朋友們,我的書【PyTorch自動駕駛視覺感知演算法實戰】終於上架了,大家趕緊買買買,刷刷好評啥的:
TL;DR:
為了這本書:
做了一個七千多幀的連續幀數據集。可以用來訓練單目深度模型。疫情期間采集的,幾乎沒有動態物體,想用來玩SLAM,NeRF也是可以的。標註了目標檢測和語意分割兩個任務的真值。
整理了一個程式碼庫方便學習,實作了目標檢測,語意分割,無監督單目深度學習,多工學習,可微網路壓縮,模型匯出,模型量化,直至部署到LibTorch和TensorRT的C++程式碼。程式碼允許商用,除了TensorRT部份,沒有GPU也能跑,我用的是1080Ti,但6GB視訊記憶體應該也是夠的。
各種環境配置都錄了講解視訊,全是都是基於空白的Ubuntu系統從零配置的,通通錄屏。
為了讓人一眼秒懂,減少廢話和篇幅,畫了無數圖 。。。
我入行遇到的痛點
剛入行無人駕駛的時候找書看,發現市面上居然沒有一本像樣的書,基本都是內容特別詳細龐雜,過於基礎,稍微高階點的內容都沒有涉及,感覺註水嚴重。所以搞得濃縮了一點。
學習的時候沒有像樣的數據集,自動駕駛數據集都是巨大無比,非常不方便。這個領域急需一個方便學習和把玩,隨便一個筆記本都能跑得動,而且覆蓋的任務多,不需要寫多個介面的小規模資料庫。尤其是還要是連續幀的,能玩SLAM,NeRF之類的。所以就按照這個需求做了一個。
工作了一段時間發現很多日常使用的工具,比如Linux,Docker,顯卡驅動,cuda,Anaconda,CMake,VSCode之類的東西都要靠自己摸索,非常費時間。會用之後發現其實並沒什麽大不了的。所以把用的多的都寫了一下。
另外就是很多邊邊角角但是很重要的知識沒有人總結,比如batch size和learning rate的關系啦,L1正則化和L2正則化的區別啦,多工損失平衡之類的。反正能想到的邊邊角角都寫了。
最後一個很重要的方面就是模型部署,疫情期間工作的時候接過某德國大廠計畫,居然就是把一個模型壓縮和部署到某小眾硬體上,弄完之後得知這個計畫的價格我驚呆了,呵,原來我這麽值錢啊。。。後來從其他同行的經歷中也多多少少聽說了,光是部署模型居然就是一個非常大的市場,還特麽有創業公司。。。真的太離譜了朋友們,這個東西實在很簡單啊。所以專門把模型壓縮,模型量化到C++部署這一條龍都寫了一下,其實程式碼直接拿去商用估計比很多公司的都好了。。。
總之,我在這本書裏把這些痛點都解決了。平時我甚至還需要經常查自己的書,別說還挺方便的23333
內容
下面就分章節介紹一下:
- 摺積神經網路的理論基礎。 其實很多書一本書就相當於這一章。。。把神經網路的基礎知識全部介紹了一遍,結合公式和圖片高度濃縮的過一遍。
- 深度學習開發環境及常用工具庫。 顧名思義,就是Anaconda,Nvidia驅動,cuda,PyTorch之類的東西。像OpenCV和PyTorch的一些庫函式,直接一張cheatsheet表格解決問題,沒廢話。
- 神經網路的特征編碼器——主幹網路。 除了主幹網路的結構,還講了對比學習無監督預訓練,如何魔改TorchVision模型之類的事情。
- 目標檢測。 兩階段,一階段,基於Anchor的,Anchor-Free的,幾個有代表性的都講了講。
- 語意分割與例項分割。 語意分割還專門講了幾種常用的資訊融合方法,例項分割介紹了半監督例項分割模型BoxInst。最後還花了一小節介紹了MMDet的框架構成和用法,沒辦法,用的多,痛點要解決。
- 無監督單目深度模型。 很多學深度學習的同學可能對三維視覺不太了解,但搞無人駕駛,三維視覺還是要知道的。這一章等於是透過無監督單目深度模型,即學習了這個任務,又順便學了三維視覺。有程式碼,直接用我提供的數據集就能訓練出來。
- 多工和網路壓縮。 多工主要講了多工學習中損失平衡的重要性。網路壓縮我還自己實作了一個可微網路壓縮的方法,從NAS那邊抄過來的,效果居然非常好,也不知道有相關論文發表沒有,誰如果要魔改啊發論文啊啥的別忘了cite我啊!主要是讓大家認識到網路壓縮的威力。
- 匯出和部署神經網路模型。 這一章都是C++的東西,先是教了一下Docker,CMake,給VSCode配置環境,配置LibTorch和TensorRT啥的。部署的程式碼都有實作,Docker也提供了,照理照著一步步做不會出任何問題。LibTorch的CPU版本在任何裝置都能跑,TensorRT程式碼要GPU。
數據集
長這樣,隨便看看,程式碼裏名叫慕尼黑數據集,就在家附近經常散步的社群騎著自由車用從前公司離職的時候同事們送的GoPro錄的:
 慕尼黑數據集
https://www.zhihu.com/video/1731914250044592129
慕尼黑數據集
https://www.zhihu.com/video/1731914250044592129
2D檢測真值是用CenterNet2標註的,基本很精確了。語意分割是用MaskFormer標註後手動微調獲得的,這個沒辦法完美,現在可能有更厲害的網路了,哪位有興趣的可以幫我重新標一版。
圖多
其實寫書花的時間遠遠不如畫圖多,從視覺上說,我覺得我畫的圖還是比較好看的,可惜不是全彩。。。
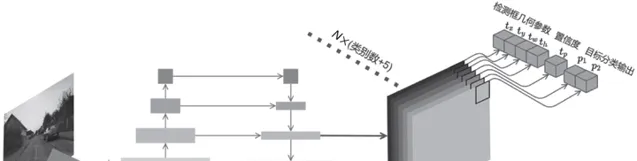
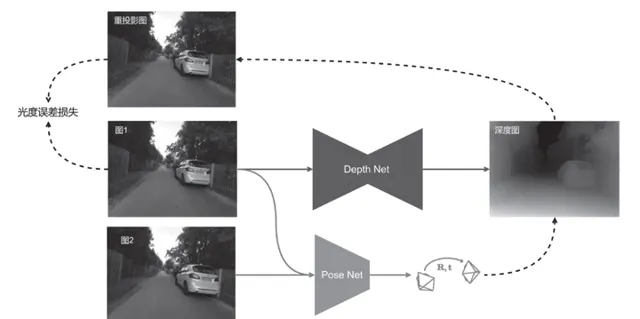
遺憾
所有深度學習的書籍肯定都有相同的遺憾:過時。寫的時候我就預料到,書裏的模型肯定會過時。所以盡量選擇了有代表性的,經典的模型。即便過時了,和sota的做法也不會有本質區別。同時大部份的篇幅都是和工具和基礎理論相關的內容,具體模型占的篇幅反而少,主打一個授之以漁的意思。
還有一個遺憾是BEV相關的內容沒有。不過也不算遺憾,因為報提綱的時候BEV還處於嬰兒期。。。即便是現在,也不太好寫,變化太快了,誰也不知道BEV的最終形態是怎麽樣的。不過最後為了彌補這個遺憾,錄了個BEV感知的視訊。
錯誤應該也是不少的,大家都知道,我喜歡大放厥詞。。。知乎上可以改,這寫書可不行。。。所以盡量都找到論文佐證,不亂說話,但最終肯定還是會有錯誤的。大家看到錯誤了可以私信我,到時候出第二版可以改。
總之,買就完事了!










