編輯:桃子 好困
【新智元導讀】大模型戰場上的硝煙可能先要告一段落了。OpenAI明年初將釋出「Operator」智慧體工具。與此同時,谷歌正準備年底推出「賈維斯」助手。AI智慧體或許是2025年挽救LLM的救星。
大模型卷不動,該卷智慧體了?

阿特曼剛剛發文:根本就沒有墻
彭博最新爆料稱,OpenAI計劃在2025年1月初,重磅推出AI智慧體工具「Operator」。
它可以透過電腦,代表一個人寫程式碼、預定行程完成任務。
正如Claude 3.5所展示的,AI可以自主操控電腦一樣。

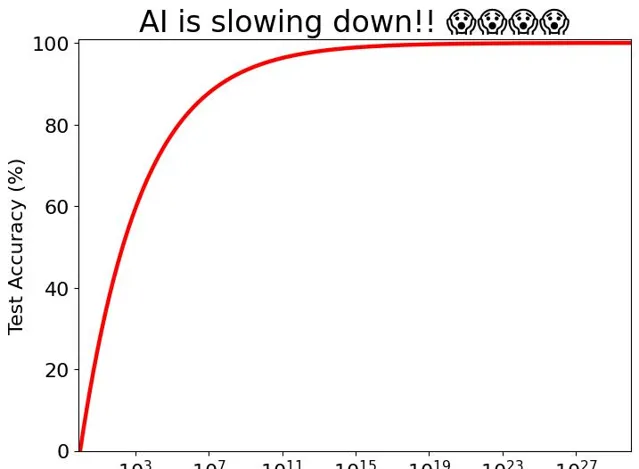
之所以釋出AI智慧體,或許是因為OpenAI內部已經觸及到大模型Scaling Law的邊界了。
幾天前,Information、路透接連曝出LLM進展放緩,而彭博的最新文章又為之添上一把火。
OpenAI、谷歌、Anthropic三家AI公司,在新模型上開發付出很多,但報酬越來越少。

一家初創公司聯創Josh Miller道出箴言:如果這些傳言是真的,那麽2025年將是「AI界面」幫助LLM跨越鴻溝的一年。現有的前沿模型已經如此強大,但沒有得到充分利用。

對此,OpenAI微調研究員稱,「即便是LLM進展完全停滯(然而現在並不是),基於當前的模型至少有十年的產品可以開發」。
這些話所暗含之意,便是OpenAI智慧體釋出的合理性。
AI智慧體升溫,OpenAI年初釋出
誠然,隨著LLM研發成本居高不下,各大AI實驗室正面臨著巨大的商業化壓力。
單純的模型效能提升,已經難以說服使用者接受更高的價格。
而自主智慧體,被視為下一個可能帶來突破性的產品。
周三的員工會議上,OpenAI領導層宣布了計劃在明年1月,釋出代號為「Operator」的全新AI智慧體預覽版本。
並且, 將透過API向所有開發者開放。
據知情人士透露,OpenAI內部一直在進行多個與智慧體相關的研究計畫。最近得到的一個雛形是,在網路瀏覽器中執行任務的通用工具。
倫敦開發者日之後的Reddit AMA上,阿特曼在問答環節中曾暗示了向智慧體轉變的趨勢。
他表示,「我認為下一個巨大的突破將是AI智慧體」。
在OpenAI新聞釋出會上,首席產品官Kevin Weil同樣稱,「我認為2025年將是智慧體系統最終成為主流的一年」。
對此,OpenAI暫未回復彭博置評請求。但此舉,也是整個行業在智慧體發展布局的重要一環。
10月下旬,Anthropic先發「電腦使用」,並將其稱之為全新人機互動範式的第一步。

Claude 3.5能夠像人類一樣操作電腦,不僅可以檢視螢幕、移動光標,還可以單機按鈕、鍵入文本。
比如,金門大橋和自己所在地的距離,Claude 3.5會自己開啟地圖進行尋找。
微軟在最近也推出了一套智慧體工具,幫助企業員工發送電子信件、管理記錄等等。
谷歌也在準備年底釋出代號為「Project Jarvis」的智慧體,將由Genimi 2.0驅動。
它專門針對谷歌瀏覽器Chrome做了最佳化,幫助人們收集資訊、購買商品、訂機票等等。幾天前,Jarvis被意外泄露,原型被設定為「一個與你一起上網的有用伴侶」。

還有Meta、蘋果、亞馬遜等科技大廠,都將在這一領域掀起一番風浪。
業界希望的是,智慧體能夠希望像ChatGPT一樣掀起新一輪革命,從而證明當前他們在AI領域的巨額投資是值得的。
OpenAI、谷歌和Anthropic全部遭遇瓶頸
畢竟,如今尋找新的、未開發的高品質人工訓練集,來構建更先進的AI系統變得越來越困難。
這些問題挑戰了近年來矽谷的主流觀點,特別是自從OpenAI兩年前釋出ChatGPT以來。
科技巨頭們都在押註於所謂的Scaling Law,紛紛認為只要有足夠的算力、數據、更大的模型。必然會為AI能力的巨大飛躍鋪平道路。
然而,在這三個方向上的暴力美學,並沒有預想的那麽有效。

在OpenAI內部,研究人員對Orion已經開展了為期數月的後訓練過程(post-training),包括整合人類反饋改進響應、完善模型與使用者互動的語氣等等。
但Orion的最終輸出效果,仍未及OpenAI的預期,即可以向使用者釋出的水平。
一位知情人士透露,明年年初之前,OpenAI不太可能釋出旗艦Orion。
最近的挫折也引發了人們的質疑,不僅對AI的大規模投資,還包括這些公司正在積極追求的一個終極目標的可行性:通用人工智慧(AGI)。
阿特曼稱,「AGI將在2025年到來」。Anthropic執行長Dario Amodei預測,「若沒有其他外部阻力因素,AGI可能在2026/2027年到來」。

對此,Hugging Face的首席倫理科學家Margaret Mitchell表示,「AGI泡沫正在逐漸破裂」。
她指出,「我們現在清楚地認識到,可能需要采用不同的訓練策略,才能使AI模型在各種任務上都表現出色」。而這一觀點得到了許多AI專家的認同。
眾所周知,OpenAI並非唯一一個最近遭遇瓶頸的公司。
短短幾年以驚人速度推出越來越強大AI之後,谷歌、Anthropic都在新模型的開發上遇到了邊際效益遞減。
據稱,谷歌即將推出的Gemini新版本未能達到內部預期。同時,備受期待的Claude 3.5「超大杯」Opus的時間表再次延遲。
緊隨OpenAI腳步,谷歌改變策略,成立新小組
今天,The Inforamtion深挖了谷歌內部模型的一些進展。
知情人士透露,谷歌最近在Gemini對話式AI方面的進展速度,不及去年。
盡管投入了更多的算力、訓練數據(如互聯網文本和影像),新版Gemini仍未能達到期望的效能提升。
(而過去版本的Gemini,在研究人員使用更多數據和計算能力進行訓練時,改進速度超快。)
這個問題對谷歌來說尤其令人擔憂,因為在使用的開發者和客戶數量方面,Gemini遠遠落後於OpenAI的模型。
一直以來,谷歌希望利用其在計算資源方面的相對優勢,讓模型品質迅速趕超OpenAI。
與此同時,他們都在開發基於現有模型的新產品,有望自動化軟體程式設計師和打工人復雜繁瑣的工作。
這迫使研究人員不得不采取新的策略,來勉強獲得效能提升。
谷歌發言人稱,公司正在重新思考如何處理訓練數據,並「大量投資」數據。此外,谷歌還成功地加快了Gemini生成回答的速度,發言人強調這「對於以谷歌的規模提供AI服務至關重要」。
與此同時,谷歌正借鑒OpenAI推理模型的做法,彌補在模型訓練階段使用傳統Scaling Law所帶來的進展放緩。
最近幾周,DeepMind在其Gemini團隊中組建了一個新的小組,由首席研究科學家Jack Rae和前Character.AI聯合創始人Noam Shazeer領導,旨在開發類似的能力。

另外,據透露,開發Gemini的DeepMind研究人員,也一直專註於對模型進行「手動改進」。
其中便包括調整模型的「超參數」,即決定模型如何處理資訊的變量,比如它如何快速地在訓練數據中的不同概念或模式之間建立聯系。
研究人員在為模型調優的過程中,測試不同的超參數,以確定哪些變量能帶來最佳結果。
不過,谷歌並非完全從0開始。
谷歌研究人員此前就發明了OpenAI推理模型背後的一項關鍵技術——CoT,只是論文一作Jason Wei後來加入了OpenAI,在那裏繼續深化這項技術的研究。

論文地址:https://arxiv.org/pdf/2201.11903
不僅如此,谷歌在其傳統方法中還遇到了一個問題:在用於開發Gemini的訓練數據中發現了「大量重復資訊」。
他們表示,這種數據重復可能降低了Gemini的效能表現。對此,谷歌發言人表示,這類問題對研發團隊來說並不陌生。
谷歌此前寄希望於透過合成數據,以及音訊和視訊作為Gemini訓練數據的一部份,能夠帶來顯著效能提升,但這些嘗試似乎並未產生預期的重大突破。
對此,谷歌發言人表示,Gemini模型「在處理音訊和視覺資訊方面已經展現出強勁的效能,我們將繼續探索和推進多模態功能。
谷歌之外,Anthropic也被曝出暫緩Opus 3.5的釋出。
Anthropic超大杯不及預期
今年3月,Anthropic釋出了三個新模型,並表示其中最強大的選項Claude Opus在關鍵基準測試上(如研究生水平的推理能力和編程)的表現超過了OpenAI的GPT-4和谷歌的Gemini。
在接下來的幾個月裏,Anthropic推出了其他兩個Claude模型的更新——但沒有更新Opus。
就在10月份,官網上與3.5 Opus有關的措辭,包括表明它將「在今年晚些時候」到來和「即將推出」等,都被刪除了。這引發了業內對Opus開發進展的猜測。
知情人士表示,Caldue 3.5 Opus在評估中的表現確實比舊版本好,但考慮到模型的規模以及構建和執行它的成本,效能提升並不如預期那麽多。
Anthropic的發言人表示,關於Opus的語言從網站上移除是出於行銷決策,只展示可用和已進行基準測試的模型。
當被問及Opus 3.5是否仍會在今年推出時,該發言人指向了Amodei在播客中的言論。在采訪中,這位CEO表示Anthropic仍計劃釋出該模型,但多次拒絕承諾具體時間表。
數據瓶頸,千億美元訓一個模型
當前,AI巨頭們正面臨著一個關鍵轉折點——僅僅依靠互聯網「野生數據」,已經無法支撐AI向更高智慧邁進。
雖然從大量社交媒體貼文、線上評論、書籍和其他從網路上自由爬取數據,催生了能說會道的ChatGPT,但要構建超越諾獎得主AI系統,可能還需要維基百科條目和YouTube字幕以外的資料來源。
Scaling Law撞墻鬧得沸沸揚揚,圖靈獎得主LeCun下場表示,「雖然但是,我早就說過了...」。
他引述了Ilya接受路透采訪的話,透過擴大預訓練規模——即使用海量未標記數據來理解語言模式和結構的AI模型訓練階段——所獲得的成果已經遇到瓶頸。
「2010年代是scaling的時代,現在,我們再次回到了奇跡和發現的時代。每個人都在尋找下一個奇跡」。
「現在比以往任何時候都更重要的是,Scaling真正有價值的方向」。

為了突破這一瓶頸,各大公司開始改變策略。
特別是OpenAI,已經與出版商簽訂了協定,以滿足部份高品質數據的需求,同時也適應出版商和藝術家對用於構建GenAI產品的數據日益增長的法律壓力。
一些科技公司還在招聘研究生學位的人員,以便對自身專業領域(如數學和編程)的數據進行標註。目標是提升這些系統在回應特定主題查詢時的表現。
毋庸置疑,這些人工操作比單純地爬取網頁內容更耗時、成本更高。
一些公司也在轉向合成數據,但在這方面,也存在著局限性。
正如New Enterprise Associates的AI戰略主管、前微軟副技術長Lila Tretikov所言:
「AI訓練過程中,數據品質和多樣性遠比數量重要。沒有人類知道,即便可以透過合成方法生成大量數據,也難以獲得獨特的、高品質的數據集,尤其是語言方面。」
盡管如此,AI公司仍在繼續追求「more is better」的策略。
在追求構建接近人類智慧水平的產品的過程中,科技公司正在增加用於訓練新模型的計算能力、數據量和時間——同時也推高了成本。
Anthropic CEO Amodei表示,今年公司將花費1億美元來訓練一個最先進的模型,而這個金額在未來幾年將達到1000億美元。
但隨著成本的上升,每個正在開發的新模型的風險和期望也隨之增加。











