【目錄】
從開天辟地到天下一統
別看副標題取得氣勢磅礴,但其實圖形加速卡第一次擁有GPU這一試圖與CPU平分秋色的名字,是在1999年。也就是說享此殊榮的GeForce 256,其實還得叫我一聲哥?把座標變換、燈光照明、三角形設定裁剪和一個每秒能處理一千萬個多邊形的渲染引擎整合到一個芯片上[1],是它最大的賣點。雖然這些功能現在看來由GPU負責天經地義,但是在當時,卻是相當大的突破。

對 大量數據執行相同操作(SIMD) ,是平行計算的最愛,也是GPU得以分家立業並不斷從CPU挖墻腳的萬惡之源。而GeForce 256只是這萬裏長征夢最開始的地方,但其大量數據具體執行什麽操作是內建的(固定管線),這不還是特定演算法的加速器而已麽,怎配得上處理器三個字?
所以兩年後,GeForce 3擁有了頂點著色器和可配置的片元管線,進入了DirectX8的時代;而第二年也就是2002年,ATI(後被AMD收購,此時應該是ATI YES?)釋出了Radeon9700,其支持24位元可編程的片元著色器,直接擁抱DirectX9;輝達在2003年也釋出了支持32位元可編程片元的GeForce FX,雖然初始型號有點拉跨[2]。
在這個「上古混沌」時期,GPU走在一條 不斷提高可編程性 的康莊大道上,而終於在2006年隨著基於Tesla架構構建的第八代GeForce推出,迎來了一股小高潮。我們也迎來了本文的主角——Tesla架構。

在上古時期,頂點計算單元因座標變換的需要,有著低延遲高精度數學運算的設計(能力越大責任越大,這也是為什麽其在上古時期承擔著更為復雜的任務,並最早實作可編程性的原因);而片元計算單元因紋理過濾的特點,則有著高延遲低精度的設計。[3]
術業有專攻,因不同的需求,有多種獨立計算單元似乎理所當然。但隨著GPU在可編程性上一路狂奔,兩種計算單元在功能上有了越來越多的重合,就像前端工程師和後端工程師互相卷成全棧工程師,老板要考慮開掉一個一樣自然(奇怪的比喻還有很多,大家權當笑談), 頂點和片元兩種計算單元終於走到了分久必合的時候 。
當然合並的理由不止如此。通常情況下,要處理的片元比要處理的頂點多,因此頂點計算單元和片元計算單元數量比通常是1:3。然而同樣是因為GPU可編程性越來越大,兩者的最佳數量比因不同的程式差異巨大,很難提前確定。(特別是DX10推出的坑爹幾何著色器,誰知道程式設計師們會寫些什麽?)
工作負載越來越難以平衡,處理大三角形,頂點太閑;處理小三角形,片元太閑。以前業務功能單一,三個前端配一個後端,大家都能996,現在業務需求和模式變動頻繁,難免有人要摸魚。資本家把心一橫:「招全棧工程師!」
全是「全棧工程師」的架構設計還有很多好處,現在看是只能處理頂點和片元,以後沒準還能幹點其他的,最好是啥都能幹?以後的章節會陸陸續續提到。但現在,先讓我們來仔細看看,這個距今十幾年但仍魅力無限的Tesla架構。
剖開麻雀的身體
與現在動輒上萬個核的3090相比,Tesla架構寒酸得讓人心疼。但麻雀雖小五臟俱全,非常適合剛接觸GPU架構的我們學習(直接看最新顯卡的架構圖,在看清楚前眼睛已經瞎了)。
而隨著我們在之後的文章中一步步沿著顯卡的演化路徑前進到當下,我們會驚奇地發現, Tesla架構所奠定的基礎設施框架,以及其所蘊含的設計思想歷久彌新,從未過時 。
好,閑話少說,讓我們掏出手術刀,開始解剖:
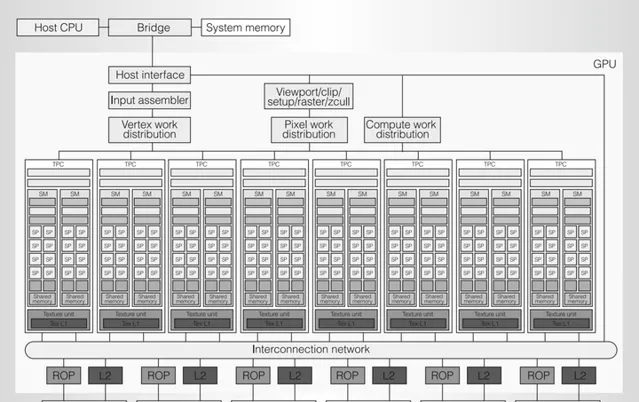
在細致認識這只「麻雀」的每一個器官之前,我們先來簡單劃分一下,有個整體的印象:
偉大的勞動人民
接下來讓我們逐一認識一下這些勞動人民:
從外包公司的角度去理解GPU,整個流程就逐漸明晰了起來。而TPC裏密密麻麻的格子間中,到底有著什麽不為人知的秘密?各類著色器紛繁復雜的指令,是如何在其間高效且有序完成的,請看下一章,Tesla架構(二)之血汗工廠篇。
如果您覺得本篇文章對你有點幫助的話,可以點個贊再走哦~別只是放到我的最愛裏吃灰呀~
參考
- Geforce 256
- GeForce FX
- Tesla架構白皮書











