Lechner, M., Hasani, R., Amini, A. et al. Neural circuit policies enabling auditable autonomy. Nat Mach Intell 2, 642–652 (2020). https:// doi.org/10.1038/s42256- 020-00237-3
pdf: https:// publik.tuwien.ac.at/fil es/publik_292280.pdf
code: https:// github.com/mlecp6l/ker as-ncp
文章概括
文章作者致力于构建一种脑启发的人工智能代理能够通过相机的输入来完成自动驾驶。现在端到端的机器学习并没有充分的准确性以及可解释性,这也就带来了对端到端算法的安全性的考虑。
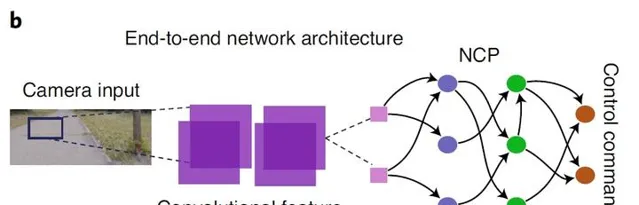
作者团队惊奇的发现像 Caenorhabditis elegans 等少细胞动物,可以通过近乎最佳的神经系统结构来完成执行运动、控制运动以及导航等行为。作者提出了 Neural circuit policies (NCP)通过将卷积提取到的32个特征通过253个突触与19个神经元相连接,并将提取到的特征转化为智能体的决策。
自动驾驶任务
文中理想的自动驾驶需要满足以下几个条件:
- 学习到观察到的驾驶场景和它们相应的最佳转向指令(智能体的特定任务)之间真正的因果结构
- 在现实环境中可以得到与虚拟环境中相同的效果
- 对于车道保持任务,智能体可以关注在道路的horizon
端到端的自动驾驶
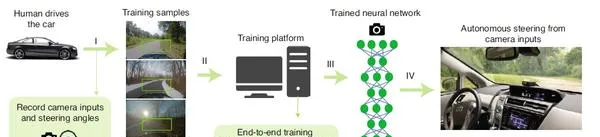
端到端的自动驾驶任务中没有关注 temporal 特性,并过滤掉了真实情况下噪声的干扰。在短时的阳光的干扰下,基于视觉的自动驾驶是不可靠的。
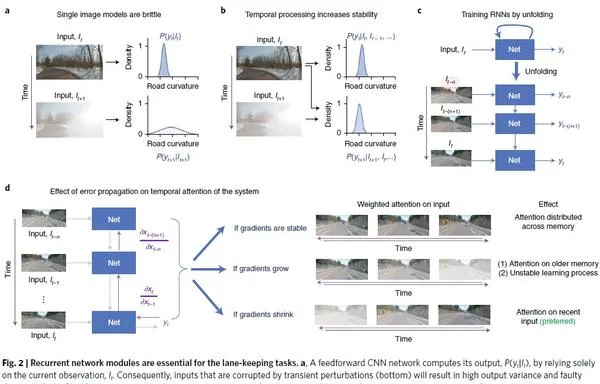
基于 RNN 训练的端到端的自动驾驶,会训练出更可靠的智能体(Fig2.a -> Fig2.b)。然而,人在驾驶的过程中不会回忆前几秒的道路的影像,这也是和基于LSTM 的RNN 相违背的。LSTM 会建立当前时刻与前几秒时刻的 long-term dependents,这与任务与图像之间的关系并不相符。
The development of a single, task-specific algorithm that universally satisfies the representation-learning challenges described above has been a central goal of artificial intelligence。Neural Circuit Policies (神经回路策略)
作者希望能够在 the neural computations 中汲取灵感,并建立了 NCPs。
线虫的神经机制
多种生物的神经回路,包括线虫的神经回路都是由四层网络拓扑结构组成的。线虫将从传感器得到的输入,传递给中间神经元以及 command 神经元,并生成决策。最后决策会控制肌肉的运动。线虫的神经网络结构较为简单,线虫神经网络的探究曾经登上了Nature。
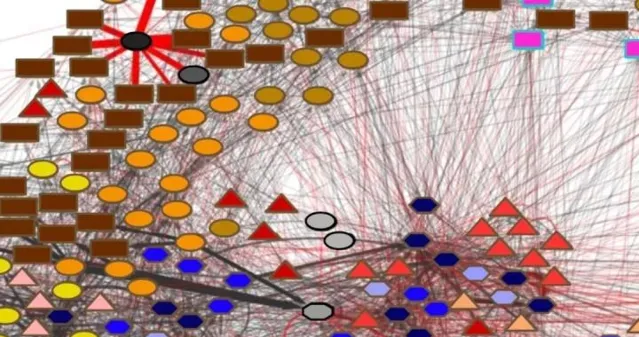
NCPs 的基本神经元模型
Many neural circuits within the nematode's nervous system are constructed by a distinct four-layer hierarchical network topology.
NCPs的神经元模型如下图所示:
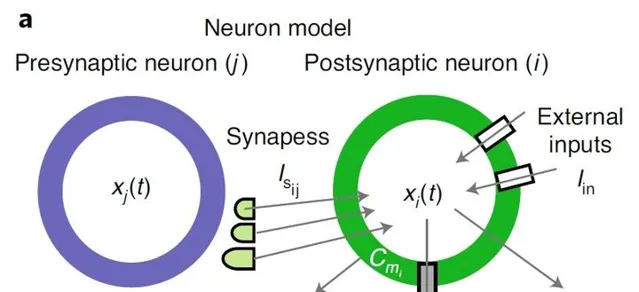
神经元模型的计算可以表示为continuous-time ordinary differential equations (ODEs) 连续时间常微分方程:
\dot{x}_{i}=-\left(\frac{1}{\tau_{i}}+\frac{w_{i j}}{C_{\mathrm{m}_{i}}} \sigma_{i}\left(x_{j}\right)\right) x_{i}+\left(\frac{x_{\text {leak }_{i}}}{\tau_{i}}+\frac{w_{i j}}{C_{\mathrm{m}_{i}}} \sigma_{i}\left(x_{j}\right) E_{i j}\right)
LTC neural model 与生物神经网络中的 Leaky integrate-and-fire model 膜电位的计算类似。但是脉冲神经网络的输出是离散的二值脉冲,LTC 神经元模型是连续的时域输出。NCPs的核心是一种非线性时变突触传递机制,与深度学习相比,这种机制提高了它们在建模时间序列时的表达能力。
NCPs 的网络结构
文中的网络结构遵循了四条规则:
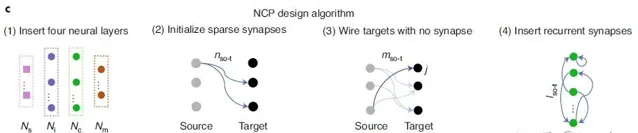
- 网络中共有四种神经元,包括:感觉神经元、中间神经元、指令神经元以及运动神经元。四种神经元模型的分配方式如图所示。
- 在任意两层神经元中间,突触行程所需要的极性(兴奋或者是抑制)以及目标神经元的选择都是满足二项分布的。
- 任意没有突触的目标神经元,与前一层的神经元建立突触,前一层神经元的选择记忆突触的极性都是满足二项分布的。
- 对于 command 神经元,层之间建立突触,目标神经元以及突触极性的选择满足二项分布。
NCPs 网络的训练
-
训练数据:真实的驾驶中的观测值以及决策值
> A large-scale selection of labelled training data were collected by recording the observations and actions of a human driver (see Methods for more details). -
训练方式:semi-implicit ODE
> Given a designed NCP network, we apply a semi-implicit ODE solver to obtain a numerically accurate and stable solution of the system.
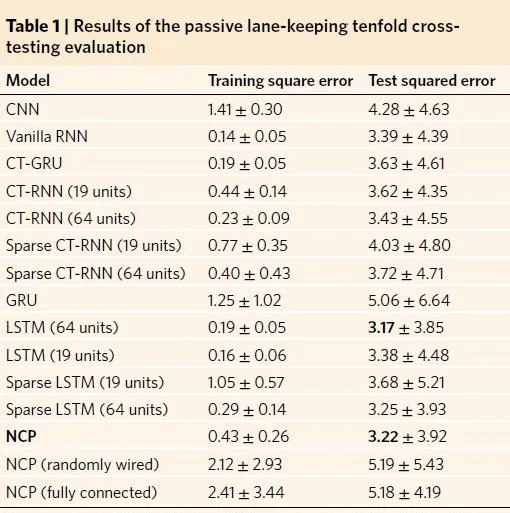
训练结果与其他模型进行了对比,其中在对比的过程中卷积部分是固定的。对标其他的RNN网络,NCP 网络在测试数据集以及训练数据集中的差距较小。