从CNN到GCN的联系与区别——GCN从入门到精(fang)通(qi)
1 什么是离散卷积?CNN中卷积发挥什么作用?
了解GCN之前必须对离散卷积(或者说CNN中的卷积)有一个明确的认识:
如何通俗易懂地解释卷积?这个链接的内容已经讲得很清楚了, 离散卷积本质就是一种加权求和。
如图1所示,CNN中的卷积本质上就是利用一个共享参数的过滤器(kernel), 通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取 ,当然加权系数就是卷积核的权重系数。
那么卷积核的系数如何确定的呢?是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。这是一个关键点, 卷积核的参数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。

注:这里的卷积是指深度学习(CNN)中的卷积,与数学中定义的卷积运算严格意义上是有区别的。两者的区别与联系可以见我的另一个回答。
2 GCN中的Graph指什么?为什么要研究GCN?
CNN是Computer Vision里的大法宝,效果为什么好呢?原因在上面已经分析过了,可以很有效地提取空间特征。但是有一点需要注意: CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵 (如图2所示,也就是很多论文中所提到的Euclidean Structure)。
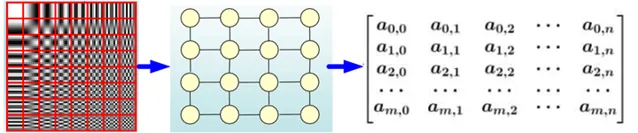
与之相对应,科学研究中还有很多Non Euclidean Structure的数据,如图3所示。社交网络、信息网络中有很多类似的结构。
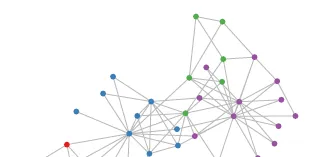
实际上,这样的网络结构(Non Euclidean Structure)就是图论中抽象意义上的拓扑图。
所以, Graph Convolutional Network中的Graph是指数学(图论)中的用顶点和边建立相应关系的拓扑图。
那么为什么要研究GCN?原因有三:
(1) CNN无法直接处理Non Euclidean Structure的数据。通俗理解就是在拓扑图中每个顶点的相邻顶点数目都可能不同,那么当然无法用一个同样尺寸的卷积核来进行卷积运算。
(2) 由于CNN无法处理Non Euclidean Structure的数据,又 希望在这样的数据结构(拓扑图)上有效地提取空间特征来进行机器学习 ,所以GCN成为了研究的重点。
(3) 读到这里大家可能会想,自己的研究问题中没有拓扑结构的网络,那是不是根本就不会用到GCN呢?其实不然, 广义上来讲任何数据在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想 (谱聚类(spectral clustering)原理总结)。 所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
3 提取拓扑图空间特征的两种方式
GCN的本质目的就是用来提取拓扑图的空间特征,那么实现这个目标只有graph convolution这一种途径吗?当然不是,在vertex domain(spatial domain)和spectral domain实现目标是两种最主流的方式。
3.1 空间维度
Vertex domain (spatial domain)是非常直观的一种方式。顾名思义:提取拓扑图上的空间特征,那么就把每个顶点相邻的neighbors找出来。这里面蕴含的科学问题有二:
a.按照什么条件去找中心vertex的neighbors,也就是如何确定receptive field?
b.确定receptive field,按照什么方式处理包含不同数目neighbors的特征?
根据a,b两个问题设计算法,就可以实现目标了。推荐阅读这篇文章Learning Convolutional Neural Networks for Graphs(图4是其中一张图片,可以看出大致的思路)。

这种方法主要的缺点如下:
c.每个顶点提取出来的neighbors不同,使得计算处理必须针对每个顶点
d.提取特征的效果可能没有卷积好
当然,对这个思路喜欢的读者可以继续搜索相关文献,学术的魅力在于百家争鸣嘛!
3.2 图谱维度
Spectral domain 就是GCN的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的Convolution,最后与深度学习结合提出了Graph Convolutional Network。
从上面的介绍可以看出,从vertex domain分析问题,需要逐节点(node-wise)的处理,而图结构是非欧式的连接关系,这在很多场景下会有明显的局限性。
而spectral domain是将问题转换在「频域」里分析,不再需要node-wise的处理,对于很多场景能带来意想不到的便利,也成为了GSP的基础。
关于Spectral graph theory的具体介绍,可以参下面的一些资料,简单的概括就是 借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质。
Spectral graph theory
小杰:谱图理论(spectral graph theory)
4 什么是拉普拉斯矩阵?为什么GCN要用拉普拉斯矩阵?
Graph Fourier Transformation及Graph Convolution的定义都用到图的拉普拉斯矩阵,那么首先来介绍一下拉普拉斯矩阵。
对于图 G=(V,E) ,其Laplacian矩阵的定义为 L=D-A ,其中 L 是Laplacian 矩阵, D 是顶点的度矩阵(对角矩阵),对角线上元素依次为各个顶点的度, A 是图的邻接矩阵。看图5的示例,就能很快知道Laplacian 矩阵的计算方法。

这里要说明的是: 常用的拉普拉斯矩阵实际有三种:
No.1 L=D-A 定义的Laplacian 矩阵更专业的名称叫 Combinatorial Laplacian
No.2 L^{sys}=D^{-1/2}LD^{-1/2} 定义的叫 Symmetric normalized Laplacian ,很多GCN的论文中应用的是这种拉普拉斯矩阵
No.3 L^{rw}=D^{-1}L 定义的叫 Random walk normalized Laplacian ,有读者的留言说看到了 Graph Convolution与Diffusion相似之处 ,当然从Random walk normalized Laplacian就能看出了两者确有相似之处( 其实两者只差一个相似矩阵的变换 ,可以参考Diffusion-Convolutional Neural Networks,以及下图)
不需要相关内容的读者可以略过此部分

其实维基本科对Laplacian matrix的定义上写得很清楚, 国内的一些介绍中只有第一种定义 。这让我在最初看文献的过程中感到一些的困惑,特意写下来,帮助大家避免再遇到类似的问题。
为什么GCN要用拉普拉斯矩阵?
拉普拉斯矩阵矩阵有很多良好的性质,这里写三点我感触到的和GCN有关之处:
(1)拉普拉斯矩阵是对称矩阵,可以进行特征分解(谱分解),这就和GCN的spectral domain对应上了
(2)拉普拉斯矩阵只在中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0
(3)通过拉普拉斯算子与拉普拉斯矩阵进行类比(详见第6节)
两者的关系可以参考我的另一个文章:
5 拉普拉斯矩阵的谱分解(特征分解)
GCN的核心基于拉普拉斯矩阵的谱分解,文献中对于这部分内容没有讲解太多,初学者可能会遇到不少误区,所以先了解一下特征分解。
矩阵的谱分解,特征分解,对角化都是同一个概念 (特征分解_百度百科)。
不是所有的矩阵都可以特征分解 ,其充要条件为n阶方阵存在n个线性无关的特征向量。
但是拉普拉斯矩阵是半正定对称矩阵 (半正定矩阵本身就是对称矩阵,半正定矩阵_百度百科,此处这样写为了和下面的性质对应,避免混淆),有如下三个性质:
由上可以知道拉普拉斯矩阵一定可以谱分解,且分解后有特殊的形式。
对于拉普拉斯矩阵其谱分解为:
L= U\left(\begin{matrix}\lambda_1 & \\&\ddots \\ &&\lambda_n \end{matrix}\right) U^{-1}
其中 U=(\vec{u_1},\vec{u_2},\cdots,\vec{u_n}) ,是 列向量 为单位特征向量的矩阵, 也就说 \vec{u_l} 是列向量 。
\left(\begin{matrix}\lambda_1 & \\&\ddots \\ &&\lambda_n \end{matrix}\right) 是n个特征值构成的对角阵。
由于 U 是正交矩阵,即 UU^{T}=E , E 是单位矩阵。
所以特征分解又可以写成:
L= U\left(\begin{matrix}\lambda_1 & \\&\ddots \\ &&\lambda_n \end{matrix}\right) U^{T}
文献中都是最后导出的这个公式,但大家不要误解,特征分解最右边的是特征矩阵的逆,只是拉普拉斯矩阵的性质才可以写成特征矩阵的转置。
其实从上可以看出:整个推导用到了很多数学的性质,在这里写得详细一些,避免大家形成错误的理解。
6 如何从传统的傅里叶变换、卷积类比到Graph上的傅里叶变换及卷积?
把传统的傅里叶变换以及卷积迁移到Graph上来,核心工作其实就是把拉普拉斯算子的特征函数 e^{-i\omega t} 变为Graph对应的拉普拉斯矩阵的特征向量 。
6.1 推广傅里叶变换
想亲自躬行的读者可以阅读The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains这篇论文,下面是我的理解与提炼:
(a)Graph上的傅里叶变换
传统的傅里叶变换定义为:
F(\omega)=\mathcal{F}[f(t)]=\int_{}^{}f(t)e^{-i\omega t} dt
信号 f(t) 与基函数 e^{-i\omega t} 的积分, 那么为什么要找 e^{-i\omega t} 作为基函数呢?从数学上看, e^{-i\omega t} 是拉普拉斯算子的特征函数(满足特征方程), \omega 就和特征值有关。
广义的特征方程定义为:
A V=\lambda V
其中 A 是一种变换, V 是特征向量或者特征函数(无穷维的向量), \lambda 是特征值。
e^{-i\omega t} 满足:
\Delta e^{-i\omega t}=\frac{\partial^{2}}{\partial t^{2}} e^{-i\omega t}=-\omega^{2} e^{-i\omega t}\
当然 e^{-i\omega t} 就是变换 \Delta 的特征函数, \omega 和特征值密切相关 。
那么,可以联想了, 处理Graph问题的时候,用到拉普拉斯矩阵 (拉普拉斯矩阵就是离散拉普拉斯算子,想了解更多可以参考Discrete Laplace operator), 自然就去找拉普拉斯矩阵的特征向量了。
L 是拉普拉斯矩阵, V 是其特征向量,自然满足下式:
LV=\lambda V
离散积分就是一种内积形式,仿上定义Graph上的傅里叶变换:
F(\lambda_l)=\hat{f}(\lambda_l)=\sum_{i=1}^{N}{f(i) u_l^*(i)}
f 是Graph上的 N 维向量, f(i) 与Graph的顶点一一对应, u_l(i) 表示第 l 个特征向量的第 i 个分量。那么特征值(频率) \lambda_l 下的, f 的Graph 傅里叶变换就是与 \lambda_l 对应的特征向量 u_l 进行内积运算。
注:上述的内积运算是在复数空间中定义的, 所以采用了 u_l^*(i) ,也就是特征向量 u_l 的共轭。 Inner product更多可以参考Inner product space。
利用矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
\left(\begin{matrix} \hat{f}(\lambda_1)\\ \hat{f}(\lambda_2) \\ \vdots \\\hat{f}(\lambda_N) \end{matrix}\right)=\left(\begin{matrix}\ u_1(1) &u_1(2)& \dots &u_1(N) \\u_2(1) &u_2(2)& \dots &u_2(N)\\ \vdots &\vdots &\ddots & \vdots\\ u_N(1) &u_N(2)& \dots &u_N(N) \end{matrix}\right)\left(\begin{matrix}f(1)\\ f(2) \\ \vdots \\f(N) \end{matrix}\right)
即 f 在Graph上傅里叶变换的矩阵形式为 : \hat{f}=U^Tf \qquad(a)
式中: U^T 的定义与第五节中的相同
(b)Graph上的傅里叶逆变换
类似地, 传统的傅里叶逆变换是对频率 \omega 求积分:
\mathcal{F}^{-1}[F(\omega)]=\frac{1}{2\Pi}\int_{}^{}F(\omega)e^{i\omega t} d\omega
迁移到Graph上变为对特征值 \lambda_l 求和:
f(i)=\sum_{l=1}^{N}{\hat{f}(\lambda_l) u_l(i)}
利用矩阵乘法将Graph上的傅里叶逆变换推广到矩阵形式:
\left(\begin{matrix}f(1)\\ f(2) \\ \vdots \\f(N) \end{matrix}\right)= \left(\begin{matrix}\ u_1(1) &u_2(1)& \dots &u_N(1) \\u_1(2) &u_2(2)& \dots &u_N(2)\\ \vdots &\vdots &\ddots & \vdots\\ u_1(N) &u_2(N)& \dots &u_N(N) \end{matrix}\right) \left(\begin{matrix} \hat{f}(\lambda_1)\\ \hat{f}(\lambda_2) \\ \vdots \\\hat{f}(\lambda_N) \end{matrix}\right)
即 f 在Graph上傅里叶逆变换的矩阵形式为: f=U\hat{f} \qquad(b)
式中: U 的定义与第五节中的相同
6.2 推广卷积
在上面的基础上,利用 卷积定理 类比来将卷积运算,推广到Graph上。
卷积定理:函数卷积的傅里叶变换是函数傅立叶变换的乘积,即对于函数 f(t) 与 h(t) 两者的卷积是其函数傅立叶变换乘积的逆变换:
f*h=\mathcal{F}^{-1}\left[ \hat{f}(\omega)\hat{h}(\omega) \right]=\frac{1}{2\Pi}\int_{}^{} \hat{f}(\omega)\hat{h}(\omega)e^{i\omega t} d\omega
类比到Graph上并把傅里叶变换的定义带入, f 与卷积核 h 在Graph上的卷积可按下列步骤求出:
f 的傅里叶变换为 \hat{f}=U^Tf
卷积核 h 的傅里叶变换写成对角矩阵的形式即为: \left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right)
\hat{h}(\lambda_l)=\sum_{i=1}^{N}{h(i) u_l^*(i)} 是 根据需要设计的卷积核 h 在Graph上的傅里叶变换。
两者的傅立叶变换乘积即为: \left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right)U^Tf
再乘以 U 求两者傅立叶变换乘积的逆变换,则求出卷积:
(f*h)_G= U\left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right) U^Tf \qquad(1)
式中: U 及U^{T} 的定义与第五节中的相同。
注:很多论文中的Graph卷积公式为:
(f*h)_G=U((U^Th)\odot(U^Tf)) \qquad(2)
\odot 表示Hadamard product(哈达马积),对于两个维度相同的向量、矩阵、张量进行对应位置的逐元素乘积运算。
其实式(2)与式(1)是完全等价的,详细的证明见我的另一篇文章。
这里主要推(1)式是为了和后面的deep learning相结合。
这部分理论也是我看了很久才想明白的,在此记录下来,如果是想继续探究理论的朋友,可以作为「入门小引」,毕竟理论还很深!对于喜欢实践的朋友,也能初步了解理论基础,也是「开卷有益」。
7 为什么拉普拉斯矩阵的 特征向量可以作为傅里叶变换的基?
傅里叶变换一个本质理解就是: 把任意一个函数表示成了若干个正交函数(由 \sin\omega t,\cos\omega t 构成)的线性组合。

通过第六节中(b)式也能看出, graph傅里叶变换也把graph上定义的任意向量 f ,表示成了拉普拉斯矩阵特征向量的线性组合,即:
f=\hat{f}(\lambda_1)u_1+\hat{f}(\lambda_2)u_2+\cdots +\hat{f}(\lambda_n)u_n
那么 :为什么graph上任意的向量 f 都可以表示成这样的线性组合?
原因在于 (\vec{u_1},\vec{u_2},\cdots,\vec{u_n}) 是graph上 n 维空间中的 n 个线性无关的正交向量 (原因参看第五节中拉普拉斯矩阵的性质),由线性代数的知识可以知道:n 维空间中 n 个线性无关的向量可以构成空间的一组基,而且拉普拉斯矩阵的特征向量还是一组正交基。
此外,对于传统的傅里叶变换,拉普拉斯算子的特征值 \omega 表示谐波 \sin\omega t,\cos\omega t 的频率。与之类似,拉普拉斯矩阵的特征值 \lambda_i 也表示图拉普拉斯变换的频率。具体的分析可以看如下的文章。
Graph Convolution的理论告一段落了,下面开始介绍Graph Convolution Neural Network。
8 Deep Learning中的Graph Convolution
Deep learning 中的Graph Convolution直接看上去会和第6节推导出的图卷积公式有很大的不同,但是万变不离其宗,(1)式是推导的本源。
第1节的内容已经解释得很清楚:Deep learning 中的Convolution就是要设计含有trainable共享参数的kernel,从(1)式看很直观:graph convolution中的卷积参数就是 diag(\hat h(\lambda_l) ) 。
8.1 第一代GCN
Spectral Networks and Locally Connected Networks on Graphs中 简单粗暴地把 diag(\hat h(\lambda_l) ) 变成了卷积核 diag(\theta_l ) , 也就是:
y_{output}=\sigma \left(U g_\theta(\Lambda) U^T x \right) \qquad(3)
(为避免混淆,本文中称 g_\theta(\Lambda) 是卷积核, U g_\theta(\Lambda) U^T 的运算结果为卷积运算矩阵)
g_\theta(\Lambda)=\left(\begin{matrix}\theta_1 &\\&\ddots \\ &&\theta_n \end{matrix}\right)
式(3)就是标准的第一代GCN中的layer了,其中 \sigma(\cdot) 是激活函数, \Theta=({\theta_1},{\theta_2},\cdots,{\theta_n}) 就跟三层神经网络中的weight一样是任意的参数,通过初始化赋值然后利用误差反向传播进行调整, x 就是graph上对应于每个顶点的feature vector(由特数据集提取特征构成的向量)。
第一代的参数方法存在着一些弊端:主要在于:
(1)每一次前向传播,都要计算 U ,diag(\theta_l ) 及 U^T 三者的矩阵乘积,特别是对于大规模的graph,计算的代价较高,也就是论文中 \mathcal{O}(n^3) 的计算复杂度
(2)卷积核不具有spatial localization(这个在第9节中进一步阐述)
(3)卷积核需要 n 个参数
由于以上的缺点第二代的卷积核设计应运而生。
8.2 第二代GCN
(Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering),把 \hat h(\lambda_l) 巧妙地设计成了 \sum_{j=0}^K \alpha_j \lambda^j_l ,也就是:
y_{output}=\sigma \left(U g_\theta(\Lambda) U^T x \right) \qquad(4)
g_\theta(\Lambda)=\left(\begin{matrix}\sum_{j=0}^K \alpha_j \lambda^j_1 &\\&\ddots \\ && \sum_{j=0}^K \alpha_j \lambda^j_n \end{matrix}\right)
上面的公式仿佛还什么都看不出来,下面利用矩阵乘法进行变换,来一探究竟。
\left(\begin{matrix}\sum_{j=0}^K \alpha_j \lambda^j_1 &\\&\ddots \\ && \sum_{j=0}^K \alpha_j \lambda^j_n \end{matrix}\right)=\sum_{j=0}^K \alpha_j \Lambda^j
进而可以导出:
U \sum_{j=0}^K \alpha_j \Lambda^j U^T =\sum_{j=0}^K \alpha_j U\Lambda^j U^T = \sum_{j=0}^K \alpha_j L^j
上式成立是因为 L^2=U \Lambda U^TU \Lambda U^T=U \Lambda^2 U^T 且 U^T U=E
各符号的定义都同第五节。
(4)式就变成了:
y_{output}=\sigma \left( \sum_{j=0}^{K-1} \alpha_j L^j x \right) \qquad(5)
其中 ({\alpha_0},{\alpha_1},\cdots,{\alpha_{K-1}}) 是任意的参数,通过初始化赋值然后利用误差反向传播进行调整。
式(5)所设计的卷积核其优点在于在于:
(1)卷积核只有 K 个参数,一般 K 远小于 n ,参数的复杂度被大大降低了。
(2)矩阵变换后,神奇地发现不需要做特征分解了,直接用拉普拉斯矩阵 L 进行变换。然而由于要计算 L^j ,计算复杂度还是 \mathcal{O}(n^3)
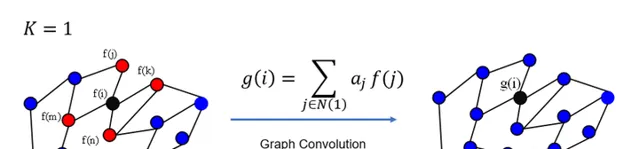
(3)卷积核具有很好的spatial localization,特别地, K 就是卷积核的receptive field,也就是说每次卷积会将中心顶点K-hop neighbor上的feature进行加权求和,权系数就是 \alpha_k
更直观地看, K =1就是对每个顶点上一阶neighbor的feature进行加权求和,如下图所示:
同理, K =2的情形如下图所示:
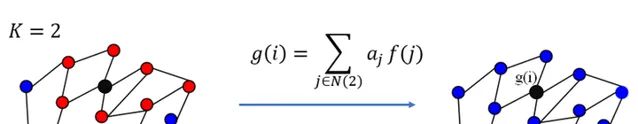
注:上图只是以一个顶点作为实例,GCN每一次卷积对所有的顶点都完成了图示的操作。
8.3 利用Chebyshev多项式作为卷积核
在GCN领域中,利用Chebyshev多项式作为卷积核是非常通用的形式。针对这部分内容,我专门整理了如下的文章。
上述的内容已经阐明了GCN的整体思路,其他的一些形式都是「万变不离其宗」。例如Semi-Supervised classification with Graph Convolutional Networks一文中的GCN形式,其实是二阶Chebyshev多项式推导出的特例。
在我最近发表的一篇论文中:就是用这种GCN形式作为基于有限检测器的路网规模交通流量估计问题(一种特殊的时空矩阵填充问题)的baseline,即原文4.2节部分的CGMC模型。感兴趣的朋友可以阅读如下的链接。
Zhang, Z., Li, M., Lin, X., & Wang, Y. (2020). Network-wide traffic flow estimation with insufficient volume detection and crowdsourcing data. Transportation Research Part C: Emerging Technologies ,121, 102870.
9 在GCN中的 Local Connectivity 和 Parameter Sharing
CNN中有两大核心思想:网络局部连接,卷积核参数共享。这两点内容的详细理解可以看我的这个回答。
那么我们不禁会联想:这两点在GCN中是怎样的呢?以下图的graph结构为例来探究一下。
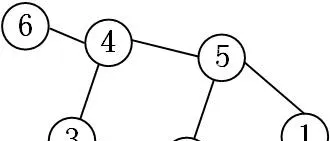
9.1 GCN中的Local Connectivity
(a)如果利用第一代GCN,根据式(3)卷积运算矩阵( U g_\theta(\Lambda) U^T ) 即为:

这个时候,可以发现这个卷积核没有 local的性质,因为该卷积核得到的运算矩阵在所有位置上都有非0元素。以第一个顶点为例,如果考虑一阶local关系的话,那么卷积核中第一行应该只有[1,1],[1,2],[1,5]这三个位置的元素非0。换 句话说,这是一个global全连接的卷积核。
(b)如果是第二代GCN,根据式(5)当 K=0 卷积运算矩阵即为:
\left[ \begin{matrix} \alpha_0 & 0 & 0 &0&0&0\\ 0 & \alpha_0 & 0 &0&0&0 \\ 0 & 0 & \alpha_0 &0&0&0\\ 0 & 0 & 0 &\alpha_0&0&0\\ 0 & 0 & 0 &0&\alpha_0&0\\ 0 & 0 & 0 &0&0&\alpha_0 \end{matrix} \right]
当 K=1 卷积运算矩阵即为:
\left[ \begin{matrix} \alpha_0+2\alpha_1 & -\alpha_1 & 0 &0&-\alpha_1&0\\ -\alpha_1 & \alpha_0+3\alpha_1 & -\alpha_1 &0&-\alpha_1&0 \\ 0 &- \alpha_1 & \alpha_0+2\alpha_1 &-\alpha_1&0&0\\ 0 & 0 & -\alpha_1 &\alpha_0+3\alpha_1&-\alpha_1&-\alpha_1\\ -\alpha_1 & -\alpha_1 & 0 &-\alpha_1&\alpha_0+3\alpha_1&0\\ 0 & 0 & 0 &-\alpha_1&0&\alpha_0+\alpha_1 \end{matrix} \right]
当 K=2 卷积运算矩阵即为:
\left[ \begin{matrix} \alpha_0+2\alpha_1+6\alpha_2 & -\alpha_1-4\alpha_2 & \alpha_2 &\alpha_2&-\alpha_1-4\alpha_2&0\\ -\alpha_1-4\alpha_2 & \alpha_0+3\alpha_1+12\alpha_2 & -\alpha_1-5\alpha_2 &2\alpha_2&-\alpha_1-5\alpha_2&0 \\ \alpha_2 &- \alpha_1-5\alpha_2 & \alpha_0+2\alpha_1+6\alpha_2 &-\alpha_1-5\alpha_2&2\alpha_2&\alpha_2\\ \alpha_2 & 2\alpha_2 & -\alpha_1-5\alpha_2 &\alpha_0+3\alpha_1+12\alpha_2&-\alpha_1-6\alpha_2&-\alpha_1-4\alpha_2\\ -\alpha_1-4\alpha_2 & -\alpha_1-5\alpha_2 & 2\alpha_2 &-\alpha_1-6\alpha_2&\alpha_0+3\alpha_1+12\alpha_2&\alpha_2\\ 0 & 0 & \alpha_2 &-\alpha_1-4\alpha_2&\alpha_2&\alpha_0+\alpha_1+2\alpha_2 \end{matrix} \right]
看一下图的邻接结构,卷积运算矩阵的非0元素都在localize的位置上。
9.2 GCN中的Parameter Sharing
相关内容比较多,我专门写了一篇文章,感兴趣的朋友可以阅读一下。
在我最近新发表的一篇论文中, 就充分利用卷积模块,提出了结合图卷积(GCN)与 1\times1 卷积的全新GRU单元,进一步构建双向循环神经网络,来一体化解决路网级实时交通数据补全与预测问题,算例实验充分讨论了该模型对于提取时空数据中语义信息的有效性。
论文链接如下 , 欢迎感兴趣的朋友下载阅读
如果这篇论文的内容对于大家的研究工作有帮助,也希望进行引用。
Zhang, Z., Lin, X., Li, M., & Wang, Y. (2021). A customized deep learning approach to integrate network-scale online traffic data imputation and prediction. Transportation Research Part C: Emerging Technologies , 132, 103372.
10 GCN的可解释性
前面的内容,已经介绍了GCN的基本原理以及一些特性的理解。 这章节的内容是我个人的部分研究工作,将GCN应用于大规模交通路网速度预测问题中,通过参数的可视化,给出了所提出深度学习模型的可解释性分析。 感兴趣的朋友可以阅读一下我们的论文。
如果这个回答的内容对于大家的研究工作有帮助,也希望引用我们的论文。
Zhang, Z., Li, M., Lin, X., Wang, Y., & He, F. (2019). Multistep speed prediction on traffic networks: A deep learning approach considering spatio-temporal dependencies. Transportation Research Part C: Emerging Technologies , 105, 297-322.
11 关于有向图问题
前面的理论推导都是 关于无向图, 如果是 有向图问题,最大的区别就是邻接矩阵会变成非对称矩阵, 这个时候不能直接定义 拉普利矩阵及其谱分解(拉普拉斯矩阵本身是定义在无向图上的)。这个时候有两条思路解决问题:
(a)要想保持理论上的完美,就需要重新定义图的邻接关系,保持对称性
比如MotifNet: a motif-based Graph Convolutional Network for directed graphs 提出利用 Graph Motifs定义图的邻接关系。
(b)如果只是为了应用,有其他形式的GCN或者GAT可以处理有向图
简而言之,要想简单地处理有向图问题,那就换成一种逐顶点(node-wise)的运算方式,可以参考下面这篇文章中的3.2及3.3节。
值得说明的是:GAT作者写道「It is worth noting that, as Kipf & Welling (2017) and Atwood & Towsley (2016), our work can also be reformulated as a particular instance of MoNet (Monti et al., 2016). 」
也就是说本质上这些模型都可以认为是在重新定义了图的邻接关系后,再进行基本的卷积运算。
12 GCN的过度平滑问题
公式(5)给出的卷积核中,含有拉普拉斯矩阵的 j 次幂。 当 j 的取值较大时,GCN学习到的特征可能会存在过度平滑现象,即每个顶点的输出特征都十分相似。这个问题的原因及解决方法可以参考我下面的回答。
13 GCN的相关资料
——————GCN的综述与论文合辑————————
——————动手教程————————
——————华丽的分割线————————
还写了一些关于机器学习比较热点的文章,大家有需要可以看看,一起学习进步!










