編輯:編輯部 HYZ
【新智元導讀】大模型下一個突破口在哪?商湯「日日新」原生融合大模型一舉拿下雙料冠軍,給出了最好的答案。一個模型精通「看」與「想」,原生多模態融合讓AI邁入「大一統」新紀元。
大模型發展到今天,下一步該走向何方?
就在剛剛,商湯給出了答案——原生融合模態!
最近的CES大會上,輝達提出能理解世界的「世界模型」Cosmos,能夠將文本、影像、視訊作為輸入。

英雄所見略同,憑借著十年的深耕和AI賦能場景的經驗,商湯也認為,原生融合是世界模型的必經之路。
或者說,多模態模型,是AI 2.0進行場景落地的必由之路。
就在最近,商湯「日日新」融合大模型上線了!
一個模型,就實作了多模態的融合。這是商湯率先在原生融合模態上取得了實質性突破,成為業界在這一領域的領跑者。
這一突破標誌著,大語言模型和多模態模型普遍分立的現狀,從此刻邁向真正意義上的「大一統」時代!
跨模態互動融合,通往世界模型的必經之路
一般來說,LLM的工作原理,是根據提示一次生成一個token產生輸出。如果上下文變成了現實周圍環境,大模型就需要從生成「內容token」轉變為生成「動作token」。
隨著AI落地到各種場景,它需要對多維度、多模態的資訊有感知、理解、分析、判斷,如果模型不能有效綜合處理這些模態,模型的智慧水平就會很容易達到天花板。
原生模態融合之所以如此意義重大,就是因為實作之後,模型就不止能達到「看」和「想」的水平,而是可以幫助人類解決更多復雜問題。
看不清的字型,數據圖表裏的資訊,文學創作與撰寫,舉棋不定的遊戲……現在,這些任務全部可以實作了。
實測:模型會看,還會想
接下來,不如看看「日日新」融合大模型在實際任務中的表現。
無論是非常難認的英文手寫詩,還是俄文手寫詩,它都能認出來。
上傳一張幾乎難以辨認的英文手寫體詩歌,日日新竟毫不費力地讀出了每一行詩。最關鍵的是,它還完整復刻原文的書寫格式。

再比如這張俄語詩歌,對於非母語的人來說,大腦只剩一片空白。
對於日日新來說,簡直小菜一碟,不僅準確寫出了原文詩句,還順便把它轉譯成了比較有意境的中文版。

有了日日新,對於拍題寫作業的學生們來說,簡直就是絕絕子。
以往,你可能需要將題目打成文字,發給AI去解,而現在拍題、解答能夠一並交給AI。
將附有自己解答的一道題圖片上傳,AI一眼就辨認出錯誤點。而且,它還能做到舉一反三,完全就是學習神器。

還有一些讓人笑出鵝叫的小學生錯題,日日新能完美解讀答案好笑在哪裏。

爆笑小學生作文的幽默之處,它都能get。

同樣的,日日新非常精準指出了這幅畫作的特點——捕捉到了狗的神態和動作。
對於如何提升畫技,它又給出了行之有效的方式。

再上傳一張雕像的圖片,它能辨識出圖中歷史人物,並分析出對應的歷史典故。
甚至,它還能透過一張遊戲的截圖,分析出電腦的具體配置,從CPU、到GPU,再到記憶體,都逐一列了出來。
透過以上要點,它推斷得出可以該電腦可跑大模型。

上傳一張圖,日日新就能分析出程式碼實作了什麽。

一張國外網友制作的表情包,日日新也能夠準確領會圖中的要點。
它認為,人類正在AGI的爬坡上,若要實作真正的AGI,還需要更多研發和工作。對於另一個問題,也看懂了Sam Altman本人正逐步逼近ASI。

再比如,這張大模型智商大比拼圖中,數位雜多,我們想要了解o3和o1的智商如何,直接扔給日日新就可以了。
對於AI來說,一眼就看出了圖中o3 IQ為157,o1 IQ為135。它還給出了這個評測的標準,以及Codeforces背景資訊介紹。
當被問到更為發散的問題——o3與愛因史坦誰更聰明時,日日新非常客觀地看待這個問題。
若要從最直接的IQ結果來看,愛因史坦比o3聰明些,但AI還綜合考慮了智力評測的多個維度進行分析。

而世界模型的到來,或許還意味著能對地球和人類更好的理解,找到和宇宙對話的方法。

文科超越o1全球第一,理科國內金牌
同樣,多方的評測結果也證明,商湯果然摸到了一條正確的路。
完成訓練後的商湯「日日新」融合大模型,首次出戰即拿下語言和多模態兩個榜單的雙料冠軍。
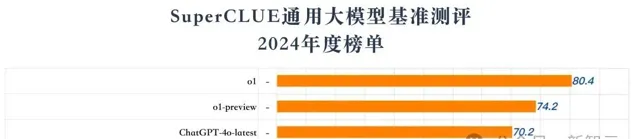
近日,SuperCLUE 2024年度榜單中,「日日新」融合大模型以68.3高分,與DeepSeek V3並列國內榜首,成為年度第一
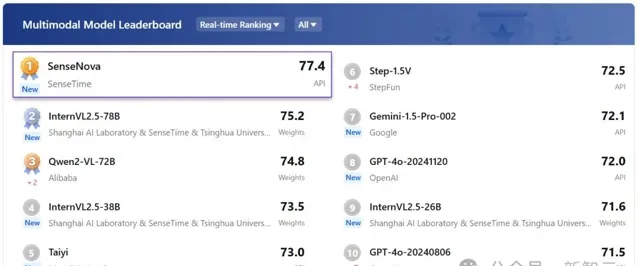
同時,在OpenCompass多模態評測中,同一款模型更是力壓GPT-4o,獨占鰲頭
具體來看,SuperCLUE覆蓋了29個國內模型,聚焦大模型的通用能力測評,由理科、文科和Hard三大維度構成。
而此次獲得68.3高分的商湯「日日新」融合大模型,直接超越了Claude 3.5 Sonnet和Gemini-2.0-Flash-Exp。
令人印象深刻的是,「日日新」在各項能力上表現均衡,在三大維度上均處領先。
在文科任務上,它以81.8分位列全球第一,超越OpenAI的o1和GPT-4o-latest。

而在理科任務上,它直接奪得了金牌,其中計算維度以78.2分位列國內第一並超過GPT-4o-latest。

如此驚艷的表現,是否需要很高的成本呢?
好訊息是,融合模態模型訓練的成本也並不高。相比同樣量級的LLM,訓練成本也就是增加20%左右。
原因在於,這實際上是一個多階段的訓練,語言模式和多模態模式的訓練合在了一起,因而只用了1.2倍左右的成本。
技術路線:原生融合多模態
深挖背後,離不開商湯在 「原生融合多模態」 ——一條獨特且富有前瞻性的技術發展路徑上,取得的創新突破。
在大模型百舸爭流的當下,各家都在積極布局多模態,但技術路徑的選擇卻大不相同。
通常來講,業內普遍采用了分離式架構,多模態和語言模型分步訓練,然後再透過中間層實作功能整合。
從實際套用角度來考慮,語言只是資訊的一部份,世界中很多資訊可能是以影像、視訊等形態存在的。
如果不能有效綜合處理這些資訊的話,那麽這個模型的能力很快就會觸及到天花板。
商湯認為, 融合多模態是未來的一條必由之路,其技術最顯著的特點是「單一模型,多模態融合」 。
直白講,單一模型同時訓練和處理多模態,成為一個原生的多模態模型。
這也就意味著,在一個統一的模型框架內,同時具備了處理文本、影像、視訊、音訊多種模態資訊的能力。
值得註意的是,商湯選擇的這條技術路線,與OpenAI、Anthropic、谷歌同頻共振。比如,GPT-4o、Claude 3.5、Gemini 2.0都采用了類似的單一模型融合多模態的技術路徑。

正如商湯聯合創始人、人工智慧基礎設施及大模型首席科學家林達華所言,這種策略的選擇,帶來了顯著的優勢——
首先,在訓練成本方面,相較於分別訓練兩個模型的方案, 融合多模態方案僅增加20%的訓練成本,就能獲得等效的能力 。
其次,這種一體化設計在處理多模態任務時,更為高效和自然。
那麽,既然這條原生融合技術路線是必由之路,我們又該如何去實踐它,至今沒有具體方法論,也無人能效仿。
實際上,從去年年底開始,原生多模態大模型就逐漸成為業內探討的重要方向。
然而由於數據和訓練方法的局限,業內很多機構的嘗試並不成功——多模態訓練過程往往會導致純語言任務,尤其是指令跟隨和推理任務的效能嚴重下降。
在這個充滿挑戰的賽道上,商湯憑借其在CV領域十年深厚積累,給出了獨一份解決之道。
他們獨創性提出了兩項關鍵技術——融合模態數據合成與融合任務增強訓練。
融合模態數據合成
NeurIPS演講上,Ilya曾當眾宣布當前AI行業已達到「數據峰值」。無獨有偶,馬斯克最近直播中也稱,「我們基本上已經把AI訓練中能利用的人類知識都挖空了」。
互聯網數據幾近枯竭,早已成為屢見不鮮的話題。

業界一致將希望寄托於「合成數據」身上,就比如,OpenAI曾被曝出用合成數據,來輔助訓練下一代模型Orion;Anthropic利用Claude 3.5 Opus生成合成數據提升模型效能。
不僅如此,還可以從微軟Phi系列模型中,可以看到合成數據的巨大潛力。
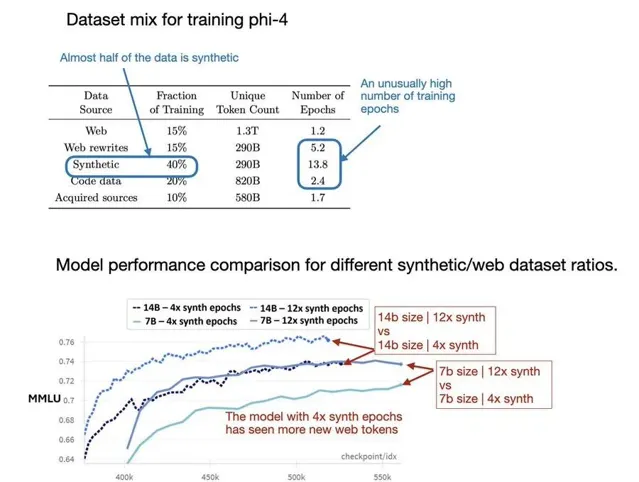
最新Phi-4合成數據比例高達40%,而且增加合成數據訓練epoch,比純增加互聯網數據,效能提升效果更明顯
可以證明,合成數據是能夠緩解數據不夠的一種方法。
商湯在融合多模態技術路線最大的創新之一,便是 「融合模態數據合成」 。那麽,他們是具體如何做到的呢?
在研究過程中,團隊發現,當更多的數據和模態用一種有效和有機的方式融合在一起進行訓練時,模型在不同環節和方向上都表現出更優的效能。
跟AI 1.0時代相比,這是很不一樣的。當時,一個模型的能力非常有限,如果同時訓練它做兩件事情,可能兩件事都做不好。
然而在大模型時代,在不同的場景都可以觀察到——
相比單一模態(如單純的語言或圖文模式),多模態有機融合的模型在智慧水平上有顯著提升。
在越來越多的工作中,都可以觀察到這種現象:隨著更多的模態進行有機的融合,模型會湧現出更強的智慧水平。
這種多模態技術在實踐中的巨大潛力,已經在商湯絕影自動駕駛核心模型中得到了套用。
而在預訓練階段, 商湯不僅采用了天然存在的海量圖文交錯數據,還透過逆渲染、基於混合語意的影像生成等方法合成了大量融合模態數據 。
由此,團隊就成功在圖文模態之間建立起大量互動橋梁,使得模型基座對於模態之間的豐富關系掌握得更紮實,因而能更好地完成跨模態任務,提升了整體效能。
融合任務增強訓練
在完成預訓練之後,模型還要針對多項任務進行增強訓練。
不難理解,只有融合模型對實際套用場景有了深刻洞察,在場景驅動下,才能實作落地開花。
就好比一個大學生,學了很多知識,在進入社會之前,需要一些實操磨練,才能真正走進崗位。
融合多模態模型也是如此,為此,商湯基於多年來對廣泛業務場景的認知,構建了一系列跨模態任務。
具體涵蓋了互動、多模態文件分析、城市場景理解、車載場景理解等等。
透過把這些任務融入到增強訓練的過程,模型不僅被激發出強大的對多模態資訊進行整合理解分析的能力,而且還形成了對業務場景有效的響應能力。
在這個過程中,模型就走通了套用落地反哺基礎模型叠代的閉環。
只有真正做到多模態的互動與深度融合,才能讓模型走向統一,也是通向世界模型的必經之路。
目前,基於「日日新」融合大模型,商湯已經在多個實際場景中取得了突破的成果。
擴充套件套用新維度
在很多B端套用、商業競爭上,商湯已經具備了較大優勢。
在辦公、金融領域,經常會用到很多復雜的多模態文件,比如表格、文本、圖片、視訊等,以及以上形式的融合。
那麽,面對如此豐富復雜的資訊,融合大模型就有了非常大的優勢。
基於「日日新」打造的 「辦公小諾古力」 ,便能夠高效處理多種格式的辦公文件,智慧分析復雜業務數據,還能提精準的資訊提取服務。

甚至許多已經在媒體上釋出的圖文並茂的文章,都會得到多模態的綜合解讀。
在前文已經提到的 自動駕駛領域 ,原生融合模態模型就大有可為。
未來,乘客或司機可以靠語音去和車載智慧體對話。智慧體既能看到車裏、車外的狀態,感知各種訊號,還能和人做文字模態的語音互動。
還有一個場景,就是視訊互動 。
商湯已釋出的日日新5o,就是基於視訊即時互動的套用。人可以在一個視訊的場景下,去跟機器交流,無論的語言還是畫面,AI都需要結合在一起去理解。
協助城市治理、園區管理的場景中,原生融合模態模型也將提供極大的助力,為客戶提供文字、影像、視訊材料結合的回答。
去年10月,商湯CEO徐立公開了商湯接下來10年 「大模型、大裝置和套用」三位一體的整體戰略 。
現在,多模態融合的大模型已經成為商湯AI 2.0的基座,承載了互動變革、提升生產力助手兩個套用方向。
隨著商湯把融合模態的技術路徑整體走通,一個全新的想象空間已經開啟。
未來,整個空間結構將會如何輸入?跟LLM和推理能力將怎樣結合?
走通了通道和方法論的商湯,必將探索的觸角伸向更多範疇。
參考資料:
https://chat.sensetime.com/











