了说,你的日常通勤路线、驾驶习惯这些东西没有「个体特异性」吗?显然是有的。
而且按照这个划分法,是不是只有拍到我人脸了才算个人信息啊。

那么为什么要对这些内容做出区隔限定呢?
这里腹黑一下,大家能发现,工况、道路、天气等因素,其实这不就是事故定责时的核心数据嘛。还记得某想那位撞到树上把A柱撞没的事故嘛?理想直接就能自行调取第三方数据来进行自我辩护,而且是直接公开给所有人。这背后有没有筛选有利部分、有没有通过公开内容引导舆论,这些都不可知。
而且数据所有权在手,车企能做的远不止这些。这种划分显然就是做铺垫,后续自然要基于这种划分标准落实所有权,这不第二条建议马上跟上了。
二、落实车企对汽车数据的资源持有权、数据加工使用权、数据产品经营权
二是细化汽车数据产权规定,落实车企对汽车数据的资源持有权、数据加工使用权、数据产品经营权。建议进一步在汽车行业落实【数据二十条】规定的数据资源持有权、数据加工使用权、数据产品经营权三权分立的数据产权规则,促进数据资源化、资产化、资本化。怎么样?先把大部分数据权限拿在手里,车企很多调用数据的行为就一下子变得完全合法。而且你车主甚至都无权调取这部分数据了,真出事,自证的机会都没有,你只能被动挨打,而且车企还能拿你的数据去变现。

到这里得说,逻辑很通顺。这个逻辑其实大家能看出来了,几乎一边倒的倾向车企。
所以说,屁股问题看得很清楚了。
真正的信息管理或许应该这样
其实如果考虑汽车智能化的升级需求,确实需要大量数据投喂、训练,企业也确实不能接受没有数据。
但与朱总的观点不同,我认为这里要明确的不是简单的所谓个人信息、非个人信息这种非黑即白的分法。
而是需要同时兼顾个人隐私保护和企业数据训练才行。
这里可行的方式其实是数据脱敏+第三方监管介入。
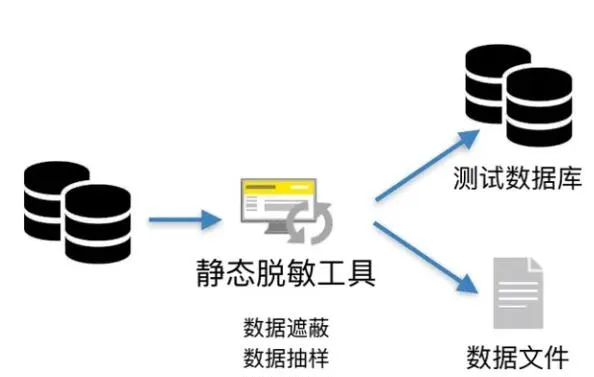
首先就是全面的数据脱敏,把每一组数据与特定的车主脱钩后再投入训练模型。这样车企能够拿到详细的宏观数据,比如一份调研问卷的结果,你能清楚地知道52%的人倾向买自主品牌,但具体是哪写个体属于52%你是拿不到的。
然后数据调用需要有独立的第三方进行监管,比如事故后,车企不能单方面拿数据进行舆论引导。这部分数据需要100%无剪辑的给事故处理方,让公权力机构自行判断。
这样的方式才能同时确保用户数据隐私与企业模型训练需求。
而且这里也希望车企们,多在技术手段上保障各方权利,不要只考虑怎么方便自己。


