隨著人工智慧技術的發展,愛奇藝內部越來越多的服務使用深度學習模型和技術來驅動,為我們的使用者提供更加智慧和便捷的線上視訊觀看體驗。其中線上類的服務,通常單個容器例項需要獨占一個 GPU,以實作在毫秒/秒級延時內完成例如視訊、圖片、語音、文本的深度學習模型推理請求;為了保證響應延時,請求通常單獨進行,無法對請求做batch以提升計算效率,且不同請求間隔隨機,會導致這些服務的 GPU 計算資源的利用率通常較低(如圖1所示)。且線上類服務請求量在一天或者一定時間周期記憶體在波峰波谷的現象,進一步降低了 GPU 的利用率。鑒於GPU本身高昂的價格,較低的 GPU 利用率浪費了大量計算資源,增加了 AI 服務的成本。

在此背景下,最直接的解決方案是將多個服務部署在同一張 GPU 卡上,在保證服務品質的前提下透過 GPU 共享來提升 GPU 的利用率。目前輝達官方的 GPU 共享技術主要有兩種方案:
(1) vGPU ;(2) MPS 。
接下來我們將簡單對比下兩種方案。
Nvidia vGPU方案
Nvidia的vGPU方案采用虛擬化的技術,基於 SR-IOV 進行 GPU 裝置虛擬化管理,在驅動層提供了時間分片執行的邏輯,並做了一定的視訊記憶體隔離,這樣在對顯卡進行初始化設定的時候就可以根據需求將顯卡進行劃分。其中時間分片排程的邏輯可以是按例項均分,或者是自訂比例,顯卡的視訊記憶體需要按照預設的比例進行劃分。Nvdia的vGPU方案在實施中有下面 兩點限制 :
(1)vGPU劃分完成之後,如果要改變這種預定義的劃分,需要重新開機顯卡才能生效,無法做到不重新開機更改配置。
(2)其方案基於虛機,需要先對 GPU 物理機進行虛擬化之後,再在虛擬機器內部署容器,無法直接基於物理機進行容器化的排程,另外 vGPU 方案需要收取 license 費用,增加了使用成本。
Nvidia MPS方案
Nvidia的MPS方案是一種算力分割的軟體虛擬化方案。該方案和vGPU方案相比,配置很靈活,並且和docker適配良好。MPS 基於C/S架構,配置成MPS模式的GPU上執行的所有行程,會動態的將其啟動的內核發送給MPS server,MPS Server借助CUDA stream,實作多個內核同時啟動執行。除此之外,MPS 還可配置各個行程對 GPU 的使用占比。
該方案的一個 問題在於 ,各個服務行程依賴 MPS,一旦 MPS 行程出現問題,所有在該GPU上的行程直接受影響,需要使用 Nvidia-smi 重設GPU 的方式才能恢復。
01愛奇藝的vGPU方案
調研以上方案後,為了更好地適用於愛奇藝內部 AI 容器化套用場景,我們重新開發了容器場景下的 GPU 虛擬共享方案,基於CUDA API 截獲方式實作視訊記憶體及算力隔離和分配,並基於開源計畫aliyun-gpushare scheduler[1]實作 K8S 上對虛擬 GPU 的排程和分配,實作了多套用容器部署在一張 GPU 卡的目標。
我們方案的 主要特點 是 配置靈活 ,和K8S能夠有機的進行結合,按需實分時配使用者所需要的vGPU例項,同時盡可能的讓物理GPU例項能夠充分的被共享,實作資源的最大化利用。
在完成方案的設計之後,我們對整體進行了效果的評估,測試這種隔離和共享對套用效能的影響。即對於單一行程來說,需要保證:首先它不會使用超過其被分配的算力大小,其次隔離本身不應該對於 GPU 算力有過多損耗,第三是多個行程同時共享的時候,與其單獨執行時相比,不應有太大的效能偏差,即共享可以有效避免行程之間的幹擾。
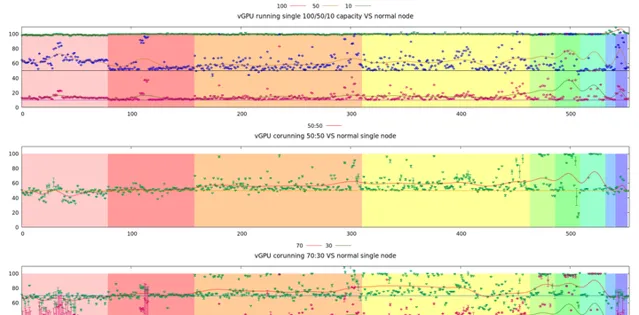
針對以上標準,我們對 GPU 虛擬共享方案進行了效能測試,結果如圖2所示。
第一個測試是單行程算力隔離後效能的評估 。物理 GPU上只執行單一行程,但配置了三次,分別為100%,50%和10% 算力時,其效能和該程式獨立執行時的比例關系。縱軸為達到無虛擬化執行時效能的百分比,橫軸為進行的單元測試用例,區域相同的顏色表示該組測試用例為同一CUDA kernel,但是不同的執行參數。其中圖內的綠點,藍點,和紅點分配是500多個測試用例在各自算力分配的情況下得到的效能,和完全沒有算力分割且獨占GPU時執行的效能的相對比值。另外曲線是這些獨立點的數值在全體維度上做了一個平滑,以更好的進行視覺化的對比。
第二個和第三個測試分別用不同算力配比對兩個GPU行程進行相互幹擾實驗 。如第二個兩個行程分別配置為50% 算力,綠點為兩個GPU行程效能平均值,而紅色曲線為這些綠點的平滑曲線。該曲線和第一個測試中50%算力的曲線對比相差無幾,這就說明了我們方案中配置50%算力時同時執行相互幹擾是幾乎可以忽略的。第三個為一個配置為70%,另外一個配置為30%算力,同樣可以和第一個測試中的獨立分配70%/30%時各自的曲線進行對比。
測試結果表明了方案可以將GPU相互幹擾控制在合理的範圍之內。服務上線後內部統計顯示,平均 100+ 深度學習容器服務可以共享的部署在 35 張物理 GPU 之上,並且做到套用相互之間無影響;對於單張GPU物理卡,平均承載的服務數量從 1 變為了3;同時GPU的平均利用率也提升了2 倍以上。
02愛奇藝GPU虛擬共享的底層原理
首先我們來看看 GPU 虛擬共享的底層原理。GPU作為一個強大的計算外設,提供的兩個主要資源是視訊記憶體和算力。要實作單個 GPU 的共享,我們要實作對視訊記憶體和算力資源的隔離,並驗證隔離方案的效率及效能。
2.1視訊記憶體隔離
對於深度學習套用來說, 對於視訊記憶體的需求 來自於三個方面。
1)第一是模型的CUDA kernel context,可類比於CPU程式中的text段,提供給CUDA kernel執行的環境,這是一項剛需,沒有充足的視訊記憶體,kernel將無法啟動,且context的大小隨著kernel的復雜程度有增長,但在整體模型視訊記憶體需求中是最小的一部份。
2)第二部份來自於模型訓練得出的一些參數,如摺積中的weight和bias。
3)第三部份來自於模型在推理過程中的臨時儲存,用於儲存中間的計算結果。
對於一般的模型來說,基本都不需要占用整個GPU的視訊記憶體。但是這裏有 一個例外 ,Tensorflow框架預設分配所有GPU的視訊記憶體來進行自己的視訊記憶體管理。當然Tensorflow框架有相應的選項可以遮蔽該行為,但是對於平台來說,要讓每個使用者修改 TF 的配置為遮蔽該行為,就不太可行。
為
應對這一問題
,一個巧妙的方法可以在不需要套用開發者參與的情況下,讓Tensorflow的部署套用只分配它所需的視訊記憶體大小而不出現問題。該方法即API動態攔截。Tensorflow之所以可以知道當前GPU的剩余視訊記憶體,是透過
cuDeviceTotalMem/cuMemGetInfo這兩個CUDA library API。透過LD_PRELOAD的方式,在的勾點so中實作這兩個API,那麽Tensorflow執行的時候,link首先會呼叫的是的API實作,而不是CUDA的,這樣就可以動態的修改這兩個API的返回結果,如這裏想做的,將特定Tensorflow套用的視訊記憶體配額限制在其申請數值。
在系統實作的過程中,還對cuMemAlloc/cuMemFree做了同樣的攔截,目的是為了能夠對同容器中的多個GPU行程行程統一管理。當多個GPU行程分配視訊記憶體之和超過其配額時,可以透過cuMalloc來返回視訊記憶體不足的錯誤。容器內視訊記憶體配額管理是透過share mem來做的。圖3展示了視訊記憶體隔離和分配的整個流程。

2.2算力隔離
除了視訊記憶體, 另外一個重要的GPU資源是算力 。對於Nvidia volta顯卡架構來說,它的算力來源於三個方面,浮點計算單元、整形計算單元、tensor core加速計算單元。其中浮點計算單元和整形計算單元是流處理器SP的內部結構,而SM中包含著多個流處理器SP。對於V100來說,它有80個SM,每個SM中有64個SP,合5120個流處理器,其中tensor core是位於SM的內部,與SP共享寄存器/share mem/L1 cache。圖4給出了Nvidia GPU的硬體架構組織關系框圖。
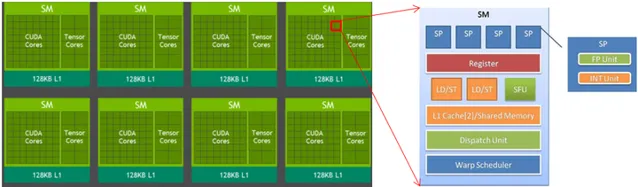
對於Nvidia的GPU的程式語言CUDA來說,它的語言設計邏輯上和上圖的硬體層次是對應的。CUDA有 三層邏輯層次 ,分別為 grid , block ,和 thread 。Grid可以認為是對整個顯卡的邏輯抽象,block可以認為是對SM單元的邏輯抽象,而thread是SP的邏輯抽象。為了達到最高的並行程度,SM之間可以認為是沒有互動的,當然這也不是絕對的,有一些程式為了自己的特殊邏輯,也可以設計出SM之間依賴的程式,但這個代價是極大的效能浪費。
在知道了GPU的底層結構,以及CUDA的設計原理之後,可以就如何算力虛擬化來做一下初步設想。既然一些模型無法完全利用GPU的全部算力,那麽何不削減其占用的SM個數,使得空閑下來的SM可以為其他GPU程式所用?
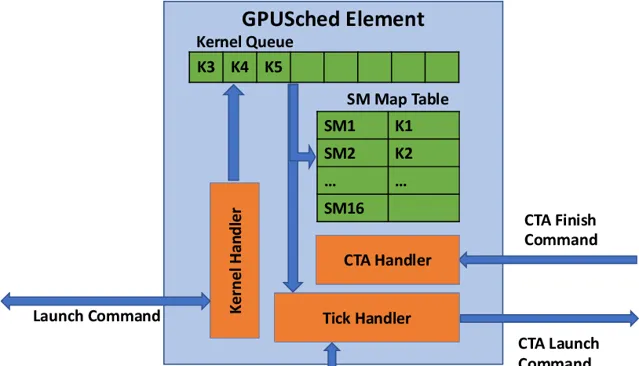
這樣的想法是好的,但是一些限制阻止了這種最佳化的實作。GPU程式的執行,是透過kernel的片段來具體實施,在CPU側launch了 kernel之後,具體的kernel及其呼叫參數隨即交由GPU的硬體排程器來在某個未來的時間點真正執行起來。在預設的情況下,kernel是被派發給GPU上所有的SM,且執行過程中不能被中斷。如圖5所示,軟體系統在發送完畢啟動命令之後,隨即命令及參數由PCIe轉交給GPU硬體,並插入其佇列中,由GPU硬體中固化的邏輯去具體處理在何時真正啟動。
但世事無絕對,預設情況下不行,不代表沒有別的辦法。讓我們再來回顧一下CUDA的設計。CUDA作為一個用於操控GPU來完成高效平行計算的語言,它的程式碼編寫邏輯是以thread為基本單元的。SM上所有SP都執行著一份kernel的程式碼,且在一定程度上來說連執行節奏都完全一致。CUDA中用來區分thread,來判斷程式碼應該處理數據的偏移量的方法,是透過CUDA中的blockIdx/threadIdx這兩個內嵌變量。這兩個變量在機器碼上是唯讀的,在thread由硬體排程器派發的時候所指定。透過硬體排程器,就完成了抽象的blockIdx/threadIdx和具體的SM/SP的繫結。圖6大概的描述了這一對映關系。
為了能夠精確的控制算力,我們就不能再依賴硬體排程器來控制內核啟動。在這裏用了一個取巧的方法,就是讓內核啟動之後被「困」在固定數目的SM上面,這個數目的值和GPU整體SM個數的比例就是給這個內核算力配比。
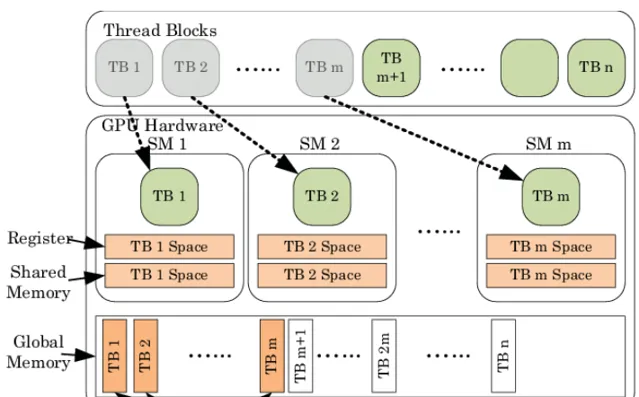
為了形象化來闡述思路,這裏我們對GPU做了一個抽象化的改動,SM的個數被定義為10個。然後有一個啟動參數為<<<15,1>>>的內核,即CUDA block size為15,thread size為1。它正常啟動的時候,硬體排程器會給每一個SM上分配一個內核的副本。這樣在第一時間就消耗了10個block的副本,隨後每個SM上內核執行完畢之後會結束,硬體排程器會進一步分配剩下的5個block副本,在這個也執行完畢之後就完成了整個內核的執行。
算力切分之後,我們會在內核啟動時,動態的修改其啟動參數,將其CUDA block size從15變為5。這樣硬體排程器就會將內核副本分配到GPU上一半數目的SM上,空閑的一半可以為其他內核所使用,如圖7所示。
我們雖然透過動態修改啟動參數的方法,避免了內核占滿全部SM資源,但此時還沒完成「困」這一動作。所以此時的內核行為是其完成預定邏輯之後,會結束,導致此時內核不能覆蓋block size為15時的數據空間。為了將其「困「住,我們在內核的組譯EXIT處,替換成了BRANCH操作。這樣內核完成本身的邏輯之後,會跳轉到我們預設的一段邏輯中。這個邏輯完成虛擬blockIdx/threadIdx的自增操作,隨後再跳轉到內核開始位置,來基於更新的blockIdx/threadIdx來進行新一輪計算。
這次需要指出的是blockIdx/threadIdx為唯讀寄存器,所以沒辦法直接更改它的值。作為一個替代的解決方案時,將內核中的blockIdx/threadIdx進行整體替換為可寫的寄存器,這樣我們就可以在預設的跳轉邏輯中做更改操作,如圖8所示。
03愛奇藝GPU虛擬共享的排程設計
完成了 GPU 底層的資源隔離之後,我們還需要基於 K8S 平台實作對隔離的 GPU 資源的分配和排程管理 ,以方便業務的深度學習服務能夠 快速部署 到共享的 GPU。
K8S 容器中使用 GPU 的方案一般采用 Nvidia device plugin(輝達官方外掛程式),它可以為 Pod 分配一卡或多卡,分配的最小單元是1張卡,無法支持底層隔離的 GPU 資源排程。調研之後,我們選擇阿裏雲容器服務開源的aliyun-gpushare作為排程方案,實作對 GPU 隔離資源的排程。
以視訊記憶體為例,使用aliyun-gpushare,為 Pod 分配的是一張卡中的部份視訊記憶體,這樣從邏輯上說,單卡的資源就可以再進一步被切分。假設有一張 V100 32GB 卡,可以給 Pod1 分配 4GB 視訊記憶體,也可以同時給 Pod2 分配 8GB 卡,直到 32GB 視訊記憶體分配完畢。整個排程過程如圖9所示
其中,Share GPU Device Plugin 和 Share GPU Schd Extender 是主要的新增元件,下文簡寫為 SGDP和SGSE。其余的元件均為 k8s 官方元件。
圖中的 主要流程 如下:
- 使用者建立一個 Share GPU Pod 時,必須帶 http:// aliyun.com/gpu-mem 這種 K8S 自訂資源,表明其需要多少視訊記憶體。
- SGSE 根據使用者的 Share GPU 視訊記憶體請求和集群整體資源情況,給該 Pod 分配一個 Node,並透過 patch Pod annotation 來指定使用某張卡。
- Kubelet 呼叫 SGDP 的 Allocate 方法,將指定的 GPU 卡分配給 Pod 使用,同時設定環境變量 ALIYUN_COM_GPU_MEM_CONTAINER(容器可用視訊記憶體)、LD_PRELOAD(其值為限制視訊記憶體的動態連結庫路徑)。
- Pod 啟動後,因為設定了 LD_PRELOAD,所有 AI 框架的 GPU 視訊記憶體申請都被動態連結庫的勾點劫持,當使用的總資源超過 ALIYUN_COM_GPU_MEM_CONTAINER 的值,則拒絕請求。從而達到限制使用者使用視訊記憶體的效果。
算力資源的排程策略類似以上視訊記憶體排程。
實踐中,對於 1 張物理 GPU 卡,我們進行 1/4 和 1/2 的視訊記憶體和算力的分割,業務可根據實際需要選擇對應的比例,單張 GPU 最多可部署 4 個不同套用,並可實作有效隔離,互不影響。
04結語和展望
透過底層LD_PRELOAD動態劫持的方式,我們實作了容器中輕量級 GPU 視訊記憶體和算力的隔離,從而支持多個容器套用部署在同一個 GPU 上。該方案從一個動態的維度實作單張 GPU資源的劃分,針對線上推理服務場景,很好的提升了GPU硬體的使用效率。
後續工作中,我們還計劃開發和實作跨主機 GPU 遠端呼叫的方案,來解決 GPU 虛擬共享之後,產生的單機多卡機器上 CPU/GPU 比例失衡,導致的部份虛擬 GPU 資源無 CPU可分配的問題。
參考文獻 :
1.aliyun-gpushare: https:// github.com/AliyunContai nerService/GPUshare-scheduler-extender
2.Nvidia vGPU:https:// docs.Nvidia.com/grid/la test/grid-vGPU-user-guide/index.html
3. Nvidia MPS:https:// docs.Nvidia.com/deploy/ mps/index.html










