一、業務背景
前陣子跟業界同行聚會的時候聊到,我們在行銷的時候,是分人群投放物料的,但我們物料的排序演算法模型卻是同一個,這樣肯定是有gap的。按人群生命周期管理,例如新手區,我們的目標是成單,而進階區我們的目標是成大單,排序的產品應該不同。如果按人群訓練多個模型,管理起來又非常麻煩。這個問題其實就是千人(千人群)千模的新範式經典問題。目前用meta-learning解決很方便。
我們再來看一個場景:
假設我們是一個電商店鋪老板,因為自認為產品價效比好,但沒流量不好賣,買了廣告流量包成了廣告主。一段時間下來,發現廣告帳戶的錢根本花不出去,照樣競爭不過那些本來就很好賣的商家。雖然他們產品不好,但還是搶到了流量。
對平台來說,這是一個很有挑戰的廣告流量分配的問題。一方面,買廣告流量的商品一般不是熱銷商品,他們互動數據少;但平台的排序演算法傾向於那些互動數據多的。導致新廣告根本沒失真耗。這個也可以看做是冷啟動問題。其實廣泛來說,即使都有互動數,不是冷啟動商品,也存在互動不一樣的情況。因此也是千人千模問題。一方面,我們需要在頂端流量分發的時候用bandit演算法,去給一定流量比例來探索新爆品;但更核心的是,我們需要千AD(廣告主)千模,讓小廣告主排序演算法跟大廣告主的不一樣,達到公平競爭。
這些問題本文提出的方法都能給你解決。
還有一類問題是百度最近發表的。他們2014年就開始做了。現線上上還跑著meta-learning的model。他們用meta learning解決了一個與上面兩個場景解耦的問題。因此可以把他們結合起來使用效果更好。百度最近在CIKM2021發表的文章中解決的問題是廣告線上學習問題。1)高階資訊的特征交叉可能產生數萬億個特征,這對於線上學習範例來說是稀疏的;2)數據分布的快速變化給準確學習帶來了挑戰,因為模型必須對新數據進行快速適應。他們用meta-learning的方法來解決老數據、新數據之間有gap的問題。
感興趣可以看參考文獻的第四篇。
二、meta-learning深入淺出
從finetune到元學習
這兩個概念是容易混淆的。我這裏把他們兩個放在一起好好比較一下。
如果是搞CV出身的,我們對finetune的感受是很深的。因為一個高維CNN網路,在
小樣本數據集上很難收斂。這個時候需要拿一個在大數據集上訓練好的model參數,這些參數可以提取到圖片各樣式的豐富特征,然後針對目前的小樣本,微調一下參數即可。微調的方式可以固定第0層-n-1層layer參數,只微調最後一層都可以。
但這個方法有一個問題,我們訓練的時候是在小樣本上微調的,我們線上跑的時候呢,是另一個小樣本。既然都是小樣本,他們的分布是不穩定的,因為不是完全數據集嘛。沒有豐富的樣本。那麽這樣微調的網路,在新的小樣本數據集上就不一定有效了。
解決這個問題就需要元學習了。這樣入手元學習的方式應該比較絲滑吧。
我們在以上面的流程為例,假設原始model的參數是A,我們copy一份為B,把他拿過來在小樣本數據集1上finetune,得到參數B1,然後,用這個B1的參數在小樣本數據集2上求loss和梯度w,用這個w來更新原始model參數A為A1,這樣,新學的A1,相當於是B1在新樣本上的訊號。這樣就是活學活用了。比finetune又更多了一步。
嚴格的演算法說明見下:

演算法的解說如下:
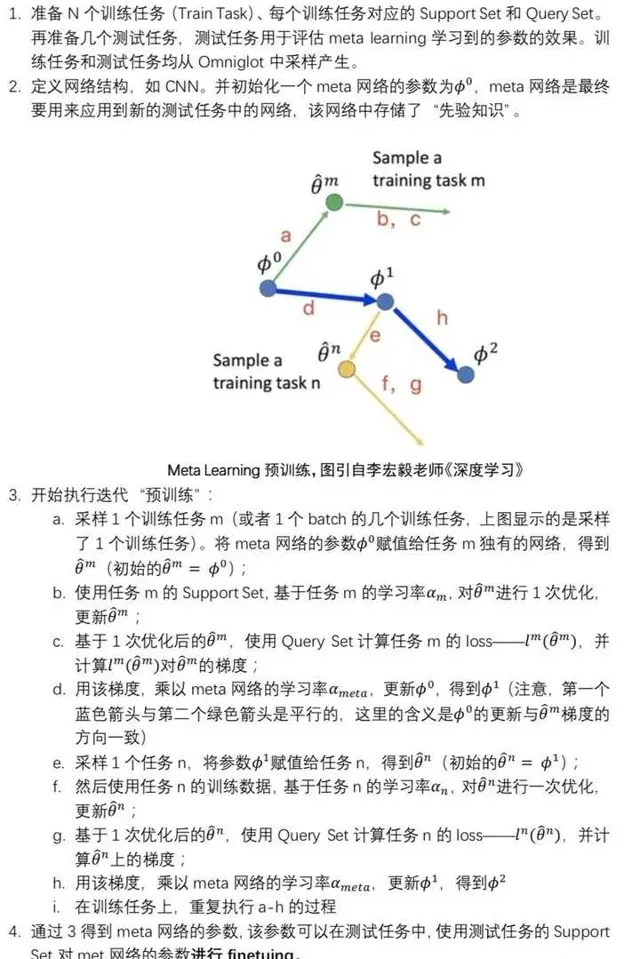
他們兩個的區別見下:
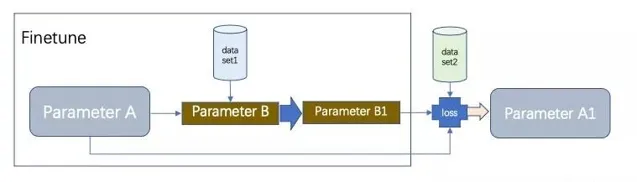
整體是一個meta-learning的過程,前半段是finetune的過程。 參數A和參數B都是共用一個Model,模型的所有的Layers結構都是一樣的。參數B一開始是復制的參數A,然後在dataset1上finetune 得到參數B1。根據學到的這個model參數B1,在新數據集2上,會計算得到新的loss。然後按照這個loss去更新參數A的值為A1。這就是整個元學習的過程。
三、千人千模廣告演算法新範式
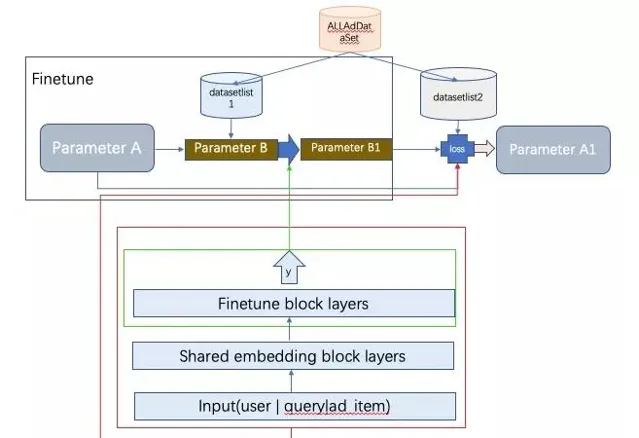
千人千模的整個pipeline架構圖如上。廣告主會在不同的Adgroup上根據行銷目的圈定不同的物料。我們按Adgroup建立數據集。整個數據集由每個Adgroup的單獨數據集組合一起而成AllAdDataset。然後,將每個Adgroup的數據集拆分成support set 和query set。所有support set組成datasetlist1,所有query set 組成 datasetlist2。每個Adgroup的數據可以看做是一個任務。接下來仔細講千人千模的訓練過程。 訓練:

訓練的時候,隨機抽多個任務,在每個任務上finetune訓練,對應下圖中的local update。然後訓練好的參數在queryset上計算loss,將計算出來的loss求和更新全域model參數。 更新完後,又重新復制參數A的值到參數B,開始新一輪叠代。 這樣的方式保證了finetune的時候單個任務對總模型底盤不動,因而收斂具有穩定性,同時多個任務自由個人化發揮自己的finetune blocklayers的參數。達到千人千模的效果。 部署: 訓練好的底盤共享block層部署一份即可,個人化的finetue block layers需要個人化部署。然後即時排序的時候拼接模型打分。初創型公司工程能力弱,可能需要部署千個model了。這個也是一個落地的難點。 今天的分享就到這裏。如果你覺得有意思,請點贊、在看、分享到朋友圈。不過分吧?
有觸感的解說元宇宙狙擊GNN打敗deepmind的Graphormer內核情景分析
Transformers4Rec 總結
參考文獻
[1] Personalized Adaptive Meta Learning for Cold-start User Preference Prediction AAAI2021
[2] Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings sigir 19
[3] Preference-Adaptive Meta-Learning for Cold-Start Recommendation IJCAI2021
[4] Efficient Learning to Learn a Robust CTR Model for Web-scale Online Sponsored Search Advertising 百度CIKM2021










