看過劇版【三體】的讀者或許都記得一個名場面:來自三體的智子封鎖了人類科技,還向地球人發出了「你們是蟲子」的宣告。但沒有超能力的普通人史強卻在蝗群漫天飛舞的麥田中喊出:「把我們人類看成是蟲子的三體人,他們似乎忘了一個事實,那就是蟲子從來就沒有被真正地戰勝過」。
三體人看到的是單個蟲子脆弱的一面 —— 你可以輕松踩死一只螞蟻,打死一只蝗蟲、蜜蜂。但他們沒有看到的是,當這些蟲子集結在一起時,它們可以湧現出遠超個體簡單相加的力量。

科學家們很早就發現了這種力量,並將其命名為「 群體智慧 」(Swarm Intelligence)。這種智慧不是由某個中央大腦控制,而是透過個體間的簡單互動和資訊交換自然形成的。它是一種集體智慧的體現,是自然界中一種奇妙而高效的協作方式。
其實,從宏觀上說, 人類社會的不斷發展和演化也是一族群體智慧現象 ,絕大多數文明成果都是人類個體在長期群體化、社會化的生產生活中逐漸演化形成的產物。
那麽,人工智慧的發展能否借鑒這種模式?答案自然是「能」。但長期以來,由於機器的個體智慧化程度較低等原因,「群體智慧」遲遲難以湧現。
生成式 AI 的發展或授權以推動這些問題的解決,也讓「群體智慧」獲得了新一輪的關註。
「 這波生成式 AI 相當於把個體的智慧化水平提升上去了。而個體智慧的提升,意味著群體的智慧有望實作指數級增長。 」在近期的一次訪談中, RockAI CEO 劉凡平 向機器之心表達了這樣的觀點。

RockAI 是一家成立於 2023 年 6 月的 AI 初創,他們自研了 國內第一個非 Attention 機制的 Yan 架構通用大模型 ,並將這個大模型部署在了手機、PC、無人機、機器人等多種端側裝置上,還嘗試讓自己的大模型在這些裝置上實作「 自主學習 」能力。
而這一切均服務於一個宏大的目標 —— 讓每一台裝置都擁有自己的智慧,而且是可以像人類一樣即時學習、個人化自主前進演化的系統。劉凡平認為,當這些擁有不同能力、不同個性的智慧單元得以協同,即可完成數據共享、任務分配和策略協調,湧現出更為宏大、多元的群體智慧,最終實作個人化與群體智慧的和諧統一,開啟人與機器的智慧新時代。
那這一切怎麽去實作呢?在訪談中,劉凡平胡鄒佳思(RockAI 聯合創始人)向機器之心分享了他們的路線圖和最新進展。
一條不同於 OpenAI 的 AGI 路線
前面提到,「群體智慧」的研究進展受限於單個個體的智慧化程度,所以研究者們 首先要解決的問題就是讓單個個體變得足夠聰明 。
要說「聰明」,OpenAI 的模型可以說是出類拔萃。但從目前的情況來看,他們似乎更側重於訓練出擁有超級智慧的單個大模型。而且,這條路線走起來並不容易,因為它高度依賴海量的數據和計算資源,這在能源、數據和成本上都帶來了永續性的問題。
此外,透過一個超級智慧模型來處理所有任務是一種高度中心化的模式,這在實踐中容易出現智慧增長的瓶頸,因為單一模型缺乏靈活的適應能力和協作效應,導致其智慧提升速度受到限制。
那麽,OpenAI 未來有沒有可能也走群體智慧的路線?這個問題目前還沒有明確答案。但可以看到的一點是, 以該公司和其他大部份公司當前采用的 Transformer 架構去構建群體智慧的單個個體可能會遇到一些障礙 。
首先是高算力需求的障礙。以 Attention 機制為基礎的 Transformer 架構對計算資源的需求非常高,其計算復雜度為 O (n^2)(n 為序列長度)。這意味著隨著輸入序列的增長,計算成本急劇增加。在構建群體智慧時,我們需要多個單元大模型協同工作,而這些單元大模型往往部署在低算力的裝置上(如無人機、手機、機器人等)。如果不經過量化、裁剪等操作,Transformer 架構的模型很難在低算力裝置上直接部署。所以我們看到,很多公司都是透過這些操作讓模型成功在端側跑起來。
但對於群體智慧來說,光讓模型跑起來還不夠,還要讓它們具備自主學習的能力。在劉凡平看來,這一點至關重要。
他解釋說,在一個沒有自主學習的群體中,最聰明的個體會主導其他智慧體的決策,其他智慧體只能跟隨它的指引。這種情況下,群體智慧的上限就是最聰明個體的水平,無法超越。但 透過自主學習,每個智慧體都可以獨立提升自身的智慧水平,並逐漸接近最聰明的個體 。而且, 自主學習促進了創用CC,類似於人類的知識傳承 。這樣,群體中的所有智慧體都會變得更聰明,群體整體的智慧水平有望實作指數級增長,遠遠超出簡單的個體累加。
而 量化、裁剪等操作最致命的問題,就是破壞了模型的這種自主學習能力 。「當一個模型被壓縮、量化、裁剪之後,這個模型就不再具備再學習的能力了,因為它的權重已經發生了變化,這種變化基本是不可逆的。這就像我們把一個螺絲釘釘入墻中,如果在敲入的過程中螺絲釘受到損壞,那麽想要把它取出來重新使用就變得很困難,讓它變得更鋒利就變得不可能。」劉凡平解釋說。
講到這裏,實作群體智慧的路線其實就已經非常清晰了:
首先,你要在架構層面做出改變,研發出一種可以克服 Transformer 缺陷的新架構。
然後,你要將基於這個架構的模型部署到各種端側裝置上,讓模型和這些裝置高度適配。
接下來,更重要的一點是,這個架構的模型要能夠在各種端側裝置上自主學習,不斷前進演化。
最後,這些模型與端側裝置結合成的智慧體要能夠自主協作,共同完成任務。
這其中的每個階段都不簡單:
在第一階段,新架構不止要具備低算力、部署到端側原生無失真的特點,還要具備可以媲美 Transformer 架構的效能,保證單個個體足夠聰明且可以自主學習。
在第二階段,「大腦和身體」的高度適配涉及感知層面和數據處理的不同模態,每種裝置有著不同的需求,這增加了模型和裝置適配的復雜性。
在第三階段,讓模型部署之後還可以學習就意味著要挑戰現有的訓練、推理完全分離的機制,讓模型參數在端側也可以調整,且調整足夠快、代價足夠小。這就涉及到對傳統反向傳播機制的挑戰,需要的創新非常底層。
在第四階段,主要挑戰是如何實作智慧體之間的有效協作。這個過程要求智慧體自主發現並形成完成任務的最佳方案,而不是依賴於人為設定或程式預設的方案。智慧體需要根據自己的智慧水平來決定協作的方式。
這些難點就決定了, RockAI 必須走一條不同於 OpenAI 的路線 ,挑戰一些傳統的已經成為「共識」的方法。
劉凡平提到,在前兩個階段,他們已經做出了一些成果,針對第三、四個階段也有了一些實驗和構想。

群體智慧的單元大模型 ——Yan 1.3
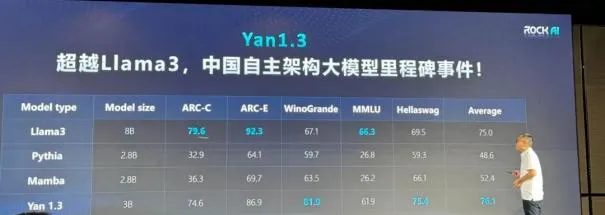
第一階段的標誌性進展是一個采用 Yan 架構(而非 Transformer 架構或其變體)的大模型。這個模型的 1.0 版本釋出於今年的 1 月份,為非 Attention 機制的通用自然語言大模型。據了解,該模型有相較於同等參數 Transformer 的 7 倍訓練效率、5 倍推理吞吐和 3 倍記憶能力。而且,這一模型 100% 支持私有化部署套用,不經裁剪和壓縮即可在主流消費級 CPU 等端側裝置上無失真執行。
經過半年多的攻關,這一模型剛剛迎來了最新版本 —— Yan 1.3 。

Yan 1.3 是一個 3B 參數的多模態模型,能夠處理文本、語音、視覺等多種輸入,並輸出文本和語音,實作了多模態的模擬人類互動。

盡管參數量較小,但 其效果已超越 Llama 3 8B 的模型 。而且,它所用的訓練語料比 Llama 3 要少,訓練、推理算力也比 Llama 3 低很多。這在眾多非 Transformer 架構的模型中是一個非常領先的成績,其訓練、推理的低成本也讓它比其他架構更加貼近工業化和商業化。
這些出色的效能得益於高效的架構設計和演算法創新。
在架構層面,RockAI 用一個名叫 MCSD(multi-channel slope and decay)的模組替換了 Transformer 中的 Attention 機制 ,同時保留 Attention 機制中 token 之間的關聯性。在資訊傳遞過程中,MCSD 強調了有效資訊的傳遞,確保只有最重要的資訊被傳遞給後續步驟,而且是以 O (n) 的復雜度往下傳,這樣可以提高整體效率。在驗證特征有效性和 token 之間的關聯性方面,MCSD 表現優秀。
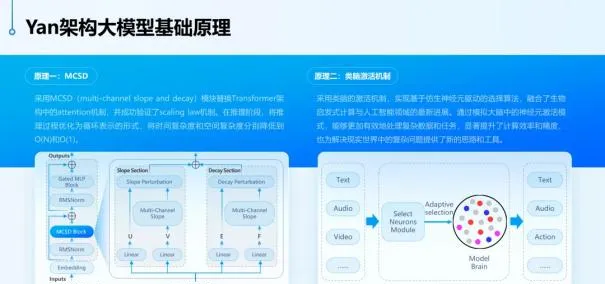
在演算法層面,RockAI 提出了一種類腦啟用機制。 這是一種分區啟用的機制,就像人開車和寫字會分別啟用腦部的視覺區域和閱讀區域一樣,Yan 1.3 會根據學習的型別和知識範圍來自適應調整部份神經元,而不是讓全量的參數參與訓練。推理時也是如此。具體有哪些神經元來參與運算是由仿生神經元驅動的演算法來決定的。

在今年的 GTC 大會上,Transformer 論文作者之一 Illia Polosukhin 提到,像 2+2 這樣的簡單問題可能會使用大模型的萬億參數資源。他認為自適應計算是接下來必須出現的事情之一,我們需要知道在特定問題上應該花費多少計算資源。RcokAI 的類腦啟用機制是自適應計算的一種實作思路。
這或許聽起來和 MoE 有點像。但劉凡平解釋說,類腦啟用機制和 MoE 有著本質的區別。MoE 是透過「專家」投票來決定任務分配,每個「專家」的網路結構都是固定的,其結果是可預測的。而類腦啟用機制沒有「專家」,也沒有「專家」投票的過程,取而代之的是神經元的選擇過程。其中的每個神經元都是有價值的,選擇的過程也是一個自學習的過程。
這種分區啟用機制在 MCSD 的基礎上進一步降低了 Yan 架構模型的訓練、推理計算復雜度和計算量。
「這也符合人類大腦的執行方式。人腦的功耗只有二十幾瓦,如果全部的 860 億個神經元每次都參與運算,大腦產生的生物電訊號肯定是不夠用的。」劉凡平說道。目前,他們的類腦啟用機制已經得到了腦科學團隊的理論支持和實際論證,也申請到了相關專利。
以端側裝置為載體,邁向群體智慧
在 Yan 1.3 的釋出現場,我們看到了該模型在 PC、手機、機器人、無人機等端側裝置的部署情況。鑒於 Yan 1.2 釋出時甚至能在樹莓派上執行,這樣的端側部署進展並不令我們感到意外。
那麽,為什麽一定要把模型部署在端側呢?雲端的模型不行嗎?鄒佳思提到,這是因為模型要跟機器本體做高度適配。以機器人為例,裝置的很多參數是難以與雲端大模型融合。端側大模型更容易讓機器人肢體協調、大小腦協同工作。
而且我們知道,這些端側智慧體的潛力才剛剛顯露。畢竟,以上創新的目標不只是讓模型能夠在端側跑起來(當前很多模型都能做到這一點),而是使其具備自主學習的能力,作為「群體智慧的單元大模型」持續前進演化。無論是 Yan 架構的「0 壓縮、0 裁剪」無失真部署,還是分區啟用的高效計算,都是服務於這一目標。這是 RockAI 和其他專註於端側 AI 的公司的一個本質區別。
「如果我們拿一個 10 歲的孩子和一個 30 歲的博士來比,那肯定 30 歲的博士知識面更廣。但是,我們不能說這個 10 歲的孩子在未來無法達到甚至超越這位博士的成就。因為如果這個 10 歲的孩子自我學習能力足夠高,他的未來成長速度可能比 30 歲的博士還要快。所以我們認為, 自主學習能力才是衡量一個模型智慧化程度的重要標誌。 」劉凡平說道。可以說,這種自主學習能力才是 RockAI 追求的「scaling law」。
為了實作這種自主學習能力,RockAI 的團隊提出了一種「 訓推同步 」機制,即讓模型可以在推理的同時,即時有效且持續性地進行知識更新和學習,最終建立自己獨有的知識體系。這種「訓推同步」的執行方式類似於人類在說話的同時還能傾聽並將其內化為自己的知識,對底層技術的要求非常高。
為此,RockAI 的團隊正在尋找反向傳播的更優解,方法也已經有了一些原型,並且在世界人工智慧大會上進行過展示。不過,他們的方法原型目前仍面臨一些挑戰,比如延遲。在後續 Yan 2.0 的釋出中,我們有望見到原型升級版的演示。
那麽,在每一台裝置都擁有了智慧後,它們之間要怎麽聯結、互動,從而湧現出群體智慧?對此,劉凡平已經有了一些初步構想。
首先,它們會組成一個去中心化的動態系統。在系統中,每台裝置都擁有自主學習和決策的能力,而不需要依賴一個中央智慧來控制全域。同時,它們之間又可以共享局部數據或經驗,並透過快速的通訊網路互相傳遞資訊,從而在需要時發起合作,並利用其他智慧體的知識和資源來提升任務完成的效率。
路線「小眾」,挑戰與機遇並存
縱觀國內 AI 領域,RockAI 走的路可以說非常「小眾」,因為裏面涉及到非常底層的創新。在矽谷,有不少人在做類似的底層研究,就連「神經網路之父」Hinton 也對反向傳播的一些限制表示過擔憂,特別是它與大腦的生物學機制不符。不過,大家目前都還沒有找到特別有效的方法,因此 這一方向還沒有出現明顯的技術代差 。對於 RockAI 這樣的國內企業來說,這既是挑戰,也是機遇。
對於群體智慧,劉凡平相信,這是一條邁向更廣泛的通用人工智慧的路線,因為它的理論基礎是非常堅實的,「 如果沒有群體智慧,就沒有人類社會的文明,更不會有科技的發展 」。
而且,劉凡平認為,群體智慧所能帶來的生產力變革比擁有超級智慧的單個大模型所能帶來的更全面、更多樣。隨著自主架構大模型的研發成功和多元化硬體生態的構建,他們相信自己正在逐漸接近這一目標。
我們也期待看到這家公司的後續進展。











