版權聲明 ©本文先發於知乎專欄:移動端演算法最佳化
本專欄「移動端演算法最佳化」所有文章著作權歸作者所有。
允許個人直接分享本專欄文章到個人微博、朋友圈。但媒體(包括但不限於網站、微信公眾號
、微博行銷號)轉載需事先征得專欄同意。轉載需在正文開頭顯著位置註明出處,給出原始連結,註明「發表於知乎專欄【移動端演算法最佳化】」,並不得進行任何形式的修改演繹。
一、 概述
ARM NEON 可以提升電腦視覺等計算密集型程式的效能,編譯器可以將 C/C++ 程式碼自動轉換為 NEON 指令。但是想要有更好的效能還是需要手工編寫 NEON 程式碼,熟練掌握 NEON 指令是第一步。
本文接下來會詳細的介紹 Armv7 和 Armv8 架構下 NEON 向量寄存器、NEON 組譯指令格式、NEON Intrinsics 指令格式、常用的 Intrinsics 指令以及作用、在 x86 平台偵錯 NEON 程式碼,最後針對幾個常用的 Intrinsics 指令結合例項進行說明。
二、NEON指令格式
2.1 Armv7,Armv8,Armv9的介紹
Armv7-A 和 Armv8-A 的關系如下圖所示:
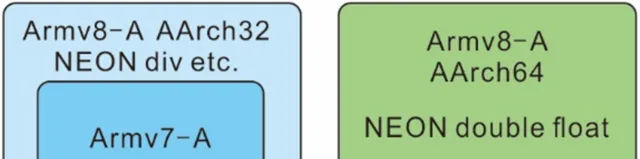
Armv8-A 的執行狀態可以分為 AArch64 和 AArcp2 兩種狀態。
ARMV8 支持浮點型別的除法向量操作,這是ARMV7所沒有的。另外AArch64還支持double型別的操作。
Armv9-A 是 arm 當前最新的指令架構,Armv9-A 除了向前相容 Armv8-A,在效能計算上有了很大的提升,主要表現在安全、AI 以及改進向量擴充套件 (SVE2)和 DSP 能力。
2.2 向量寄存器介紹
向量寄存器 用來存放向量數據, 每個向量元素的型別必須相同 。向量寄存器根據處理元素的大小可以劃分為 2/4/8/16 個通道。

2.2.1 AArch64 向量寄存器
AArch64 有 32 個 128bit 的向量寄存器,這些寄存器又可以劃分為:
每種型別寄存器的對映關系 如下:

2.2.2 AArchp2 / ARMV7向量寄存器
AArcp2/Armv7 有 16 個 128bit 的向量寄存器,這些寄存器又可以劃分為:
每種型別寄存器的對映關系如下:

2.3 組譯指令格式介紹
AArch64 與AArcp2 / Armv7-A 的 NEON 組譯指令除了種類上存在差異,格式上也存在很大差異。
其中指令中有一些通用的書寫格式, 含義如下:
2.3.1 AArch64組譯指令 格式
{<
prefix
>
}
<
op
>
{
<
suffix
>
}
Vd.
<
T
>
,
Vn.
<
T
>
,
Vm.
<
T
>
1)<prefix> 表示字首名字,包括以下幾類:
2)<op>
表示具體的操作,例如
ADD
,
SUB
等等
3)<suffix> 表示字尾名字,包括以下幾類:
4)<T> 表示單個通道的數據型別, 8B/16B/4H/8H/2S/4S/2D ,B 表示 8bit,H 表示 16bit,S 表示 32bit,D 表示 64bit。
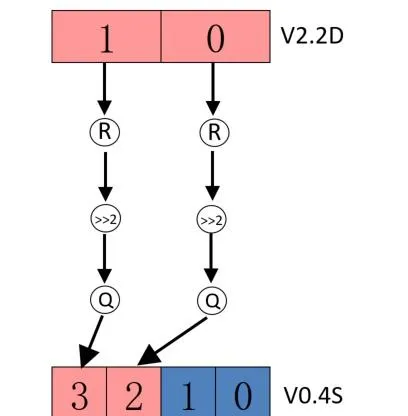
SQRSHRN2
表示對向量進行 Rouding 型別的右移操作,並對結果做飽和計算,最後將結果賦給目的向量的高半部份,並保持低半部份不改變,具體範例如下
// 指令語句作用:
// 將 V2 向量中每個元素按照 Rounding 方式右移動 2 位,然後對結果做飽和操作,
// 並將結果保存到V0上半部份,而且保證V0的下半部份保持不變
// 指令格式說明:
// S -- 表示有符號操作
// Q -- 表示飽和操作
// R -- 表示舍入操作
// SHR -- 表示向右位移
// N2 -- 表示將結果保存到輸出向量的高 64bit
// V2.2D -- 表示輸入向量寄存器,長度為 128bit,一共兩個通道,每個通道 64bit
// V0.4S -- 表示輸出向量寄存器,長度為 128bit,一共四個通道,每個通道 32bit
SQRSHRN2
V0
.4
S
,
V2
.2
D
,
2
// 虛擬碼
如下:
int
shift
=
2
;
int
round_const
=
(
1
<<
(
shift
-
1
));
V0
[
2
]
=
SAT
((
V2
[
0
]
+
round_const
)
>>
shift
)
V0
[
3
]
=
SAT
((
V2
[
1
]
+
round_const
)
>>
shift
)
2.3.2 AArcp2 / Armv7組譯指令格式
V
{
<
mod
>
}
<
op
>
{
<
shape
>
}{
<
cond
>
}{
.
<
dt
>
}
<
dest1
>
{
,
<
dest2
>
}
,
<
src1
>
{
,
<
src2
>
}
1)V AArcp2 / Armv7 的組譯指令以"V"開頭
2)<mod> 該修飾字可以表示為以下型別:
3)<op>
表示具體的操作,例如
ADD
,
SUB
等等
4)<shape> 表示數據長度的變化,L/N/W。
5)<cond> 表示指令執行的條件
6).<dt> 表示數據型別,預設為第二個運算元的數據型別。如果第二個運算元不存在,為第一個運算元型別,仍不存在為結果運算元型別。
7)<dest> 表示輸出運算元
8)<src1> <src2> 表示兩個輸入運算元
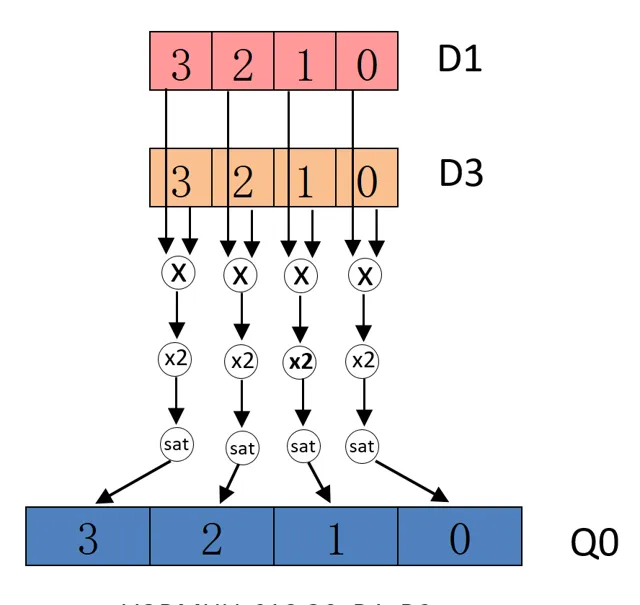
組譯指令例子
VQDMULL
表示兩向量相乘,結果乘以 2
。
// 指令語句作用:
// 64bit 向量 D1 和 D3 中每個元素對應相乘,並將結果乘以 2
// 最後的結果做飽和之後賦值給 128bit 向量 Q0
//
// 指令格式說明:
// Q -- 表示飽和操作
// D -- 表示 doubling 操作,即乘以 2
// MUL -- 表示乘法操作
// L -- 輸出向量是輸入向量長度的 2 倍
// .S16 -- 表示操作元素的數據型別為有符號 16bit
// Q0 -- 表示輸出向量寄存器,長度為 128bit
// D1 -- 表示輸入向量寄存器,長度為 64bit
// D3 -- 表示輸入向量寄存器,長度為 64bit
VQDMULL
.
S16
Q0
,
D1
,
D3
// 虛擬碼
for
(
int
i
=
0
;
i
<
4
;
i
++
)
{
q0
[
i
]
=
SAT
(
d1
[
i
]
*
d3
[
i
]
*
2
)
}
2.4 intrinsics指令格式
相比於組譯指令,NEON Intrinsics 是一種更簡單的編寫 NEON 程式碼的方法,NEON Intrinsics 類似於 C 函式呼叫,在編譯時由編譯器替換為相應的組譯指令,使用時需要包含表頭檔
arm_neon.h
。
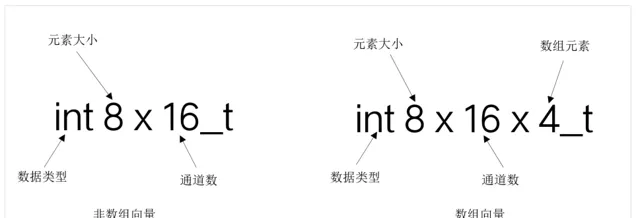
2.4.1 向量型別格式
// 非陣列向量格式
<
type
><
size
>
x
<
number_of_lanes
>
_t
// 陣列向量格式
<
type
><
size
>
x
<
number_of_lanes
>
x
<
length_of_array
>
_t
1)<type>
數據型別,如
int
/
uint
/
float
/
poly
。
2)<size> 元素大小,如8/16/32/64。
3) <number_of_lanes> 通道數。
4) <length_of_array> 陣列中元素個數。
2.4.2 NEON行內函式格式
v
<
mod
><
opname
><
shape
><
flags
>
_
<
type
>
1)<mod>
// a加b的結果做飽和計算
int8x8_t
vqadd_s8
(
int8x8_t
a
,
int8x8_t
b
);
// a減b的結果右移一位
int8x8_t
vhsub_s8
(
int8x8_t
a
,
int8x8_t
b
);
// a乘b的結果擴大一倍, 最後做飽和操作
int32x4_t
vqdmull_s16
(
int16x4_t
a
,
int16x4_t
b
);
// 將a與b的和減半,同時做rounding 操作, 每個通道可以表達為: (ai + bi + 1) >> 1
int8x8_t
vrhadd_s8
(
int8x8_t
a
,
int8x8_t
b
);
// 將a, b向量的相鄰數據進行兩兩和操作
int8x8_t
vpadd_s8
(
int8x8_t
a
,
int8x8_t
b
);
2) <opname>
表示具體操作,比如
add
,
sub
。
3) <shape>
uint16x8_t
vaddl_u8
(
uint8x8_t
a
,
uint8x8_t
b
);
uint32x2_t
vmovn_u64
(
uint64x2_t
a
);
uint16x8_t
vsubw_u8
(
uint16x8_t
a
,
uint8x8_t
b
);
// a 和 b 只有高 64bit 參與運算
int16x8_t
vsubl_high_s8
(
int8x16_t
a
,
int8x16_t
b
);
// 向量 a 中的每個元素右移 n 位
int8x8_t
vshr_n_s8
(
int8x8_t
a
,
const
int
n
);
// 取向量 v 中下標為 lane 的元素與向量 a 做乘法計算
int16x4_t
vmul_lane_s16
(
int16x4_t
a
,
int16x4_t
v
,
const
int
lane
);
4) <flags>
5) <type>
表示單個通道的數據型別,有
u8
、
s8
、
u16
、
s16
、
u32
、
s32
、
f32
、
f64
。

三、intrinsics 指令介紹
3.1 intrinsics指令分類
| 功能類別 | 介紹 |
|---|---|
| Load/Store | 對數據進行向量載入和儲存,既可以對單個數據進行載入和儲存,也可以對向量結構體數據進行載入和儲存 |
| Arithmetic | 對整數和浮點數向量加減 運算 |
| Multiply | 整型或浮點型的向量乘法運算,同時包含了乘法和加法混合運算,以及乘法和減法的運算的混合運算 |
| Shift | 向量位移操作,其中位移數據可以是立即數也可以是向量 |
| Logical and compare | 包含了邏輯運算 (與或非運算等)和比較運算(等於、大於、小於等) |
| Floating-point | 包含了浮點和其他型別數據之間的相互轉化操作 |
| Permutation | 對向量進行重排操作 |
| Misecllaneous | 純量數據 賦值到向量的操作 |
| Data processing | 一般性處理,極值操作、絕對值差、數值取反、平方根倒數等 |
| Type conversion | 數值型別轉換,數據的組合及提取等 |
3.2 NEON intrinsics指令詳述
本節將對每種型別的 NEON intrinsics 指令做出詳細的描述。
3.2.1 Load/Store
// 以解交織方式載入數據到n個向量寄存器, n為1~4
Result_t
vld
[
n
]
<
q
>
_type
(
Scalar_t
*
p_addr
);
// 以解交織方式載入數據到n個向量寄存器的第N通道, n為1~4
Result_t
vld
[
n
]
<
q
>
_lane_type
(
Scalar_t
*
p_addr
,
Vector_t
M
,
int
N
);
// 將n個向量寄存器數據以交織方式儲存到記憶體中, n為1~4
void
vst
[
n
]
<
q
>
_type
(
Scalar_t
*
N
,
Vector_t
M
);
// 將n個寄存器的N通道數據以交織方式儲存到記憶體中, n為1~4
void
vst
[
n
]
<
q
>
_lane_type
(
Scalar_t
*
p_addr
,
Vector_t
M
,
int
N
);
3.2.2 Arithmetic
// 基本的加減操作
Result_t
vadd
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vsub
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
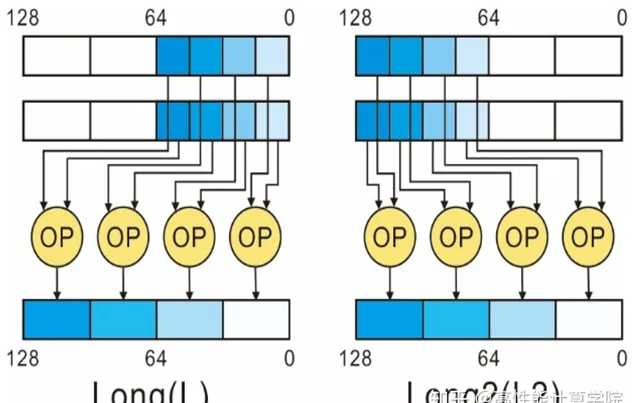
// L(Long)型別的指令加減運算,輸出向量長度是輸入的兩倍。
Result_t
vaddl_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vsubl_type
(
Vector1_t
N
,
Vector2_t
M
);
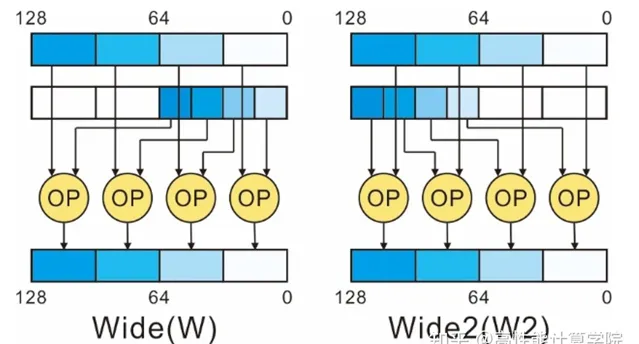
// W(Wide)型別的指令加減運算,第一個輸入向量的長度是第二個輸入向量長度的兩倍。
Result_t
vaddw_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vsubw_type
(
Vector1_t
N
,
Vector2_t
M
);
// H(half)型別的加減運算;將計算結果除以2。
Result_t
vhadd
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vhsub
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// Q(Saturated)飽和型別的加減操作
Result_t
vqadd
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vqsub
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// RH(Rounding Half)型別的加減運算
Result_t
vrhadd
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vrhsub
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
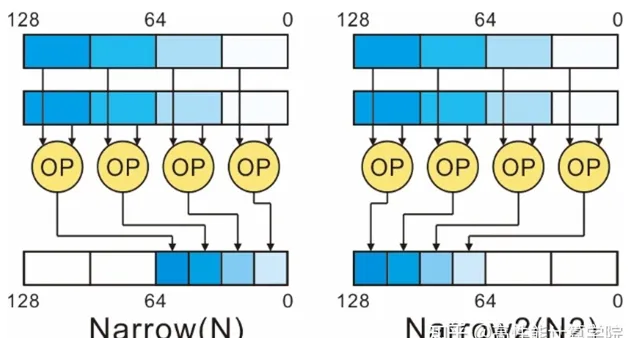
// HN(half Narrow)型別的加減操作
Result_t
vaddhn_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vsubhn_type
(
Vector1_t
N
,
Vector2_t
M
);
// RHN(rounding half Narrow)型別的加減操作
Result_t
vraddhn_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vrsubhn_type
(
Vector1_t
N
,
Vector2_t
M
);
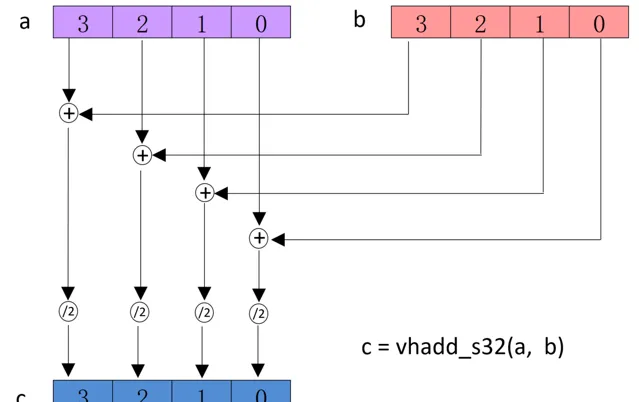
3.2.3 Multiply
// 基本乘法操作
Result_t
vmul
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// l(Long)型別的乘法操作
Result_t
vmull_type
(
Vector1_t
N
,
Vector2_t
M
);
// QDL(Saturated, Double, Long)型別的乘法操作
Result_t
vqdmull_type
(
Vector1_t
N
,
Vector2_t
M
);
// 基本的乘加和乘減操作
Result_t
vmla
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
Result_t
vmls
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
// L(Long)型別的乘加和乘減操作
Result_t
vmlal_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
Result_t
vmlsl_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
// QDL(Saturated, Double, Long)型別的乘加和乘減操作
Result_t
vqdmlal_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
Result_t
vqdmlsl_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
// QDLH(Saturated, Double, Long, Half)型別的乘法操作
Result_t
vqdmulh
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// QRDLH(Saturated, Rounding Double, Long, Half)型別的乘法操作
Result_t
vqrdmulh
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// 基本的乘法操作
Result_t
vmull_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
// 基本的乘加和乘減操作
Result_t
vmla
<
q
>
_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
Result_t
vmls
<
q
>
_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
// L(long) 型別的乘加和乘減操作
Result_t
vmlal_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
Result_t
vmlsl_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
// QDL(Saturated, Double, long) 型別的乘加和乘減操作
Result_t
vqdmlal_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
Result_t
vqdmlsl_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
,
int
n
);
// QDH(Saturated, Double, Half) 型別的操作
Result_t
vqdmulh
<
q
>
_lane_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);

// 基本的向量和純量的乘法
Result_t
vmul
<
q
>
_n_type
(
Vector_t
N
,
Scalar_t
M
);
// L(Long) 型別的向量和純量的乘法
Result_t
vmull_n_type
(
Vector_t
N
,
Scalar_t
M
);
// QDL(Saturated, Double, long) 型別的向量和純量的乘法
Result_t
vqdmull_n_type
(
Vector_t
N
,
Scalar_t
M
);
// QDH(Saturated, Double, Half) 型別的向量和純量的乘法
Result_t
vqdmulh
<
q
>
_n_type
(
Vector_t
N
,
Scalar_t
M
);
// QRDH(Saturated, Double, Half) 型別的向量和純量的乘法
Result_t
vqrdmulh
<
q
>
_n_type
(
Vector_t
N
,
Scalar_t
M
);
// L(Long) 型別的乘加和乘減操作
Result_t
vmlal_n_type
(
Vector1_t
N
,
Vector2_t
M
,
Scalar_t
P
);
Result_t
vmlsl_n_type
(
Vector1_t
N
,
Vector2_t
M
,
Scalar_t
P
);
// QDL(Saturated, Double, long) 型別的乘加和乘減
Result_t
vqdmlal_n_type
(
Vector1_t
N
,
Vector2_t
M
,
Scalar_t
P
);
Result_t
vqdmlsl_n_type
(
Vector1_t
N
,
Vector2_t
M
,
Scalar_t
P
);
3.2.4 Shift
// 基本的立即數左移和右移
Result_t
vshr
<
q
>
_n_type
(
Vector_t
N
,
int
n
);
Result_t
vshl
<
q
>
_n_type
(
Vector_t
N
,
int
n
);
// R(rounding) 型別的右移操作
Result_t
vrshr
<
q
>
_n_type
(
Vector_t
N
,
int
n
);
// QL(Saturated, long) 型別的右移操作
Result_t
vqshl
<
q
>
_n_type
(
Vector_t
N
,
int
n
);
// 右移累加操作
Result_t
vsra
<
q
>
_n_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
// R(rounding) 型別的右移累加操作
Result_t
vrsraq_n_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
// Q(Saturated) 型別的左移操作,而且輸入是有符號,輸出是無符號的
Result_t
vqshluq_n_type
(
Vector_t
N
,
int
n
);
// N(Narrow) 型別的右移操作
Result_t
vshrn_n_type
(
Vector_t
N
,
int
n
);
// QN(Saturated, Narrow) 型別的右移操作, 而且輸入是有符號,輸出是無符號的
Result_t
vqshrun_n_type
(
Vector_t
N
,
int
n
);
// QRN(Saturated, Rounding, Narrow) 型別的右移操作, 而且輸入是有符號,輸出是無符號的
Result_t
vqrshrun_n_type
(
Vector_t
N
,
int
n
);
// QN(Saturated, Narrow) 型別的右移操作
Result_t
vqshrn_n_type
(
Vector_t
N
,
int
n
);
// RN(Rounding, Narrow) 型別的右移操作
Result_t
vrshrn_n_type
(
Vector_t
N
,
int
n
);
// QRN(Rounding, Rounding, Narrow) 型別的右移操作
Result_t
vqrshrn_n_type
(
Vector_t
N
,
int
n
);
// N(Narrow) 型別的左移操作
Result_t
vshll_n_type
(
Vector_t
N
,
int
n
);
// 左移
Result_t
vshlq_type
(
Vector1_t
N
,
Vector2_t
M
);
// Q(Saturated) 型別的左移操作
Result_t
vqshl
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// QR(Saturated, rounding) 型別的左移操作
Result_t
vrshl
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// 將向量 M 中各個通道先右移動 n 位, 然後將移動後元素插入到 N 對應的元素中,
// 並保持 N 中每個元素的高 n 位保持不變
Result_t
vsri
<
q
>
_n_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
// 將向量 M 中各個通道先左移動 n 位, 然後將移動後元素插入到 N 對應的元素中,
// 並保持 N 中第每個元素的低 n 位保持不變
Result_t
vsli
<
q
>
_n_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
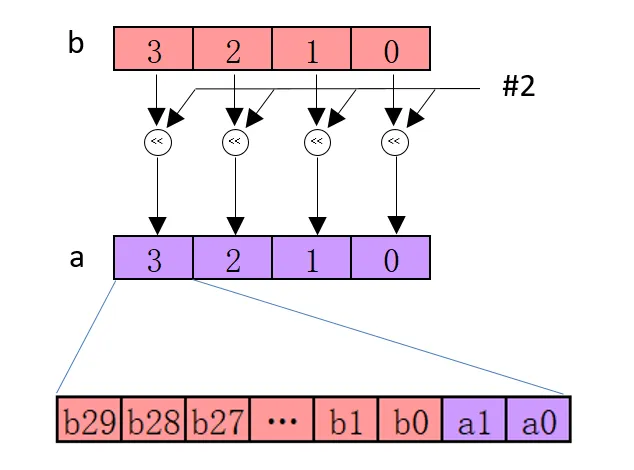
3.2.5 Logical and compare
eq 表示相等, ge 表示大於或等於, gt 表示大於, le 表示小於或等於, lt 表示小於
Result_t
vceq
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcge
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcle
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcgt
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vclt
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcage
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcale
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcagt
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vcalt
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
- 按位與\或\非\異或操作
Result_t
vand
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vorr
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vmvn
<
q
>
_type
(
Vector_t
N
);
Result_t
veor
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
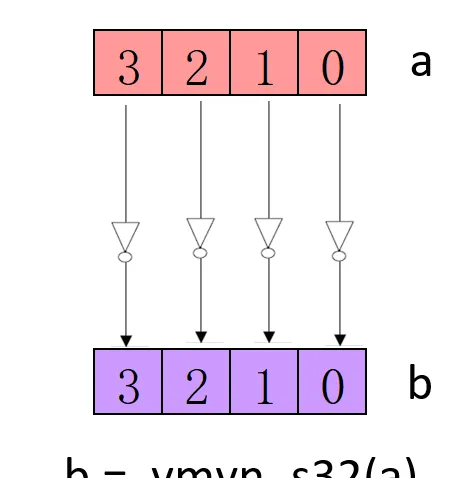
// 按通道做與操作,為 true 時,將輸出向量對應通道設定為全 1,否則設定為全 0
Result_t
vtst
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// M 作為 mask,標識是否對 N 做清零操作。當 M 中某位為 1, 則將 N 中對應位清零
Result_t
vbic
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// P 作為 mask,按位 select。當 P 中某位是 1 時,將選擇 N 中對應位作為輸出,否則選擇 M
Result_t
vbsl
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
3.2.6 Floating-point
// 單精度浮點
轉化為整數型別
Result_t
vcvt
<
q
>
_type_f32
(
Vector_t
N
);
// 整數型別轉化為單精度浮點
Result_t
vcvt
<
q
>
_f32_type
(
Vector_t
N
);
// f16轉化為f32
Result_t
vcvt_f16_f32
(
Vector_t
N
);
// f32轉化為f16
Result_t
vcvt_f32_f16
(
Vector_t
N
);
Result_t
vfma
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
Result_t
vfms
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
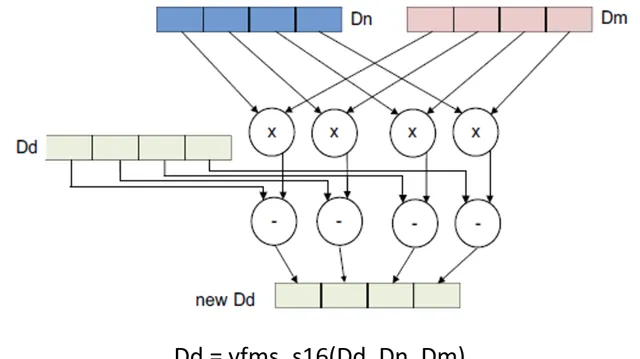
3.2.7 Permutation
Result_t
vext
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
int
n
);
Result_t
vtbl
[
n
]
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vtbx
[
n
]
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
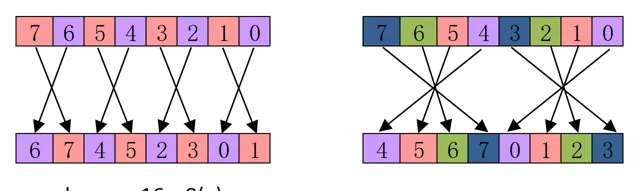
Result_t
vrev64
<
q
>
_type
(
Vector_t
N
);
Result_t
vrev32
<
q
>
_type
(
Vector_t
N
);
Result_t
vrev16
<
q
>
_type
(
Vector_t
N
);
vrev16<q>_type
按照 16bit 為塊,塊內數據按照 8bit 為單位進行翻轉
。
vrev32<q>_type
按照 32bit 為塊,塊內數據按照 8bit,16bit 為單位進行翻轉
。
vrev64<q>_type
按照 64bit 為塊,塊內數據按照8bit, 16bit, 32bit為單位進行翻轉
。
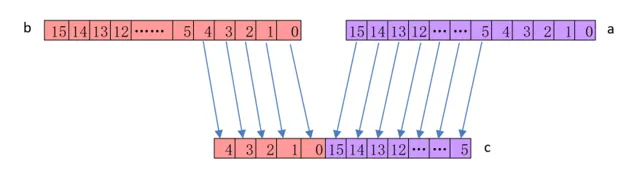
TRN1
,
TRAN2
Result_t
vtrn1
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vtrn2
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);

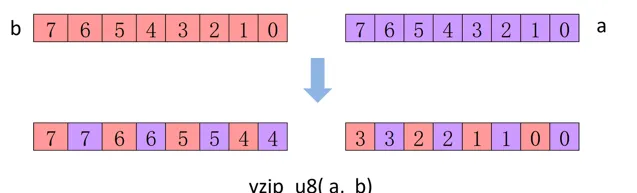
// 交織操作
Result_t
vzip
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// 解交織操作
Result_t
vuzp
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
3.2.8 Miscellaneous
Result_t
vcreate_type
(
Scalar_t
N
);
Resutl_t
vdup_type
(
Scalar_t
N
);
Result_t
vdup_n_type
(
Scalar_t
N
);
Result_t
vdupq_n_type
(
Scalar_t
N
);
Result_t
vmov_n_type
(
Scalar_t
N
);
Result_t
vmovq_n_type
(
Scalar_t
N
);
Result_t
vdup
<
q
>
_lane_type
(
Vector_t
N
,
int
n
);

3.2.9 Data processing
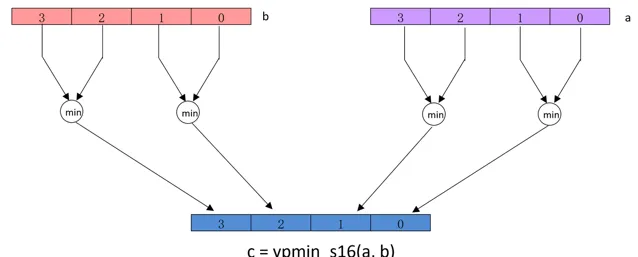
// 基本的 max, min
Result_t
vmax
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vmin
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// pairwise 型別的 max, min
Result_t
vpmax_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vpmin_type
(
Vector1_t
N
,
Vector2_t
M
);
// 基本的絕對值計算
Result_t
vabs
<
q
>
_type
(
Vector_t
N
);
// 差的絕對值操作
Result_t
vabd
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// L(Long)型別, 差的絕對值
Result_t
vabdl_type
(
Vector1_t
N
,
Vector2_t
M
);
// 差的絕對值,並和另一個向量相加
Result_t
vaba
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
// L(Long)型別, 差的絕對值,並和另一個向量相加, 輸出是輸入長度的兩倍
Result_t
vabal_type
(
Vector1_t
N
,
Vector2_t
M
,
Vector3_t
P
);
// 基本的取反操作
Result_t
vneg
<
q
>
_type
(
Vector_t
N
);
// Q(Saturated)型別,帶飽和的取反操作
Result_t
vqneg
<
q
>
_type
(
Vector_t
N
);
// 統計每個通道 1 的個數
Result_t
vcnt
<
q
>
_type
(
Vector_t
N
);
// 從符號位開始,統計每個通道中與符號位相同的位的個數,且這些位必須是連續的
Result_t
vcls
<
q
>
_type
(
Vector_t
N
);
// 從符號位開始,統計每個通道連續0的個數
Result_t
vclz
<
q
>
_type
(
Vector_t
N
);
// 對每個通道近似求倒
Result_t
vrecpe
<
q
>
_type
(
Vector_t
N
);
// 對每個通道使用 newton-raphson 求倒
Result_t
vrecps
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// 對每個通道平方根近似求倒
Result_t
vrsqrte
<
q
>
_type
(
Vector_t
N
);
// 對每個通道使用 newton-raphson 平方根近似求倒
Result_t
vrsqrts
<
q
>
_type
(
Vector1_t
N
,
Vector2_t
M
);
// N(Narrow) 型別的賦值,取輸入每個通道的高半部份,賦給目的向量
Result_t
vmovn_type
(
Vector_t
N
);
// L(long) 型別的賦值,使用符號拓展或者 0 拓展的方式,將輸入通道的數據賦給輸出向量
Result_t
vmovl_type
(
Vector_t
N
);
// QN(Saturated, Narrow) 型別的賦值,飽和的方式賦值,輸出是輸入寬度的兩倍
Result_t
vqmovn_type
(
Vector_t
N
);
// QN(Saturated, Narrow) 型別的賦值,飽和的方式賦值,輸出是輸入寬度的兩倍,而且輸入為有符號數據,輸出無符號
Result_t
vqmovun_type
(
Vector_t
N
);
3.2.10 Type conversion
Result_t
vreinterpret
<
q
>
_DSTtype_SRCtype
(
Vector1_t
N
);
Result_t
vcombine_type
(
Vector1_t
N
,
Vector2_t
M
);
Result_t
vget_high_type
(
Vector_t
N
);
Result_t
vget_low_type
(
Vector_t
N
);
四、NEON intrisics 指令在x86平台的仿真
為了便於 NEON 指令從 ARM 平台移植到 x86 平台使用,Intel 提供了一套轉化介面
NEON2SSE
,用於將 NEON 行內函式轉化為 Intel SIMD(SSE) 行內函式。大部份 x86 平台 C/C++編譯器均支持 SSE,因此只需下載並包含介面表頭檔
NEON_2_SSE.h
,即可在x86平台偵錯 NEON 指令程式碼
。
#ifdef ARM_PLATFORM
# include <arm_neon.h>
#else
# include "NEON_2_SSE.h"
#endif
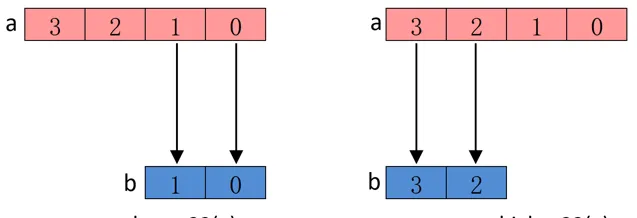
效能方面:
五、 NEON指令的套用
本節將會結合實際套用場景介紹 NEON 指令的使用方法。
5.1 RGB de-interleave 載入 / interleave 儲存
使用
vld3q
以解交織的方式載入 RGB 影像;
vst3q
以交織的方式儲存 RGB 影像。
// 輸入地址為 in_ptr, 輸出向量為 vec
uint8x16x3_t
vec
=
vld3q
(
in_ptr
);
// 輸出地址為 out_ptr, 輸入為 uint8x16x3_t 型別的 RGB 向量
vst3q
(
out_ptr
,
vec
);

5.2 查表操作
大多數的重排操作中,重排模式都是固定的,這在使用上帶來了一定的局限性。
NEON 在常規重排指令外,支持使用
TBL
和
TBX
指令來完成任意模式的重排操作,這兩條指令本身也是查表指令。
TBL
和
TBX
輸入參數介紹:
TBL
和
TBX
的不同在於:當沒有索引值超過範圍時,
TBL
返回 0,
TBX
保持原有目的數據不變。
// a表示table, b表示index, c表示結果
uint8x8_t
c
=
vtbl2_u8
(
a
,
b
)
5.3 邊緣處理
處理影像邊緣時,經常會有使用常數填充邊界的情況。
NEON 開發中,可以使用
DUP
指令將常數填充到向量中,然後使用
EXT
指令組建新向量。
// 構造邊界填充向量
uint8_t
c_0
=
0
;
uint8x8_t
v_c0
=
v_dup_n_u8
(
c_0
);
// 構建v_1
uint8x8_t
v_1
=
vext_u8
(
v_c0
,
v_0
,
5
)
// 使用 vext 構建邊界向量,v0 表示從縱座標為 0 起始的向量
uint8x8_t
v_border
=
vext_u8
(
v_1
,
v_c0
,
3
)
5.4 SAD操作
SAD(sum of absolute difference) 運算可以使用 NEON 指令來加速。
// 初始化 v_sum 和 v_c1
uint32x4_t
v_sum
=
vmovq_n_u32
(
0
);
uint8x16_t
v_c1
=
vmovq_n_u8
(
1
);
// v_src0, v_src1為兩幅圖的輸入
// 將做差的絕對值計算
uint8x16_t
v_abd_res
=
vabdq_u8
(
v_src0
,
v_src1
);
// 做 vdot操作
v_sum
=
vdotq_u32
(
v_sum
,
v_abd_res
,
v_c1
);
...
// 將最後的結果累加
uint32_t
res
=
vaddvq_u32
(
v_sum
);
六、總結
本文主要介紹了 NEON 指令相關的知識,首先透過講解 arm 指令集的分類,NEON寄存器的型別,樹立基本概念。然後進一步梳理了 NEON 組譯以及 intrinsics 指令的格式。最後結合指令的分類,使用例子講述 NEON 指令的使用方法。
七、附錄
參考資料
[1] ARM Neon Programmer's Guide
[2] ARM NEON programming quick reference
[3] ARM Architecture Reference Manual Armv8, for A-profile architecture
[4] https:// developer.arm.com/archi tectures/instruction-sets/intrinsics/











