編輯:Aeneas 好困
【新智元導讀】 OpenAI第二天的直播,揭示了強化微調的強大威力:強化微調後的o1-mini,竟然全面超越了地表最強基礎模型o1。而被阿特曼稱為「2024年我最大的驚喜」的技術,技術路線竟和來自字節跳動之前公開發表的強化微調研究思路相同。
OpenAI 12天連播的第二彈,用短短三個單詞體現了什麽叫「字少事大」——強化微調(Reinforcement Fine-Tuning)。

首先,這是OpenAI第一次將之前僅限自家模型(如GPT-4o和o1系列)使用的強化學習技術,開放給外部開發者。
其次,開發者只需提供最低「幾十個」高品質任務,就能透過強化微調實作領域專家模型的客製!並且,還能根據提供的參考答案對模型的回應進行評分。
最後,強化微調加強了模型在處理領域問題時的推理能力,並提升了在特定任務上的準確性。對於那些要求高精確性和專業知識的領域,強化微調將會發揮至關重要的作用。
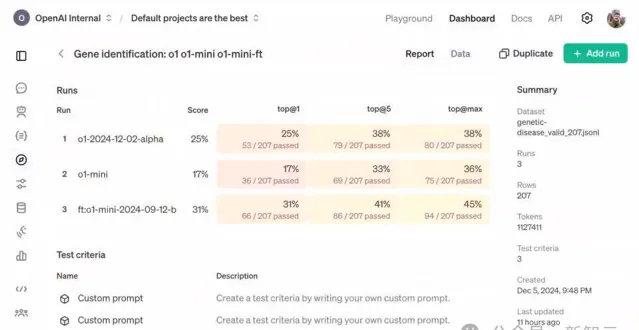
從OpenAI的官方演示中不難看出,強化微調的效果可謂是相當顯著——經過強化微調的o1 mini,竟然全面超越了當今最強的基礎模型o1。
其中,強化微調版的o1 mini,在Top-1準確率上直接躍升180%達到了31%,遠超o1的25%。
對此,阿特曼激動地表示:「這項工作效果出奇得好,是我2024年最大的驚喜之一!非常期待大家會用它去構建什麽。」
目前,強化微調研究計劃已進入Alpha階段,並將於2025年第一季度公開釋出。

為了搞清楚「強化微調」到底是個啥,我們便去問了問OpenAI自家的AI搜尋。
沒想到,結果卻出人意料——這個技術思路,在一篇被ACL 2024錄用為Oral的論文中,就已經提出了。
而更喜人的是,團隊的成員全部來自字節跳動!

在這項工作中,研究人員提出了一種簡單而有效的方法,來自增強LLM推理時的泛化能力——強化微調(Reinforced Fine-Tuning,ReFT)。

論文地址:https://arxiv.org/abs/2401.08967
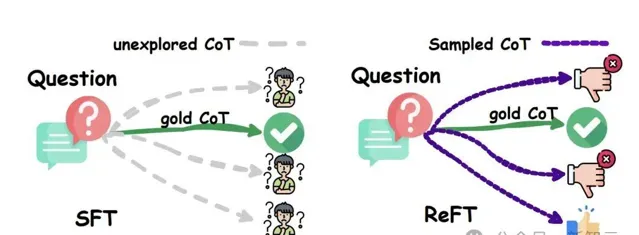
簡單來說,ReFT首先會使用 SFT 對模型進行預熱,然後采用線上強化學習(PPO演算法)進行最佳化。
也就是,對給定的問題自動采樣大量的推理路徑,並根據真實答案來獲取獎勵,從而進一步對模型進行微調。
在GSM8K、MathQA和SVAMP數據集上的大量實驗表明,ReFT顯著優於SFT,並且透過結合多數投票和重新排序等策略,可以進一步提升模型效能。
不僅如此,ReFT還有著卓越的泛化能力——在訓練中僅需使用與SFT相同的問題集,而無需依賴額外或增強的訓練數據。
強化微調,不是傳統微調
這次上陣直播的四人,是OpenAI的研究員 Mark Chen 、John Allard、Julie Wang,以及柏克萊實驗室計算生物學家Justin Reese。

他們介紹說,這項功能已允許使用者在自己的數據集上微調o1。
不過要強調的是,並不是傳統的微調,而是強化微調。它真正利用了強化學習演算法,把模型從高級中學水平提升到專家博士級別。
這個功能,能夠幫助把自己的優質數據集轉化為獨一無二的用品,帶來「魔力」。
強化微調(RFT),能讓開發者、研究人員和機器學習工程師首次有機會使用強化學習來建立專家級模型,在特定領域的任務中有卓越表現。
對於法律、金融、工程、保險等領域,這項技術簡直是量身打造的。
舉例來說,OpenAI最近和湯森路透合作,利用強化微調對o1 Mini進行了微調,使其成為了一名法律助手,幫法律專業人士完成了一些復雜、需要深入分析的工作流程 。
史上首次,OpenAI微調支持強化學習
去年年初,OpenAI就推出了監督微調API。這項技術非常強大,核心目標是讓模型復制在輸入文本或影像中發現的特征。
在強化微調中,它不僅是教模型模仿輸入,而是去學習在自訂域上以全新的方式進行推理。
當模型看到一個問題,研究者會給它空間來思考問題,然後給它的最終答案進行評分。
然後,利用強化學習的強大能力,他們會強化那些導致正確答案的思維路徑,同時抑制那些導致錯誤答案的思維路徑。
只需要數十到數千個高品質範例,模型就能學會以新的、有效的方式在客製領域中進行推理了!
用OpenAI研究者的話說,這實在太瘋狂了,令人難以置信——僅用12個例子就能做到,這是傳統微調難以實作的。
這也是史上首次,OpenAI的模型客製平台可以支持強化學習。
研究者強調說,OpenAI內部用來訓練GPT-4o和o1系列等頂尖模型,就是用的同樣技術。
強化微調的o1,診斷罕見病
柏克萊實驗室的Justin,就介紹了強化微調給他的研究帶來的巨大幫助。

他研究的是,使用計算方法來理解罕見疾病背後的遺傳原因。
然而,現在評估罕見疾病並不容易,首先要對醫學有專業領域知識,還要對生物醫學數據進行系統化推理。
而這,o1模型可以憑借其高級推理能力提供幫助。
在這個計畫中,Justin和同事們從數百篇關於罕見疾病的科學病例報告中提取了疾病資訊,包括患者的體征和癥狀。
他們希望能根據患者的癥狀,找出可能發生突變、導致這些癥狀的基因。
為此,他們和OpenAI團隊一起訓練了o1模型,讓它更高效地推理疾病的成因。
而在「根據一系列癥狀預測可能引發遺傳疾病的基因」這一任務上,o1-mini的表現超越了o1!
這非常重要,因為o1-mini比o1更小、更快、成本更低。
在OpenAI的開發平台上,他們已經對一個模型進行監督微調一年多了。
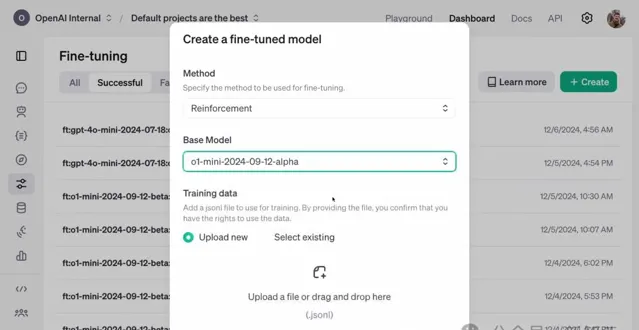
他們上傳了一個訓練數據集,包含1100個範例。
以下是一個單獨的數據點,包括病例報告、指令、正確答案三個部份。

病例報告顯示,這是一名51歲的女性,有眼距增寬、 副甲狀腺功能亢進 等癥狀。 在指令部份,研究者會提示模型,希望它做什麽。 最後就是正確答案。
註意,訓練過程中,並不會向模型展示這個答案,否則就是作弊了。
但是,研究者以這訓練過程中用這個答案來評估模型。
可以看出,這個任務的難度,已經遠遠超越了「Strawberry中有幾個r」的級別。
接下來,他們上傳了一些驗證數據,它的格式與訓練數據完全相同,但驗證數據集和訓練數據集之間的正確基因沒有重疊。
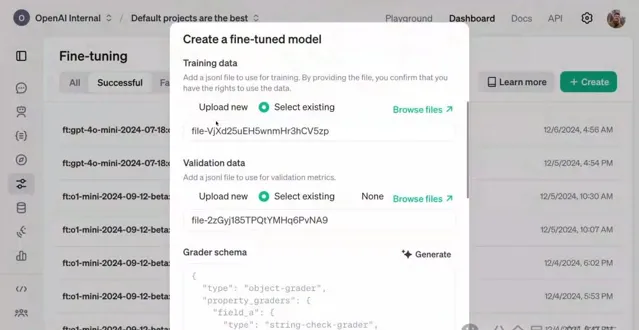
這就意味著,模型不能作弊,不能只是簡單地記住癥狀列表並將其與基因匹配。
它必須真正從訓練數據集泛化到驗證數據集。
強化學習的部份,是這樣體現的——
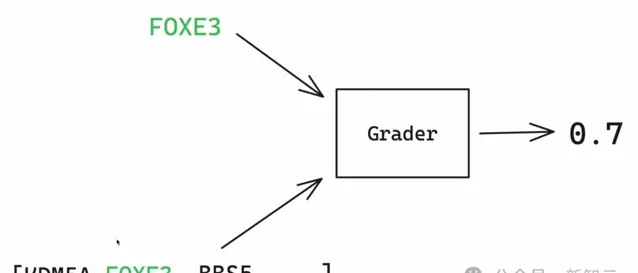
他們引入評分器的概念,將模型輸出與正確答案比較,返回0到1之間的一個分數。0表示模型完全錯誤,1表示模型完全正確。
在這個例子中,模型得到了0.7的分數,因為FOXE 3是正確答案,在基因列表中排第二位。
它在列表中越往後,分數會越接近0。
最終,研究者提供了一套評分器合集,能有效覆蓋在強化微調時可能會有的各種意圖空間。
接下來,可以快速地復制一下評分器,然後就啟動了一個訓練任務。
厲害的地方在於,只需要提供數據集和評分器(體現領域專業知識),就可以利用OpenAI強化學習演算法的全部能力,以及完整的分布式模型訓練技術棧,來為自己的使用場景客製一個前沿模型了。
一句話就是:拿上你的數據集和評分器,OpenAI就會給你一個微調模型。
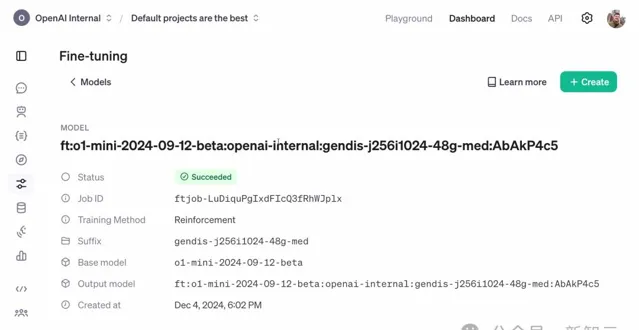
強化學習微調任務可能需要幾個小時到幾天的時間來執行
可以看到,驗證集的獎勵分數呈上升趨勢。
由於訓練數據集和驗證數據集之間的基因沒有重疊,這意味著:模型確實學會了這項任務中進行泛化!
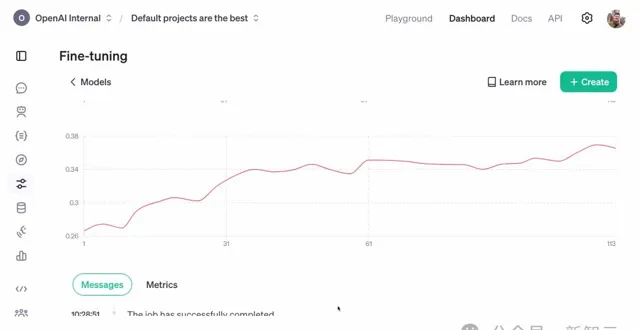
模型學會通用推理能力
為了更深入地了解模型中微調過程中發生了什麽變化,可以檢視評估儀表板。

其中,研究者設定了三個不同執行,分別是執行在o1、o1 mini和強化微調後的o1 mini上的任務。
可以看到,獎勵分數呈現右上角上升的趨勢,但這對任務來說意味著什麽呢?
為此,他們設定了三個不同的評估指標,分別是Top-1(第一項正確率)、Top-5(前五項正確率)和Top-max(是否包含正確答案)。
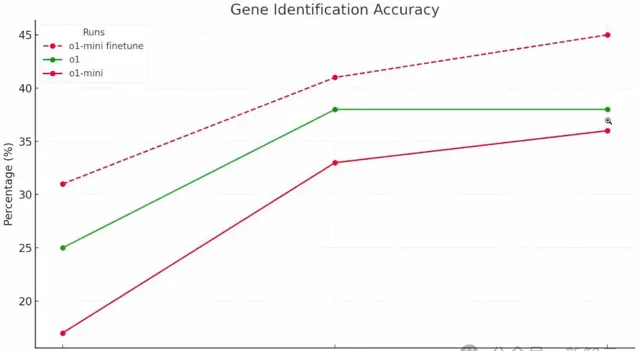
在Top-1指標中,o1 mini在約200條數據上的得分是17%。o1得到了25%,而微調後的o1 mini,得到了31%。
ChatGPT就此生成了一張更直觀的圖表。
這顯示出,模型確實學會了如何在這類數據上進行推理的通用能力!
在Justin看來,強化學習將極大地振奮生物學研究社群,近期內的最佳方案,可能就是結合現有生物資訊學工具和類o1模型的混合解決方案。
而以上,僅僅是強化微調在科學研究中的一個套用而已。
除了已經驗證的生物化學、AI安全、法律以及醫療保健數據集,模型還會在數百種其他套用場景上發揮作用。
OpenAI的Alpha計劃,會讓更多人在最重要的任務上,推動o1模型能力的邊界。
直播最後,依然是OpenAI式的聖誕冷笑話一則——
最近,聖誕老人在嘗試制造一輛無人駕駛雪橇,但不知為何,他的模型總是無法辨識樹木,導致雪橇不停地撞上道路兩旁的樹。你們猜這是為什麽?
答案是:因為他忘了給模型進行「pine-tune」(松樹微調)!











