1 前言
BEV感知是近幾年自動駕駛領域發展最快的方向,甚至可以不用加之一。自從2021年Tesla在AI Day上展示了這一技術以來,BEV迅速占領了感知領域的各個方向,從3D目標檢測到語意分割,從視覺感知到多傳感器融合,等等。
在感知領域取得巨大成功之後,BEV技術也逐漸被套用到自動駕駛系統的其他模組,比如行為預測,軌跡規劃,語意地圖等等。同時,還有一種趨勢,就是用BEV把所有這些模組都串接起來,形成一個整體,這也就是當下最火熱的「端到端自動駕駛」的概念。
專欄之前的文章詳細介紹了視覺BEV感知的概念和代表性演算法,這些演算法主要是為了完成3D目標檢測的任務。視覺傳感器:BEV感知綜述
在此基礎上,本文進一步探討BEV如何套用到其它感知任務(比如目標跟蹤,語意分割,占據柵格等),以及其它自動駕駛任務(行為預測,軌跡規劃,語意地圖等),甚至是用來設計端到端的自動駕駛系統。此外,雖然本文介紹的這些擴充套件任務是以視覺輸入為主,但是這些任務對輸入並沒有限制,多傳感器融合的BEV方法同樣可以來完成這些任務。
那麽, 為什麽BEV可以做這麽多的任務呢,它核心的技術到底是什麽呢 ?
字面上理解,BEV是Bird's Eye View的縮寫,所以它只是一種檢視表示方法,或者說一種座標系。自動駕駛系統最終是需要在BEV座標下(或者說3D空間座標,這裏為了描述簡單我們不作區分),而傳統的視覺感知是在2D影像座標下進行的,這中間就有了gap。BEV技術出現之前,一般的做法都是先在2D影像上生成各種感知結果,然後再把結果轉換到BEV座標。 BEV技術最核心的思想就是直接在BEV空間中輸出結果,跳過了在2D影像上輸出結果的步驟,而2D影像上只做最基本的特征提取 。
為了直接在BEV空間進行操作,最直接的方法就是把影像特征從2D空間對映到3D空間,也就是常說的View Transform。這是BEV技術的核心步驟,可以透過Transformer或者深度估計來完成。當然,有些方法沒有顯式的做特征空間轉換,而是利用Transformer,直接從影像特征中預測3D空間中的感知結果。但是不管采用哪種方式,基於BEV的方法都沒有在2D影像上生成感知結果。
如果顯式生成了BEV特征圖,那麽這個特征圖就可以被用來完成很多的下遊任務,比如行為預測和軌跡規劃。這些自動駕駛的任務本來就是在BEV座標下設計的,因此可以很容易的與BEV特征圖銜接。同時,我們也可以設計不同型別的query(比如動態目標,地圖元素,自車軌跡等),把多個任務整合到一個大的神經網路中,形成一個「端到端」的系統。
為了更好的理解BEV技術,下面我們來探討兩個常見的問題。
1. BEV和Transformer有什麽聯系呢?
嚴格來講,BEV本身和Transformer沒有任何關系。但是,BEV技術的View Transform可以透過Transformer來實作,比如BEVFormer中的方式。當然,View Transform也可以透過深度估計來實作,比如BEVDet中的方式。此外,Transformer作為主幹網路結構,可以更好的提取影像特征,這也是目前大模型中常用的方式。當然,傳統的網路結構,比如ResNet,EfficientNet等都可以作為主幹網路來提取影像特征。為了進行多工擴充套件,可以設計對應不同任務的query,當然也可以利用傳統的多頭網路結構,每個頭對應一個任務。
所以,理論上來說,一個BEV網路可以完全不包含任何與Transformer相關的結構。但是,在目前主流的網路設計中,尤其是「端到端大模型」中,使用Transformer結構可以增強網路的學習能力,在海量數據的加持下可以獲得更好的效能。因此,BEV+Transformer這種組合逐漸被固定下來。但是,我們要知道,他們兩個本質上是兩個概念。
2. BEV技術是不是已經過時了,端到端才是未來?
BEV和端到端其實也是兩個概念。用傳統的2D影像感知網路,理論上我們也可以把它與下遊的預測和規控任務連線起來,只不過設計和實作的難度都比較大。用BEV的框架來實作端到端會更加合適一些,因為BEV把感知任務也放到BEV空間裏來做,跟下遊的預測和規控任務統一起來了。同時,預測和規控模組也可以很容易的利用BEV座標下的影像資訊。此外,在BEV座標下,影像與雷達點雲的融合也變得更加容易,為「多模態端到端大模型」奠定了基礎。
所以,BEV只是實作「端到端」的一種方式。從目前的趨勢來看,BEV+Transformer是實作端到端的一種比較現實的方式,僅此而已。也許,在將來的某一天,我們用一個超級神經網路,直接把原始的傳感器數據轉換為車輛的控制訊號。從不同座標系下的傳感器輸入到自車座標系下控制訊號,座標系的轉換都隱藏在神經網路中,已經無從分辨了。到那個時候,也許我們就不會再更多談論BEV的概念了。
2 感知任務擴充套件
專欄之前的文章著重介紹了視覺BEV感知網路的設計思路,終端任務基本都是常見的3D目標檢測。至於其他感知任務,只在「多工網路」部份進行了簡單的介紹。如上文所述,BEV感知可以很自然的擴充套件到其他感知任務,比如目標跟蹤、語意分割、占據柵格等。
2.1 占據柵格(Occupancy Grid)
占據柵格這個任務其實就是一個3D空間的語意分割,與其他分割任務相比並沒有本質區別,只不過分割的物件不同。影像語意分割的物件是像素,點雲語意分割的物件是點,而占據柵格的分割物件是3D空間的柵格(3D grid cell或者voxel)。其實,在雷射點雲的分割中,如果把點雲量化為voxel再做處理,這個跟占據柵格任務是非常相似的。既然是語意分割任務,那麽評價的指標也可以類似的用IoU和mIoU來衡量。
作為一個分割任務,占據柵格的優勢當然也是處理「非標準」的障礙物,或者說通用障礙物。在3D目標檢測任務中,目標都是以「框」(bounding box)的形式存在,但是很多障礙物是不能簡單用一個框來表示的。比如,一段彎道兩側的綠化帶,一輛轉彎的兩段式公交車,如果用框來表示就會有很大誤差。甚至,在自動泊車的場景下,一輛小轎車如果用矩形框來表示都會帶來不可接受的誤差。因此,雖然占據柵格這種稠密的表示需要很大的計算量,在某些場景下還確實是必須要有的。
2.1.1 真值生成
占據柵格本質是一個語意分割任務,其輸出是每個voxel的占據狀態和語意標簽。假設感知場景包含C個語意類別,那麽每個voxel的的標簽就是一個C+1維的向量,其中0表示「非占據」,1到C表示占據的語意類別。為了訓練神經網路預測這種輸出,我們需要構建同樣格式的真值,也就是稠密的帶有語意標簽的voxel。
這並不是一個簡單的任務,因此本文專門用一小節來介紹占據柵格真值的生成方法。與目標檢測中的物體框相比,語意分割任務的真值標註要困難很多。采用人工標註的話,耗費的時間基本要多一個數量級。與影像和點雲相比,占據柵格的標註就更加費時,因為它比影像多一個維度,比點雲稠密度高很多。因此,占據柵格的真值生成要麽是全自動的,要麽是高度自動化的(只需要少量的人工檢查)。
OpenOccupancy
在該論文中,作者提出了一種半自動的方法,從雷射點雲的語意標註出發,構建稠密的占據柵格標註。實驗在nuScenes資料庫上進行,利用了Panoptic nuScenes提供的雷射點雲語意標註。
該方法稱作Augmenting And Purifying (AAP),其中Augmenting是自動化的部份,而Purifying是人工校驗的部份。首先,多幀雷射點雲根據標註的3D物體框,可以區分為靜態點和動態點。靜態點透過自車運動資訊進行多幀累積,動態點則在物體框自身座標系下進行多幀累積(再放回到靜態場景中),最後形成一個相對稠密的多幀點雲。然後,用該點雲生成占據柵格,文中稱之為「初始標簽」。此時的柵格還是有很多空洞區域的,但是可以用來訓練一個基準的占據柵格預測網路。之後這個基準的網路就可以用來預測稠密的占據柵格,文中稱之為「偽標簽」。初始標簽和偽標簽合並到一起,就可以得到完整的占據柵格標簽(兩者沖突的時候,以初始標簽為準)。以上就是Augmenting的流程。最後,人工標註員再利用標註工具檢查Augmenting生成的標簽,查缺補漏,也就是Purifying。在nuScenes數據集上,3.4萬個關鍵幀的檢查花費了大約4000個小時的人工,平均每小時可以檢查8.5幀,還是非常高效的。
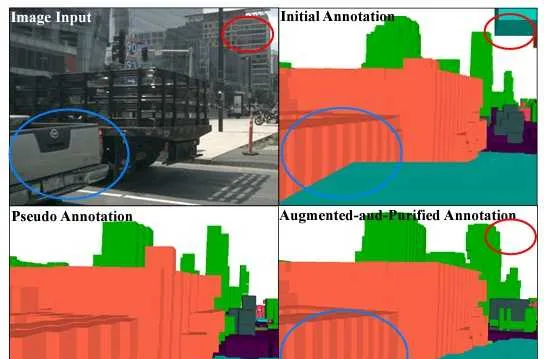
SurroundOcc
與OpenOccupancy類似,該方法在第一步中同樣采用動靜分離的處理方式來合並多幀點雲,並得到初始的占據柵格。自然的,這個柵格並不是完全稠密,而是帶有很多空洞的。接下來,作者提出利用Poisson Surface Reconstruction來對初始占據柵格進行補全。補全之後再利用最近鄰的策略來給柵格分配語意標簽。整個過程沒有人工參與,可以全自動進行。但是,全自動生成的占據柵格肯定還會有錯誤,如果有人工修正的話可以進一步提高標註的品質。
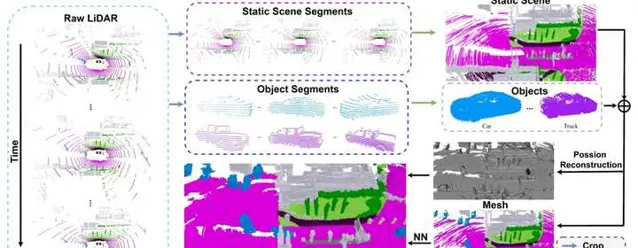
Occ3D
該方法同樣采用動靜分離的策略合並多幀點雲,也采用了Surface Reconstruction和K近鄰的策略來補全稀疏的占據網格及其語意標簽。這些步驟與OpenOccupancy和SurroundOcc是類似的,不過Occ3D額外關註了遮擋和不確定區域的問題。
上述自動標註的流程都是基於雷射點雲,雷射射線有反射的柵格(也就是點雲的位置)會被標記為"occupied",其余柵格標記為"free"。但是雷射射線是稀疏的,無法覆蓋所有的區域。尤其是在遠距離的區域,射線之間的空白空間會很大。此外,障礙物後面的區域,雷射射線也覆蓋不到。所以,"free"的柵格有兩種情況,一種是真的free,另一種其實是不確定的。Occ3D透過ray-casting的方法,進一步區分出不確定區域的柵格,把它們標記為"unobserved"。
另外,雷射雷達和網路攝影機的FOV是不一致的。雷射能看到的,網路攝影機不一定能看到,反之亦然。因此,Occ3D中同樣也定義了基於相機的"occupied"、"free"和"unobserved"。在訓練和測試的過程中,需要綜合考慮來自兩種傳感器的標簽狀態。這裏有很多細節的選擇,需要根據實驗結果來具體分析。
為了進一步提高標註品質,Occ3D還采用2D影像上的語意分割標註來對3D占據柵格進行細化。

流程總結
透過對以上三個典型方法的分析,我們可以總結出一個一般性的基於雷射點雲的占據柵格真值生成流程。
- 雷射點雲根據目標級的標註資訊,劃分為靜態背景和動態目標。
- 靜態場景和動態目標分別進行多幀累積,生成更加稠密的點雲。
- 多幀累積後靜態場景和動態目標合並到一起,並進行網格化。
- 利用預訓練模型或者mesh reconstruction之類的技術對voxel進行補全,然後對遮擋區域進行處理。最後再利用2D影像或者人工操作對voxel標註進行檢查和修正。
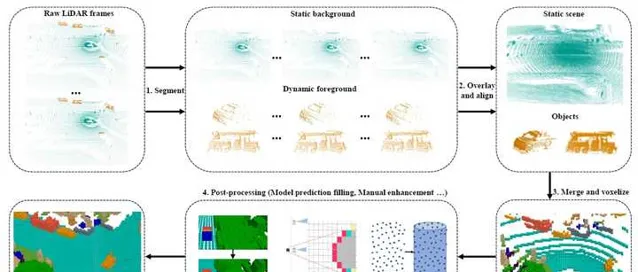
用雷射點雲生成的3D占據柵格真值來提供監督訊號,是最直接的一種訓練方法。此外,還有些方法提出用網路預測的占據柵格來生成2D的深度圖,用深度的真值來做監督學習,比如 SimpleOccupancy 和 UniOcc 。當然,深度的真值一般也是透過雷射點雲獲取的。
數據采集車一般都配備雷射雷達,但是這樣得到的數據非常有限。更多的數據其實來自於量產車,但是量產車上不一定配備雷射雷達,即使有的話一般規格也比數據采集車低很多。如何能在沒有雷射點雲或者雷射點雲品質較低的情況下訓練占據柵格網路呢?這也是一個非常有意思,也非常現實的問題。一個直接的想法就是利用NeRF,因為NeRF本身的目的就是得到一個連續的場景函式,以此為基礎就可以生成占據柵格。但是,周視的相機數量太少(一般是6個),互相之間的視野重疊也很少,無法提供足夠的3D幾何資訊。所以,這種方式一般只用來構建一個額外的自監督的損失函式,用來輔助網路訓練,並不能完全代替雷射點雲。
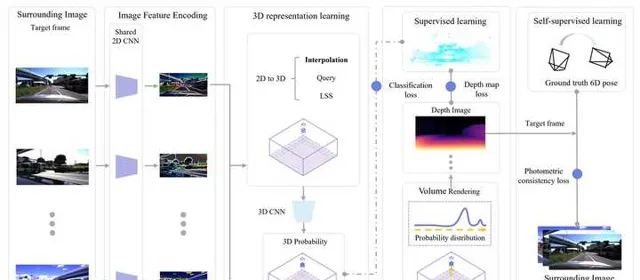
為了能夠完全擺脫對雷射點雲的依賴, OccNeRF 中提出充分利用時序資訊,也就是說用NeRF生成連續多幀影像,並且利用多幀影像的光度一致性(photometric consistency)來提供主要的監督學習訊號。不過,與用雷射點雲監督的方法相比,OccNeRF的mIoU指標明顯較低。在實際套用中,還是應該考慮如何更加有效的重構3D場景,得到4D標註(這裏可以利用多輛車的數據),以及如何更好的利用多種監督訊號。
關於4D標註,感興趣的朋友可以參考 隋唐:面向BEV感知的4D標註方案 | 萬字實錄
2.1.2 典型演算法分析
占據柵格雖然是近期提出的概念,但其實它也不算是一個新的任務。前面介紹了,它可以被看做是3D柵格上的語意分割任務,是2D占據柵格的一種擴充套件形式。另外,早期的語意場景補全(Semantic Scene Completion,SCC)也跟占據柵格任務的目的非常相似。
SCC任務從稀疏的語意資訊出發,恢復稠密的3D場景資訊,其最終的輸出也就是一個3D的語意柵格。所以,一些用來做SCC任務的方法,比如 MonoScene , VoxFormer ,一樣也可以用來做占據柵格的預測。從影像預測3D占據柵格的核心是2D到3D的視角轉換,以及3D特征的提取。MonoScene和VoxFormer在2D到3D轉換方面做的相對比較粗糙,後續也也就無法很好的提取3D特征,因此它們在占據柵格預測上的效能並不是很好。
視覺BEV感知興起以後,影像特征從2D到3D的轉換有很大的改善,典型的方法包括LSS/BEVDet中的push方法(或者叫forward方法),以及BEVFormer中的pull方法(或者叫backward方法)。兩種方法的細節可以參考專欄關於視覺BEV感知的介紹文章。
理論上說,BEV的方法都可以用來做占據柵格,我們只需要在BEV特征提取之後加一個3D占據柵格預測的任務頭。BEV特征雖然沒有顯式的高度維度,但是高度方向的資訊都已經被編碼到了特征中,是可以恢復出3D空間結構的。比如, MiLO 方法使用了BEVDet4D的結構, OccTransformer 方法使用了BEVFormer的結構,而 FB-OCC 方法采用了FB-BEV的結構(綜合了forward和backward兩種視角變換方式)。此外, TPVFormer 利用俯檢視(也就是BEV)/前檢視/側檢視三種不同的檢視來提取特征,試圖用這種方法來盡可能的保留3D特征。這些方法在得到3D Voxel特征以後,通常都會利用一個3D-UNet或者3D-ResNet結構來進一步增強3D特征的提取。這是3D占據柵格網路與一般的BEV網路最大的區別。

除了3D特征提取以外,目前準確率比較好的占據柵格方法都采用了很多的trick。比如,采用更大的預訓練主幹網路來提取影像特征,疊加更多幀以增強時序特征提取,甚至把多個完全不同的占據柵格網路ensemble到一起。這些trick都會增加很多的計算量,而車載系統需要考慮準確率和計算量的平衡,對這些trick的使用會比較謹慎。
如上所述,在占據柵格網路中,3D特征提取是重要的一環,同時也是計算量的瓶頸之一。為了降低這部份的計算量, FlashOcc 中提出一直在BEV檢視上做特征提取,這裏高度資訊是被編碼到特征通道裏了(也就是height-to-channel),直到最後需要預測3D占據柵格時,才利用channel-to-height的reshape操作生成3D網格特征。這種方式避免了非常昂貴的3D摺積計算,透過實驗可以看到準確率和計算量之間的tradeoff也是很不錯的。比如,在mIoU只降低0.6%的情況下,FPS可以從92.1提升到210.6。
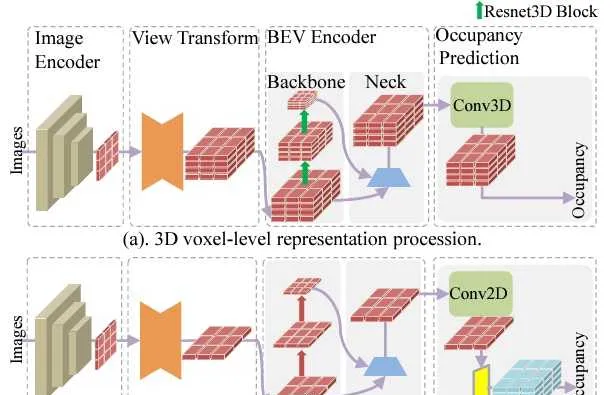
類似的, FastOcc 也是利用BEV特征的2D摺積代替Voxel特征上3D摺積,以降低計算量。但是在最後階段恢復3D特征的時候,沒有采用channel-to-height,而是將原始的2D影像特征轉換到3D Voxel特征,與unsqueezed的BEV特征合並,做一次3D摺積後,用於占據柵格的預測。這裏的3D Voxel特征相當於沒有經過處理,而是透過類似ResNet中的shortcut方式,直接與BEV特征合並。
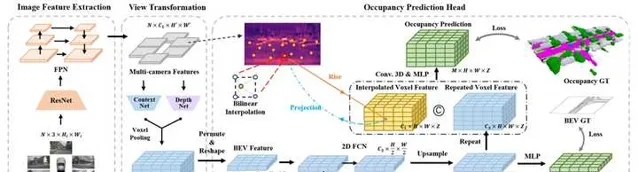
除了3D特征提取,占據柵格網路的另外一個計算量瓶頸在於網格的大小。為了滿足自動駕駛系統要求,網格大小一般在5到50厘米之間,分辨率越高,網格的尺寸也就越大,特征提取所花費的計算量也就越大。但是,在實際場景中,大部份的網格都是"非占據"的,這些區域並不需要很高的分辨率。換句話說,只有"占據"區域的網格需要較高的分辨率。在這種思路的指導下, OpenOccupancy 提出了一種coarse-to-fine的占據柵格預測方法。首先,任何占據柵格網格都可以被用來預測一個低分辨率的柵格。然後,這個柵格中被占據的格子單獨拿出來,在空間上進行分割,得到高分辨率的網格,並以此為基礎生成query。最後,這些高分辨率的query去和影像/點雲特征互動,生成高分辨率的占據柵格。"非占據"的柵格可以直接擴充套件為多高分辨率網格,因為這些柵格本身就是空的,沒有資訊量。采用類似思路包括PanoOcc和OctreeOcc。

還有一些方法提出采用多尺度的柵格表示,比如 SurroundOcc 和 Multi-Scale Occ 。但是多尺度的柵格對應的空間範圍是相同的。其實,在自動駕駛任務中,對網格分辨率的要求是跟距離相關的。遠距離區域可以采用低分辨率網格,而近距離區域需要高分辨率的網格。根據這個思路,我們也可以設計多組不同分辨率,對應不同距離區域的網格,從而降低整體的柵格預測計算量。
2.2 多目標跟蹤(MOT)
摺積神經網路很早就被用到了物體檢測領域。但是對於目標跟蹤來說,用傳統的摺積網路來實作還是比較困難的,其中主要的問題在於如何處理track的生命周期,以及如何處理detection和track之間的assignment關系。當Transformer被用於物體檢測後,我們發現利用query機制可以很好的處理上述問題。比如,在 TrackFormer 和 MOTR 中,query被劃分為detection和tracking兩部份。Detection query主要用來完成目標檢測任務,而track query和detection query合並後計算自註意力,完成assignment。更新後的query再與影像特征互動,確定新生成的track和需要刪除的track。專欄的另外一篇文章中詳細介紹了TrackFormer的原理,供大家參考。多傳感器融合:後融合(深度學習)
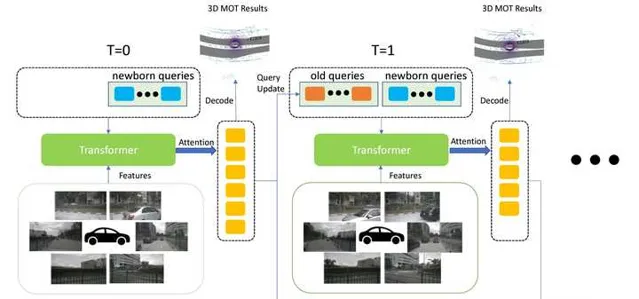
同樣的,query的機制也可以用來在BEV框架下實作多目標跟蹤。比如,在 MUTR3D 中,query分為newborn和old兩種,分別用來生成新的track和維護現有的track。當query的confidence低於一定閾值後,就會被設定為dead query,也就是被刪除了。此外,MUTR3D還維護了一個motion model,具體來說就是透過query和自車運動的資訊來預測被跟蹤目標的運動。這一步其實就是模擬了kalman濾波中的dynamic model。
3 地圖任務擴充套件
在2021年Tesla的AI Day上,BEV感知的概念第一次亮相。在那場釋出會上,當時Tesla AI部門的負責人Karpathy博士舉了兩個例子來證明BEV感知優於傳統2D影像感知,其中一個例子就是車道線檢測。具體內容可以參考我之前寫的一個回答 自動駕駛BEV感知有哪些讓人眼前一亮的新方法?
所以,車道線檢測其實是BEV感知誕生時就可以做的任務。除了車道線,BEV感知後來也被用來檢測更多的地圖元素,比如斑馬線,道路邊沿等,進而擴充套件到構建局部的語意地圖。接下來,我也會按照這個順序來介紹BEV對於地圖元素感知演算法。
3.1 車道線檢測
深度學習出現之前,影像中的車道線一般是透過其邊緣的灰度/顏色變化來檢測,然後利用霍夫變換/RANSAC之類的方法擬合車道線方程式,最後再用濾波的方法來輸出平滑的車道線。這種方法需要的計算量較小,也不需要大量標註數據,但是包含大量人工設計的邏輯,可延伸性比較差,也無法適應復雜的路面狀況。
深度學習出現之後,最直接的方法就是用影像例項分割來檢測車道線,比如 LaneNet 。此外,還有一些其他的方案,比如把車道線參數化,然後用神經網路來估計這些參數,或者設定一些anchor lines,然後用神經網路預測真實車道線與這些anchor lines的offset。
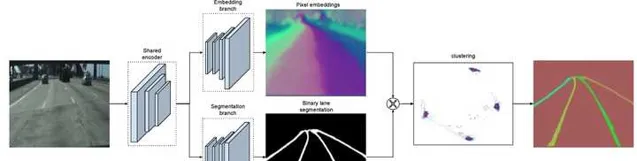
2D影像中檢測到的車道線,還需要投影到車輛座標系(一般就是BEV座標),才能提供給下遊的模組使用。這種2D檢測+BEV投影的方式會帶來較大的空間誤差。在遠距離區域,這個誤差尤其嚴重。車道線在影像上偏一個像素,在BEV座標下可能就會產生幾米的偏差。BEV感知把影像特征對映到BEV空間,直接在BEV空間檢測車道線,就可以充分利用神經網路的學習能力,來減小空間位置上的偏差。
與之前介紹的占據柵格和多目標跟蹤任務一樣,對於BEV車道線檢測任務,BEV感知框架中的影像特征提取、檢視轉換和BEV特征提取模組都是可以和其它任務共用的。也就是說,像LSS/BEVDet/BEVFormer這些框架都也可以拿來做BEV車道線檢測,我們只需要設計一個專門的車道線檢測任務head即可。在這裏,最核心的東西就是定義車道線的表示方法。與影像中的車道線檢測類似,我們也可以用例項分割mask,anchor lines或者參數化曲線等方法來表示車道線。下面我們來看一下兩個典型的方法。
PersFormer 方法提出用anchor lines來表示車道線,每條anchor line由多個預設的點組成。anchor lines同時在2D影像座標和3D世界座標系中定義,並且具有對應關系。影像特征對映到BEV後,可以直接預測anchor lines的offset,使之與真值標註盡可能匹配。此外,PersFormer還增加了一個額外的BEV車道線分割loss,用來輔助訓練。下圖是PersFormer的整體結構,其中backbone和Perspective Transformer都是BEV感知的標準模組,所以演算法的重點在於從BEV特征預測2D/3D車道線,以及損失函式的設計。

PersFormer的論文中還提出了一個大規模的車道線數據集, OpenLane 。該數據集基於Waymo Open Dataset來構建,包含了20萬幀影像和88萬條標註的車道線。此外,場景標簽和距離自車最近的目標(CIPO)也進行了標註。車道線的標註在2D影像上進行,標註內容包含車道線類別,trackID,以及組成車道線的2D點集。

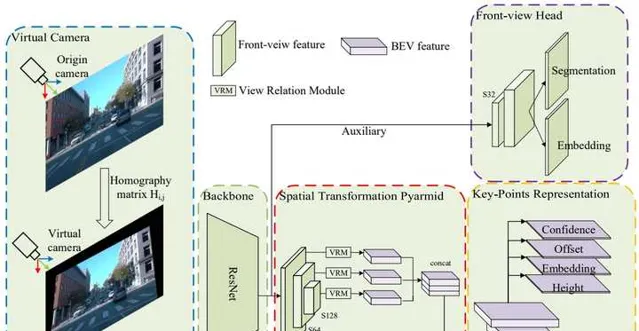
BEV-LaneDet 采用了網格結構來表示車道線。具體來說,自車前方的路面被劃分為0.5m大小的網格,BEV特征最終會預測4個網格,分別用來表示車道線的置信度、在網格內的位置偏移(只有側向),例項的embedding,以及網格內的平均高度。此外,BEV-LaneDet還采用了虛擬相機技術來降低相機內外參對結果的影響。訓練集中所有影像的內外參求平均值,作為基準。在訓練和推理階段,所有影像都利用這個基準的內外參進行homograph投影,保證視角的一致性。
3.2 局部地圖構建
曾經,自動駕駛系統非常的依賴高精度地圖。原因也很好理解,那就是感知能力不行。不知道大家有沒有類似的經驗,當你在能見度比較低而且彎道較多的情況開車時,導航地圖能讓你提前知道前方道路的彎曲程度,這對你提前判斷非常有幫助。自動駕駛系統也是一樣,當感知模組能力比較弱的時候,如果有一個高精度地圖可以準確的給出周圍的道路資訊(並且範圍遠超傳感器的感知距離),那麽感知模組就只需要關註動態障礙物的檢測,難度也就降低了很多。
但是,這種方式顯然擴充套件性和適應力都比較差。高精度地圖的建立是一個費時費力的過程,時刻保持地圖的鮮度也是一個基本不可能完成的任務。因此,當BEV範式大幅提升了感知模組的能力以後,利用感知模組線上構建高精度語意地圖,就變的越來越有吸重力了。同時,像nuScenes和Argoverse2這種大規模的資料庫,也都提供了高精度地圖,經過處理以後就可以作為線上地圖學習的真值。
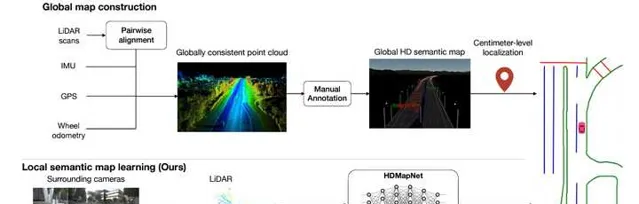
與BEV車道線檢測網路一樣,BEV地圖構建網路的重點也在於地圖的表示,以及如何用BEV特征來預測這種表示。其他模組,比如影像/點雲特征提取,影像特征視角轉換等,都可以用標準模組來實作。下面我們就來介紹一些典型的地圖表示和預測方法。
HDMapNet 在BEV特征的基礎上,預測得到三個網格型別的輸出,分別對應Semantic Segmenation,Instance Embedding和Direction Prediction。前兩部份跟基於例項分割的車道線檢測方法沒什麽區別,Direction Prediction則給出了每個網格中地面元素的朝向。在訓練過程中,真值也是按照這三部份的格式來生成的。而在推理過程中,三部份輸出合到一起,透過聚類得到各個地面元素的例項,並透過方向資訊的輔助將它們連成線條。文中的實驗是在nuScenes資料庫上做的,地面元素的類別只有三類:車道線,車道邊沿,斑馬線,分別可以用曲線或多邊形來表示。
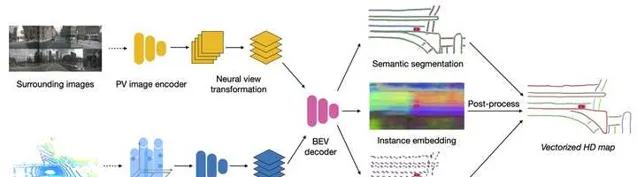
在HDMapNet中,神經網路只是給出了網格形式的輸出,向量形式的輸出是透過後處理來完成的。對於局部地圖構建來說,檢測地圖元素只是任務的一部份,更困難的任務是恢復這些元素之間的拓撲關系,而且這些操作盡量都要透過端到端的方式在網路中完成。
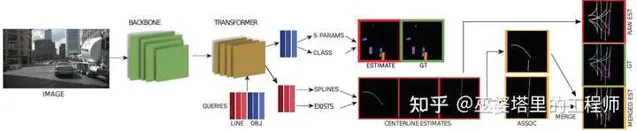
STSU 中提出用貝茲曲線來分段建模道路中心線,網路透過line query來輸出多條貝茲曲線,同時也學習一個分類器,用於判斷兩條曲線是否是連線的。訓練階段,透過標註數據生成多段貝茲曲線,以及它們的鄰接矩陣。在推理階段,網路輸出多條曲線,每條曲線都有附加的特征,可以透過訓練階段得到分類器來確定兩條曲線是否應該連線。這樣,最後就可以得到一組曲線來表示路網的結構。
VectorMapNet 采用polyline來表示地圖元素,每個polyline就是一組有序的點集。這種表示方式避免了HDMapNet中稠密的網格表示,同時也比STSU中使用的貝茲曲線描述能力更強。該方法也采用query-based的方式,用N個element query來預測polyline。這與DETR中用N個object query預測目標框的原理是一樣。每個element query包含k個key points,每個point用d維的參數向量表示。透過Transformer解碼器得到key points之後,再用一個polyline generator模組對他們的位置進行細化,並連線成polyline。
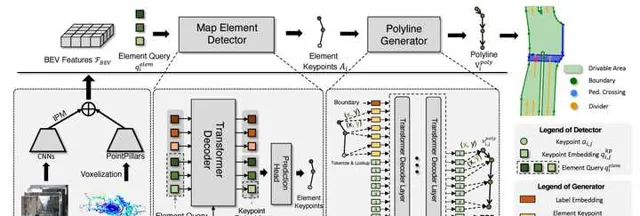
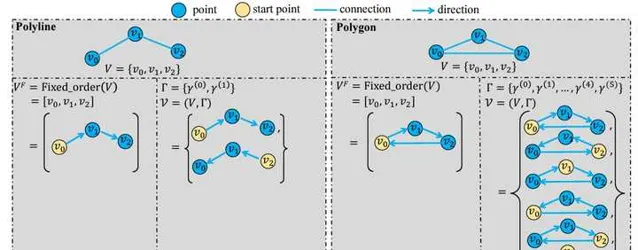
MapTR 采用polygon和polyline來分別表示閉合和開放的地面元素形狀,比如斑馬線是閉合形狀,而車道線是開放形狀。polyline和polygon本質上很類似,都可以形式化為有序的點集,如果polyline的起點和終點相同,那其實就是一個polygon。這種表示方式與VectorMapNet類似,但是MapTR考慮了點集的等價性。具體來說,如果polyline代表一個沒有方向的車道線(比如區分正向和對向的車道線),那麽點集的順序並不重要。如下圖左側所示,polyline交換起點和終點,可以形成兩種等價形式,它們都可以作為GT來跟網路的預測進行匹配。如下圖右側所示,對於polygon來說,除了順序以外,起點和終點也不重要,也就是說每一個點都可以是起點,因此它的等價形式更多。
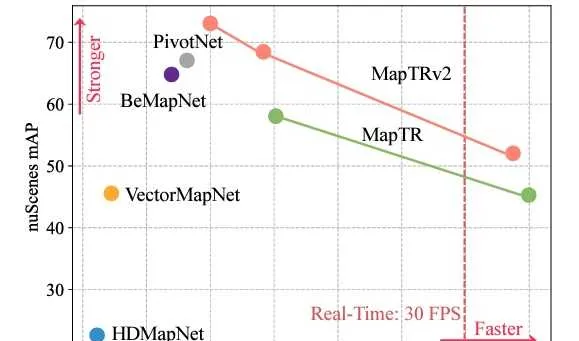
MapTR在訓練中充分考慮這些等價性,並利用與DETR類似的框架並列的來預測多個polygon/polyline。因此,除了執行速度更快以外,MapTR預測地面元素的準確率也比VectorMapNet和HDMapNet更高。

在MapTR的基礎上, MapTRv2 做了兩個擴充套件。一個是考慮車道中心線的方向資訊,另一個是最佳化記憶體占用和降低計算量。
利用BEV感知構建線上地圖的目的是降低對於離線高精度地圖的依賴。但是,換個角度來想,如果在某個場景下,高精度地圖是可用的,那麽離線和線上的地圖結合起來會不會更好呢?
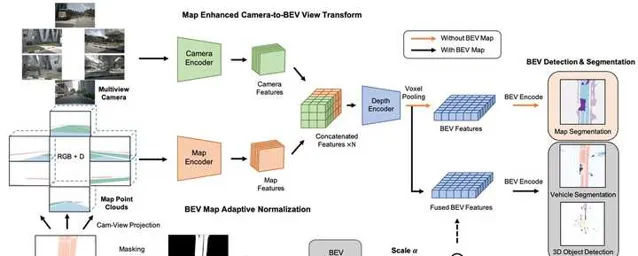
BEVMap 中提出將離線高精度地圖從向量形式(polygon)轉換為網格形式,網格中編碼了地圖元素的類別以及空間資訊。這些地圖網格透過相機的內外參轉換到影像檢視,與原始的影像輸入按照同樣的方式進行特征提取。之後,影像特征和地圖特征合並後,再轉換到BEV檢視,用於下遊的地圖分割、目標檢測等任務。實驗結果表明,增加了地圖先驗資訊後,3D目標檢測的準確率得到了提升,但不是非常顯著。在nuScenes的3D檢測任務上,NDS提升了1到2個百分點。
在實際的套用中,如果有正確的高精度地圖,那肯定還是以這個地圖為主。說白了,感知地圖也是以離線高精度地圖為真值來訓練的。如果有真值,那還費力的做預測幹嗎呢?所以,更為現實的場景是,有高精度地圖,但是地圖可能比較老,不能完全對應當前的路況,或者說有些地圖元素是缺失的,因為之前建圖時沒有考慮。在這種情況下,我們拿到的是一張沒有那麽「精確」的高精度地圖,這時地圖和感知融合就可以發揮作用了。
MapEX 對高精度地圖的真值進行修改,模擬了地圖元素缺失、位置不準以及地圖過期三個場景,並設計了一個網路結構來融合來自感知和地圖的資訊。具體來說,高精度地圖中的元素被形式化為polyline和點集,並以此為基礎構建一組map query。這些query是non-learnable的,它們與傳統的learnable的query一起,用來跟BEV特征互動(交叉註意力),預測地圖元素。實驗結果表明,即使高精度地圖是不準確的,還是可以對預測結果提供非常大的幫助。但是,我們也要註意,這種不準確的高精度地圖畢竟只是透過模擬得到的,實驗的結論還需要審慎看待。舉例來說,當刪除掉地圖中的人行道和車道線,只保留道路邊沿,網路對於道路邊沿預測的準確率幾乎是100%(因為網路用真值作為輸入),車道線的預測也有較大提升(因為車道線和道路邊沿相關性較大),而對於人行道的預測只有非常小的提升(人行道和道路邊沿相關性較小)。
4 預測和規劃任務擴充套件
如上所述,BEV感知的一個優勢就是可以跟下遊任務(比如預測和規劃)更好的連線,因為這些任務本身就是在BEV空間中進行的。那麽很自然的,BEV的演算法框架也可以用來去做預測和規劃任務。更進一步,BEV框架統一了感知,地圖,預測和規劃,那基本就是一個端到端的系統了。這其實又回到了文章開頭討論的BEV和端到端的關系問題。本質上,端到端是實作自動駕駛的一種解決方案,或者說它是一個任務,而BEV只是實作端到端任務的一種思路。它們之間是隸屬的關系,而不是互斥的關系。回到正題,下面我們就來介紹如何用BEV來實作預測和規劃任務,進而擴充套件到端到端的任務。
作為視覺BEV感知的開山之作之一, LSS (Lift, Splat, Shoot)提出了用深度估計來實作2D/3D轉換的方案。除此之外,可能很多人都忽略了,LSS中的shoot其實就是要在BEV特征之後做一個motion planning的任務。這裏的planning被形式化為預測軌跡的置信度。具體來說,作者從真實駕駛數據中生成1000條自車軌跡作為樣版,每條軌跡由多個采樣點組成。BEV網路會生成一個cost map,簡單說就是一個網格數據,網格裏的值就是cost。每條軌跡上的點可以去相應的網格中獲取cost值,所有點的cost相加後就得到了一條軌跡的cost。最後,cost最小的軌跡被選擇用來規劃自車的運動。
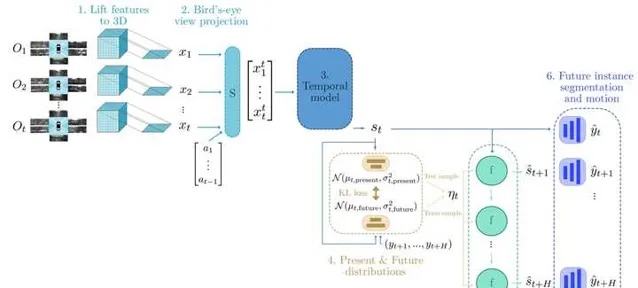
FIERY 提出了一種預測其他目標未來軌跡的方法。其中影像特征的視角變換,多幀數據的時序累積,都跟一般的視覺BEV感知方法沒有太大區別。這裏比較特別的是透過ConvGRU,以一種recursive的方法來預測未來每一個時刻目標的位置。這個任務被形式化為BEV檢視下的例項分割,也就是說網路會預測未來每一個時刻的例項分割結果,並以網格的形式輸出。未來多幀的例項分割結果組合起來後,我們就可以得到目標的軌跡。如果想要向量化的表示,還需要一定的後處理步驟。
最後,我們來看一下 UniAD 這個端到端自動駕駛演算法的開創性工作。簡單來說,UniAD利用query(也就是transformer機制)把自動駕駛任務中的多個子模組串成一個大的網路,而網路學習的最終目的是planning。這些子模組包括目標跟蹤(TrackFormer),地圖元素(MapFormer),目標運動預測(MotionFormer),障礙物占據柵格預測(OccFormer)。每個模組的輸出都用不同形式的query來建模,更新後query則作為key和value供下遊子模組使用。整個網路的輸入還是多張影像,BEV的標準操作(影像特征提取,視角變換,BEV特征提取)為後續模組提供BEV特征。從這個結構我們也可以看出,BEV只是實作端到端的一種方式。理論上說,我們也可以跳過BEV步驟,直接把2D影像特征送給下遊模組,就像DETR中做的那樣。
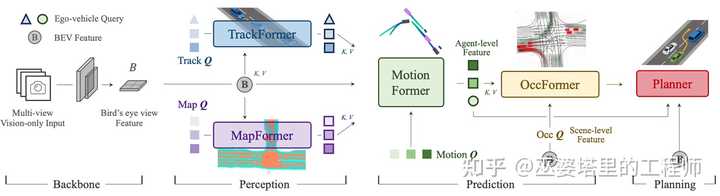
UniAD中的細節遠不是幾句話可以解釋清楚的,本文的目的只是介紹BEV的擴充套件任務,所以這裏只是簡單描述一下它的框架。端到端方案是當前自動駕駛研究中的熱點問題,專欄後續會結束文章來進行詳細的探討。
5 總結
總結一下,BEV方法的基本流程是傳感器特征提取(影像或者點雲),2D到3D視角轉換(對於影像數據),BEV特征提取,以及各種任務頭。用BEV框架來做各種擴充套件任務,其實就是在BEV特征後面附加各種任務頭。目前,由於不同任務的輸出格式由很大差異,目前任務頭的設計比較傾向於采用基於query的方式。這種方式非常靈活,可以適應不同的輸出格式,同時也可以用來串聯多個不同的任務。







