【目录】
从开天辟地到天下一统
别看副标题取得气势磅礴,但其实图形加速卡第一次拥有GPU这一试图与CPU平分秋色的名字,是在1999年。也就是说享此殊荣的GeForce 256,其实还得叫我一声哥?把坐标变换、灯光照明、三角形设置裁剪和一个每秒能处理一千万个多边形的渲染引擎集成到一个芯片上[1],是它最大的卖点。虽然这些功能现在看来由GPU负责天经地义,但是在当时,却是相当大的突破。

对 大量数据执行相同操作(SIMD) ,是并行计算的最爱,也是GPU得以分家立业并不断从CPU挖墙脚的万恶之源。而GeForce 256只是这万里长征梦最开始的地方,但其大量数据具体执行什么操作是内置的(固定管线),这不还是特定算法的加速器而已么,怎配得上处理器三个字?
所以两年后,GeForce 3拥有了顶点着色器和可配置的片元管线,进入了DirectX8的时代;而第二年也就是2002年,ATI(后被AMD收购,此时应该是ATI YES?)发布了Radeon9700,其支持24位可编程的片元着色器,直接拥抱DirectX9;英伟达在2003年也发布了支持32位可编程片元的GeForce FX,虽然初始型号有点拉跨[2]。
在这个「上古混沌」时期,GPU走在一条 不断提高可编程性 的康庄大道上,而终于在2006年随着基于Tesla架构构建的第八代GeForce推出,迎来了一股小高潮。我们也迎来了本文的主角——Tesla架构。

在上古时期,顶点计算单元因坐标变换的需要,有着低延迟高精度数学运算的设计(能力越大责任越大,这也是为什么其在上古时期承担着更为复杂的任务,并最早实现可编程性的原因);而片元计算单元因纹理过滤的特点,则有着高延迟低精度的设计。[3]
术业有专攻,因不同的需求,有多种独立计算单元似乎理所当然。但随着GPU在可编程性上一路狂奔,两种计算单元在功能上有了越来越多的重合,就像前端工程师和后端工程师互相卷成全栈工程师,老板要考虑开掉一个一样自然(奇怪的比喻还有很多,大家权当笑谈), 顶点和片元两种计算单元终于走到了分久必合的时候 。
当然合并的理由不止如此。通常情况下,要处理的片元比要处理的顶点多,因此顶点计算单元和片元计算单元数量比通常是1:3。然而同样是因为GPU可编程性越来越大,两者的最佳数量比因不同的程序差异巨大,很难提前确定。(特别是DX10推出的坑爹几何着色器,谁知道程序员们会写些什么?)
工作负载越来越难以平衡,处理大三角形,顶点太闲;处理小三角形,片元太闲。以前业务功能单一,三个前端配一个后端,大家都能996,现在业务需求和模式变动频繁,难免有人要摸鱼。资本家把心一横:「招全栈工程师!」
全是「全栈工程师」的架构设计还有很多好处,现在看是只能处理顶点和片元,以后没准还能干点其他的,最好是啥都能干?以后的章节会陆陆续续提到。但现在,先让我们来仔细看看,这个距今十几年但仍魅力无限的Tesla架构。
剖开麻雀的身体
与现在动辄上万个核的3090相比,Tesla架构寒酸得让人心疼。但麻雀虽小五脏俱全,非常适合刚接触GPU架构的我们学习(直接看最新显卡的架构图,在看清楚前眼睛已经瞎了)。
而随着我们在之后的文章中一步步沿着显卡的演化路径前进到当下,我们会惊奇地发现, Tesla架构所奠定的基础设施框架,以及其所蕴含的设计思想历久弥新,从未过时 。
好,闲话少说,让我们掏出手术刀,开始解剖:
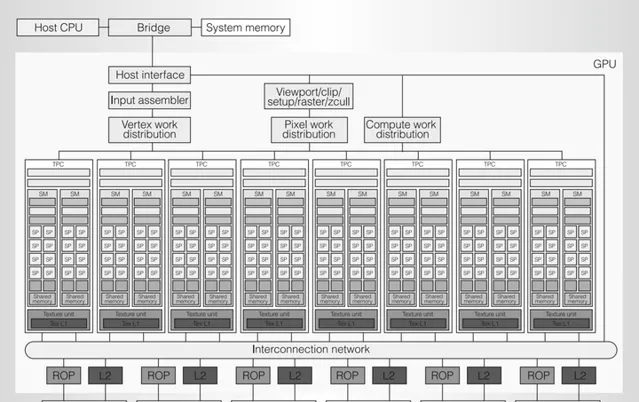
在细致认识这只「麻雀」的每一个器官之前,我们先来简单划分一下,有个整体的印象:
伟大的劳动人民
接下来让我们逐一认识一下这些劳动人民:
从外包公司的角度去理解GPU,整个流程就逐渐明晰了起来。而TPC里密密麻麻的格子间中,到底有着什么不为人知的秘密?各类着色器纷繁复杂的指令,是如何在其间高效且有序完成的,请看下一章,Tesla架构(二)之血汗工厂篇。
如果您觉得本篇文章对你有点帮助的话,可以点个赞再走哦~别只是放到收藏夹里吃灰呀~
参考
- Geforce 256
- GeForce FX
- Tesla架构白皮书











