某种程度来说,其实是一样的,都是SMP(对称多处理器,Symmetric MultiProcessing),对于操作系统来说,每个核心都是作为单独的CPU对待的。所以在某个地方省事了,就必须在另外一个地方费劲。
不同的核心运行多个线程,总有需要交换数据的时候,根源为不同的核心需要访问同一个内存地址的数据——而核心Core0要访问这个地址的数据时,可能已经被核心Core2加载到缓存中并进行了修改。虽然理论上可以让Core2把缓存数据同步到内存后,Core0再从内存读取数据,但内存访问的速度比CPU速度慢很多,一般是直接访问Core2的缓存。
因此,不管是单个CPU多核心,还是多个单核心CPU,或者多个多核心CPU,都必须有这样的数据通道:
- 每个核心都可以访问全部内存
- 每个核心都可以访问其它核心的缓存
- 针对现代CPU集成了PCI-E控制器,大部分IO设备都可以使用DMA方式传输数据,可以把每个PCI-E控制器看待为若干个特殊的核心。
以Intel最新的至强可扩展第二代(Cascade Lake)架构为例,单个多核心CPU的架构是这样的[1]:
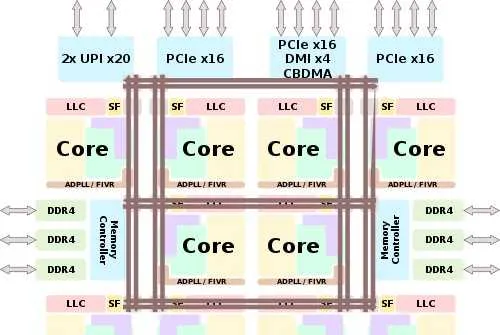
10个核心,以及PCI-E控制器、内存控制器通过网状总线互联。因为Cascade Lake支持多路CPU,因此还有一个UPI总线控制器。
现在基本没有单核心CPU了,两个多核心CPU互联是这样的[1]:
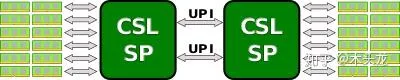
可以想象出来,第一个CPU的某个核心(假设是Core 0-1)要访问第二个CPU的另一个核心(假设是Core 1-3)的缓存,途径为:
Core 0-1->Mesh总线->UPI控制器->UPI总线->UPI控制器->Mesh总线->Core 1-3
Core 0-1访问第二个CPU的某个内存地址:
Core 0-1->Mesh总线->UPI控制器->UPI总线->UPI控制器->Mesh总线->内存控制器
很显然这个流程比单CPU内的多核心互访麻烦多了,延迟也会更高。此外,CPU需要增加UPI控制器;主板需要增加第二个CPU插槽以及必须的供电模块、散热模块;增加第二个CPU的内存插槽;两个插槽之间布线联通UPI控制器(单个UPI x20控制器需要使用80根线,2x UPI x20就是160根)。体会一下同样是CSL用的单路主板和双路主板的差异:



而且2x UPI x20的带宽也比Mesh互联的带宽低不少(Mesh互联的带宽不好算,也没找到资料,但Mesh互联的前身Ring总线互联的带宽是96GB/s,2x UPI x20带宽根据工作频率大概在76.8~83.2 GB/s,但和Ring相比,各种新闻稿都说Mesh平均延迟大幅降低,带宽大幅提升)。
所以,CPU核心是省事了些,但是CPU封装以及主板则是费劲多了,而且通常来说这个性能可能更差一些。当然,两个CPU会有其它方面的优势,例如整个平台的内存可以大一倍,多一倍的PCI-E通道可以连接更多的PCI-E设备,总核心数量相同的前提下,单个CPU功耗相近的时候每个核心可分配到的功耗更高,每个核心可以运行在更高的频率。
在生产方面,CPU只要一次设计好了,生产两个10核心和生产一个20核心的生产流程、原材料成本几乎是没有差别的,也许20核心因为使用更大的晶圆面积良品率低一点,但封装两个CPU也会带来更高的成本。而单路主板的设计、生产、成本都低的多,换句话说整个平台成本更低更具价格竞争力。
多说一句,AMD的8核锐龙、线程撕裂者、EPYC则是把这两种方式的优势组合起来,只生产4核心的CCX,每两个CCX组合成一个Zeppelin模块。然后线程撕裂者和EPYC则是多个Zeppelin模块在CPU的基板上通过Infinity Fabric总线互联。CCX的良率更高,配套主板的生产成本也低不少,只是封装的成本会有所提高。当然,这样多个Zeppelin模块在基板上互联和多个CPU互联相似,存在不同CCX上的核心互访延迟高带宽低的缺点,运行线程间需要频繁交换数据的多线程应用时效率比Intel的Core X/至强要低。
[1]:Cascade Lake - Microarchitectures - Intel - WikiChip











