23年6月26號,ETH在arxiv掛出了他們最新的論文,視訊暫時還沒有放出來。推測這篇應該是投了science robotics。
我們趁熱打鐵來分析一波這篇論文。
原論文連結:ANYMAL Parkour
前言
ETH連續三年在science robotics 上發表論文,內容從blind locomotion 到perceptive locomotion。終於,在和Nvidia 強強聯手,淘汰Raisim用上isaac gym, 再到發表了幾篇perception和3D重建相關的論文之後,結合perception 的multi skill locomotion + high-level planning 的問題被匯總集合成了一整個成熟的系統。
總結來說這篇文章 約等於 前三篇locomotion skill 加一些agile skill 再加上 感知和規劃部份, 即加入了 [1] [2] 的部份。
個人認為其中最大的貢獻還是在於新加入的 感知和三維重建 部份。但同時文中展示的跳躍,攀爬等動作的確十分驚艷(跳過1.2m的溝,爬上1m高的箱子等)

硬體
配有12個峰值扭矩85Nm的SEA的55kgANYmal-D。其上搭載6個深度相機(前2後2左1右1)+ velodyne Puck LIDAR + NVIDIA Jetson Orin。整個系統依賴於ROS作業系統。
在執行某些極高難度的動作時,關節力矩輸出瞬間直接拉滿,同時關節位置也接近極限位置。可以看出來對硬體穩定性要求極高。
總體框架
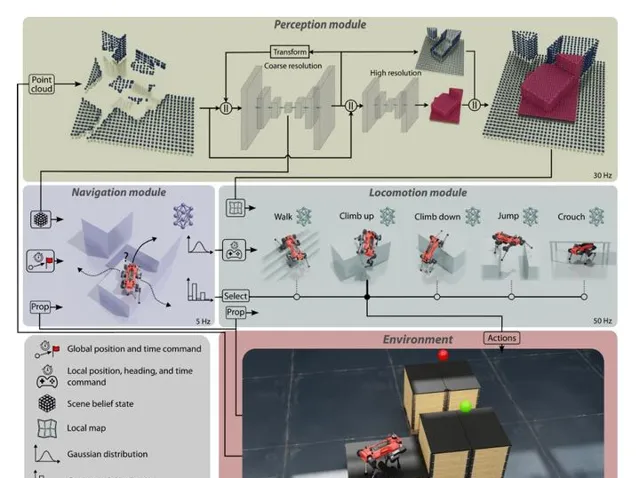
如文中Fig2所示,整個系統分為三個大模組:感知(perception),導航(navigation) 和行走(locomotion)。總共由8個神經網路完成。其中感知2個,導航1個,行走5個(walking, climb up, climb down, jump, crouch)。整個系統能夠讓四足機器人完成自主的Multi-skill 自適應行走和goal-conditioned 導航。
navigation 模組和locomotion 模組使用hierachical(層次連線) 的方式進行,即navigation 模組只負責輸出high-level 指令,並由locomotion 模組接受高層次指令,並輸出關節空間的控制指令。
perception 獲取雷達和深度相機提供的點雲資訊,進行環境重建,在 [2] 的基礎上提出了 「多分辨率」重建 ,以降低大地圖對硬體資源的消耗。具體來講,機器人周圍的地圖分辨率高,較遠的地圖分辨率低,高分辨率地圖方便locomotion做精確的足端規劃,低分辨率地圖提供「遠景」,方便navigation 進行規劃,同時降低儲存負擔。
Locomotion
locomotion 基本沿用之前 [2] 的perceptive locomotion 框架,但加入了position input,做一個position-based goal tracking.
總體上講與 [4] 區別不大,但已經屬於比較hard 的動作,調reward和解決sim2real 問題應該很費時間。
與常見的速度跟蹤policy 不同,這裏直接以位置作為輸入,policy去跟蹤一個全域位置 [1]
Navigation
該模組接收來自感知的結構化數據,並完成選擇動作型別,和確定waypoint position的工作。
本質上是一個local planner。
navigation 直接透過reward訊號來鑒別在各個場景下最適合的locomotion skill, 如下圖,不同高度平台,navigation framework會給出不一樣的規劃路線。

Perception
上述兩個模組都需要perception 提供的資訊。

主要成果
從論文內容上看,整個ANYmal四足系統現在已經趨於完善,系統性很強,工作量巨大,是在大量子工作積累的基礎上匯總,改進形成的完整框架。就好比之前已經蓋了100層的樓上再封個頂。期待視訊最近能放出來。
個人認為這種工作復現難度極大,要想調到每一個模組都像文中這樣穩定和魯棒十分困難。同時也對硬體平台的穩定性要求很高,需要解決的工程問題相當多。
參考
- ^ a b N. Rudin, D. Hoeller, M. Bjelonic, and M. Hutter, 「Advanced skills by learning locomotion and local navigation end-to-end,」 in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 2497–2503.
- ^ a b c d D. Hoeller, N. Rudin, C. Choy, A. Anandkumar, and M. Hutter, 「Neural scene representation for locomotion on structured terrain,」 IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 8667–8674, 2022.
- ^ F. Abdolhosseini, H. Y. Ling, Z. Xie, X. B. Peng, and M. Van de Panne, 「On learning symmetric locomotion,」 in Proceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games, 2019, pp. 1–10.
- ^ N. Rudin, D. Hoeller, P. Reist, and M. Hutter, 「Learning to walk in minutes using massively parallel deep reinforcement learning,」 in Proceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 91–100. [Online]. Available: https://proceedings.mlr.press/v164/rudin22a.htm











