元學習 (Meta Learning)或者叫做 「學會學習」 (Learning to learn),它是要「學會如何學習」,即利用以往的知識經驗來指導新任務的學習,具有學會學習的能力。
元學習的概念、主要方法以及模型等內容,在 【百面深度學習】 這本書的第7章給了我們較為詳細的講解,有興趣的同學可進行閱讀。
下面人郵君和大家一起來了解一下。
由於元學習可幫助模型在少量樣本下快速學習,從元學習的使用角度看,人們也稱之為 少次學習 (Few-Shot Learning)。
更具體地,如果訓練樣本數為 1,則稱為一次學習(One-Shot Learning);訓練樣本數為 K,稱為 K 次學習;更極端地,訓練樣本數為 0,稱為零次學習(Zero-Shot Learning)。另外,多工學習(Multitask Learning)和遷移學習(Transfer Learning)在理論層面上都能歸結到元學習的大家庭中。
當前的深度學習大部份情況下只能從頭開始訓練。使用Finetune來學習新任務,效果往往不好,而Meta Learning 就是研究如何讓神經元兩個很好的利用以往的知識,使得能根據新任務的調整自己。

瑞士Dalle Molle人工智慧研究所的聯合主任Jürgen Schmidhuber在1987年畢業論文【Evolutionary principles in selfreferential learning. (On learning how to learn: The meta-meta-... hook.)】中最早提出了元學習的概念。在 1992 和 1993 兩年裏又借助迴圈神經網路進一步發展元學習方法。
元學習適合哪些學習場景?
在人工智慧系統的背景下,元學習可以簡單地定義為 獲取知識多樣性 (knowledge versatility) 的能力 。作為人類,我們能夠以最少的資訊同時快速完成多個任務;例如人類在有了世界的概念之後,看一張圖片就能學會辨識一種物體,而不需要向神經網路一樣一切都得從頭訓練;又例如在學會了騎自由車之後,可以基本在很短時間裏無障礙地學會騎電動車。
目前的 AI 系統擅長掌握單一技能,例如 Go , Jeopardy 甚至直升機特技飛行。但是,當你要求 AI 系統做各種簡單但又略有不同的問題時,它會很困難。相比之下,人類可以智慧地行動和適應各種新的情況。
元學習要解決的就是這樣的問題 : 設計出擁有獲取知識多樣效能力的機器學習模型,它可以在基於過去的經驗與知識下,透過少量的訓練樣本快速學會新概念和技能。
例如完成在非貓影像上訓練的分類器可以在看到一些貓圖片之後判斷給定影像是否包含貓幫遊戲機器人能夠快速掌握新遊戲
使迷你機器人在測試期間在上坡路面上完成所需的任務,即使它僅在平坦的表面環境中訓練
與多工學習以及遷移學習看似相同其實不盡相同的元學習?
元學習雖然從適應新任務的角度看,像是多工學習;從利用過去資訊的角度看,又像遷移學習。不過相對比二者還是有自己的特殊性。
相較於遷移學習元學習模型的泛化不依賴於數據量。而遷移學習微調階段還是需要大量的數據去餵模型的,不然會很影響最終效果。而元學習的邏輯是在新的任務上只用很少量的樣本就可以完成學習,看一眼就可以學會。從這個角度看,遷移學習可以理解為元學習的一種效率較低的實作方式。
對比多工學習元學習實作了無限制任務級別的泛化。因為元學習基於大量的同類任務 ( 如影像分類任務 ) 去學習到一個模型,這個模型可以有效泛化到所有影像分類任務上。
而多工學習是基於多個不同的任務同時進行損失函式最佳化,它的學習範圍只限定在這幾個不同的任務裏,並不具學習的特性。
meta-learning與有監督學習強化學習具體有哪些差別?
我們把 有監督學習 和 強化學習 稱為 從經驗中學習 (Learning from Experiences) , 下面簡稱 LFE ; 而把元學習稱為 學會學習 (Learning to Learn) , 下面簡稱 LTL 。兩者的區別如下。
LFE的訓練集面向一個任務,由大量的訓練經驗構成,每條訓練經驗即為有監督學習的(樣本,標簽)對,或者強化學習的回合(episode) 而LTL的訓練集是一個任務集合,其中的每個任務都各內建有自己的訓練經驗。
LFE的預測函式可寫成
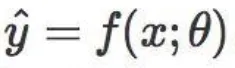
其中 \theta 是給定任務的模型參數;而LTL的預測函式可寫成
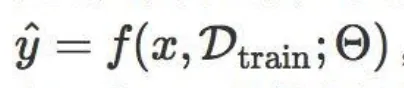
其中 \Theta 代表元參數,它不依賴於某個任務, D_{train} 是單個任務的全部訓練數據,它與一個測試樣本 x 共同作為 f 的輸入。
LFE的目標函式是給定某個任務下最小化訓練集 D_{train} 上的損失函式,即

而LTL的目標函式考慮所有訓練任務 t\in\ T_{train} ,最小化它們在各自測試集 D_{test}^{t} 上的損失函式之和,即
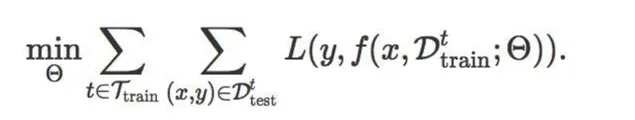
LFE的評價指標是在給定任務的測試集 D_{test} 上的預測準確率,即

而LTL的評價指標是在測試任務集 T_{test} 的每個任務 t 上,利用它的小樣本訓練集 D_{train}^{t} , 在測試集 D_{test} 上做預測,然後計算所有任務的預測準確率之和,即
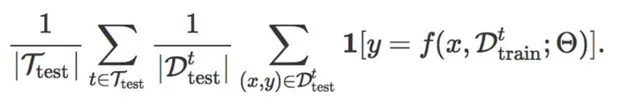
LFE是基層面的學習,學習的是樣本特征(或數據點)與標簽之間呈現的相關關系,最終轉化為學習一個帶參函式的形式;而LTL是在基層面之上,元層面的學習,學習的是多個相似任務之間存在的共性。不同任務都有一個與自己適配的最優函式,因此LTL是在整個函式空間上做學習,要學習出這些最優函式遵循的共同內容。
LFE的泛化目標是從訓練樣本或已知樣本出發,推廣到測試樣本或新樣本;而LTL的泛化目標是從多個不同但相關的任務入手,推廣到一個個新任務。LTL的泛化可以指導LFE的泛化,提升LFE在面對小樣本任務時的泛化效率。
LFE只關註當前給定的任務,與其他任務沒關系;而LTL的表現不僅與當前任務的訓練樣本相關,還同時受到其他相關任務數據的影響,原則上提升其他任務的相關性與數據量可以提升模型在當前任務上的表現。
————
更多關於元學習的內容,例如元學習的 主要方法、數據準備、模型 等,請見 【百面深度學習】 。
【百面深度學習】 由Hulu的近30位演算法研究員和演算法工程師共同編寫完成,專門針對 深度學習領域 ,全面收錄 135道真實演算法面試題 ,直擊面試要點,是【百面機器學習:演算法工程師帶你去面試】的延伸。

【百面深度學習】仍然采用 知識點問答 的形式來組織內容,每個問題都給出了 難度級 和 相關知識點 ,以督促讀者進行自我檢查和主動思考。書中每個章節精心篩選了對應領域的不同方面、不同層次上的問題,相互搭配,展示深度學習的「百面」精彩,讓不同讀者都能找到合適的內容。
元學習已經被大家研究了幾十年,可我們對他的探索依舊方興未已,各種神奇的想法層出不窮,但是真正的殺手級演算法還未出現,未來元學習也將有更多的可能。










