Aurora最近上市,市值超過一百億美金。其自動駕駛工程師團隊超過1400人;曾收購一個激光雷達公司Blackmore,采用的FMCW而不是TOF技術,還收購一個激光雷達芯片公司Ours,也是基於FMCW技術的芯片設計(Lidar on-chip);當然,最著名的收購是Uber ATG團隊(被稱「蛇吞象」)。
2017年成立的Aurora,其創始人來自Google、Uber和Tesla,背景算是「根正苗紅」。剛開始是面向無人出租車套用,但近一年已經把 商用大卡車 業務作為自己的主業。
除了激光雷達技術和激光雷達芯片技術,Aurora的自動駕駛演算法很少公開,最近上市前的融資材料公布了一些資訊:
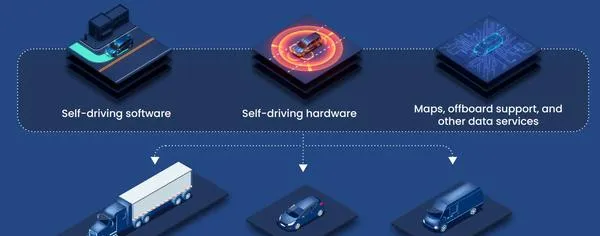
這是Aurora Driver平台概覽:軟件、硬件、地圖、數據服務、車輛
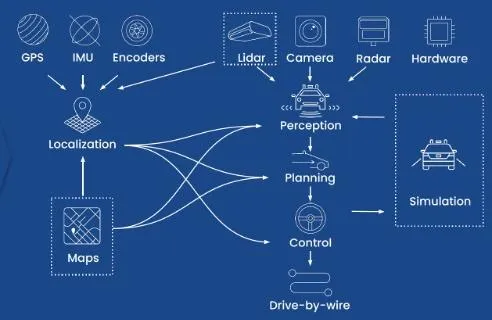
這是其全棧自動駕駛技術一覽:傳感器、定位、地圖、感知、規劃、控制、仿真、線控
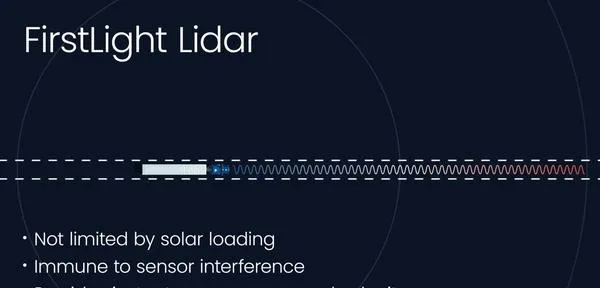
這是其激光雷達的優點介紹:長距離感知、抗幹擾,能同時測速和距離
提供仿真測試和數據回放的示意圖:減少路測、其運動規劃仿真比路測成本減少2500+倍,1小時仿真測試相當於5萬個車輛路測,其中可以模擬2百25萬次無保護左拐彎。

高畫質地圖制作Aurora Atlas:幾乎即時更新、制圖過程大規模並列

最後正在開發的自動駕駛2.0系統,和自動駕駛1.0系統比較如下:

之前曾在CVPR'21的workshop特邀報告中介紹過Aurora的兩個工作:
其中一個工作題目是「Bridging Perception to motion planning「
另一個工作題目是」The value proposition of forecasting for motion planning「
其實這兩個報告都提到Aurora收購的Uber ATG團隊已發表一些文章,從中可以探究其技術的細節 (註:原來Uber ATG在多倫多的分部並沒有歸屬Aurora,其首席科學家已經創業成立了自動駕駛公司Waabi,而且其主要套用場景也是選的商業卡車!),下面介紹相關的論文如下:
1 「 LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting」
原來Uber ATG匹茲堡團隊在2020年10月15日上傳arXiv。

提出的一個方法, LaserFlow ,基於激光雷達的三維目標檢測和運動預測。該方法利用激光雷達的 距離檢視(RV) 表示 ,在傳感器的全距離即時操作,沒有BEV的體素化或資料壓縮。提出的 多掃描(multi- sweep) 融合架構,直接從距離影像提取和合並時域特征。此外,受 課程學習 啟發提出一種技術,學習未來的軌跡的概率分布。
如圖是激光雷達輸入距離數據序列和不確定性的軌跡輸出的例子:a)輸入的激光雷達距離(RV)數據序列,輸出不確定性的軌跡(BEV)

如圖所示,提出的網絡架構:提取multi-sweep特征,檢測和預測運動目標。
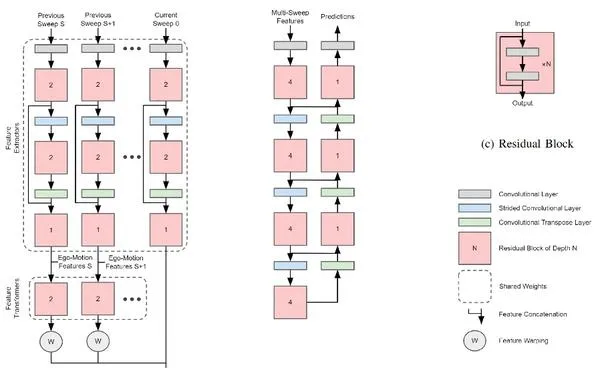
在multi-sweep體系結構,特征提取獨立於每個激光雷達在其原始檢視的sweep。每個sweep的特征透過一個特征轉換器,學習從原始座標系到全域座標系的特征轉換。以前的sweep,warp到當前sweep的影像,並連線在一起,這個作為transformer network;這個multi- sweep的特征圖輸入到一個骨幹網絡檢測目標和估計其運動。
給定multi-sweep激光雷達數據,模型的目標(goal)是,預測所有軌跡的概率。對於距離影像的每個點,預測一組類別概率,即確定點落在哪個目標上,輸出3-D目標框的維度,同時輸出目標的位移向量、旋轉角和不確定性得分。激光雷達點雲預測的軌跡最後透過近似mean-shift演算法聚類成目標(object)。
端到端訓練的損失項包括focal loss的分類和K-L發散的回歸:
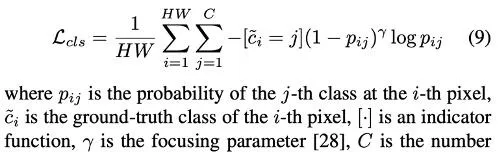
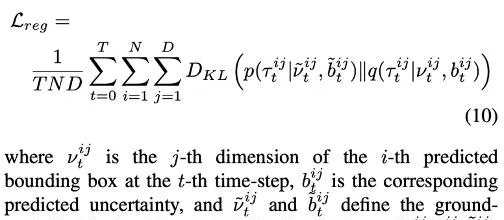
其中KL發散定義為
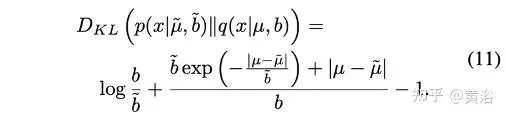
KL發散的梯度計算,是為了重新加權損失,估計不確定性:
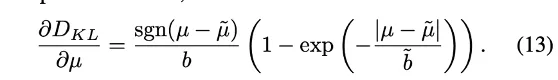
透過不確定性的 課程學習 ,可以確保早期預測在後期得到修正。
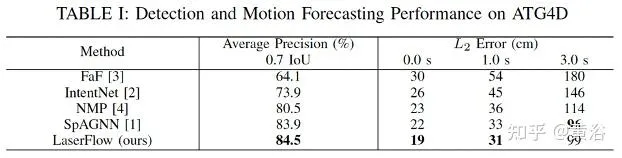
實驗結果如下:基準方法包括

2 」Map-Adaptive Goal-Based Trajectory Prediction」
原來Uber ATG匹茲堡團隊在2020年11月13日上傳arXiv。

提出一種多模態、長時車輛軌跡預測方法,GoalNet。該方法依賴於在豐富的環境地圖中捕獲的車道中心線為每輛車生成一組建議的目標路徑(goal paths)。用這些執行時生成、動態適應場景的路徑作為空域錨,預測一組基於目標(goal-based)的軌跡以及這些目標上的類別分布。這種方法能夠直接模擬交通參與者的目標導向(goal- directed)行為,釋放更準確長時預測的潛力。在大規模內部駕駛數據集和公共數據集nuScenes上的實驗結果表明,該模型能夠更好地推廣到一個完全新出現城市的道路場景。
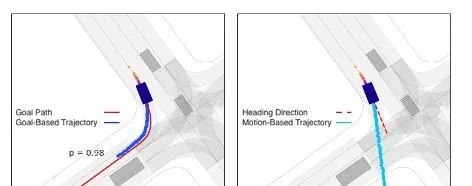
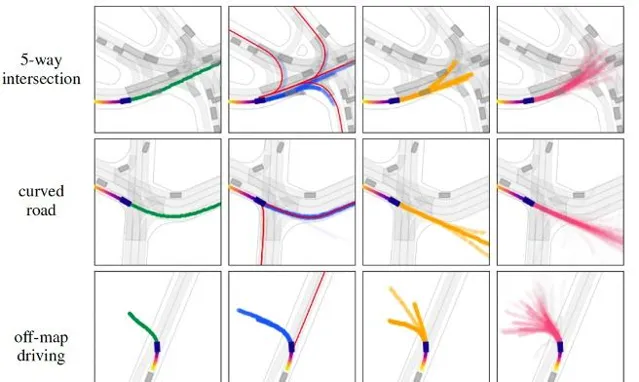
如下圖顯示基於目標(goal-based)和基於運動(motion-based)的軌跡雙重性。兩個不同的場景,每個場景都有一個感興趣的參與者。圖( a )中,基於目標的軌跡得到高概率( 98 %),因為目標為參與者的運動提供了一個很好的解釋。圖( b )中,由於候選目標路徑不能完全解釋參與者的當前運動,比圖( a )( 2 %)更高的概率( 27 %)分配到基於運動的軌跡。
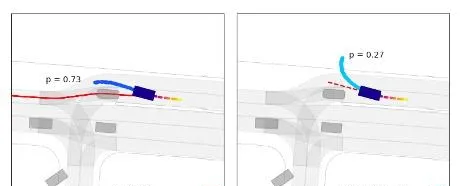
在這兩種情況下,只為每個參與者提供一條建議的目標路徑(goal path),這意味著模型的最簡單變型會生成兩條軌跡預測:一條基於目標的軌跡用目標路徑作為空域錨,另一條基於運動的軌跡用參與者的前向作為參考方向。這些範例說明,模型能夠在目標路徑有意義時使用,但在沒有目標能夠充分解釋參與者當前運動時,也可以學習退回到基於運動的預測。
該模型 GoalNet ,其框架概覽如圖所示:包括3個元件,即 ( 1 )目標提議(goal proposal):基於局部地圖幾何,為每個參與者提出一組目標;(2)編碼器模組:參與者狀態和場景上下文在這個模組中進行編碼;(3)圖網絡模組:用圖網絡基於編碼特征進行預測。

在圖網絡中,每個圖包含兩種類別的節點:單個參與者節點 A 和多個目標節點Gj;圖的有向邊 Ej ,起源於每個目標節點,並終止於參與者節點。給定得到的節點和邊緣表示,從參與者-目標邊緣可預測基於目標的軌跡和概率,並從參與者節點預測無目標(goal-free)軌跡和概率。
模型訓練的分類項和回歸損失項分別是:
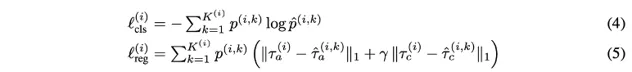
實驗結果如下:其中基準演算法是

如圖左欄顯示感興趣參與者的真實未來軌跡(綠色),隨後列顯示來自 Goal Net (藍色)、 MTP (黃色)和MultiPath(粉色)的預測軌跡。對所有方法,軌跡概率編碼成α不透明值。對 於Goal Net,用紅色顯示目標路徑。
3 「 RV-FuseNet: Range View Based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting 」
原Uber ATG匹茲堡團隊、Aurora和Motional匹茲堡團隊等公司成員在2021年3月23日上傳arXiv。

提出一種從時間序列激光雷達數據直接做聯合檢測和軌跡估計的方法, RV-FuseNet 。用激光雷達數據的距離檢視(RV)表征。以前方法將時間序列數據投影到一個時域融合的公共視角,與位置不同。對BEV方法來說已經足夠,但對RV方法,會導致資訊遺失和數據失真,對效能產生不利影響。為此提出一種簡單而有效的新架構, 步進融合(Incremental Fusion) ,將每個RV掃描依次投影到下一個掃描視角,將資訊損失降到最低。
如圖展示RV-FuseNet的概覽圖:當激光雷達傳感器旋轉時,不斷產生測量值。這些數據被分割成「sweeps」切片,每個切片包含一個完整的360◦旋轉測量值;用sweeps時間序列提取每點的時-空特征。用距離檢視(RV)表征,基於骨幹網絡進行特征學習;為解決RV時域融合的挑戰,提出了一種序列組合時間序列數據的方案;用每點特征生成最終的類別檢測及其軌跡,其中每個點被分割成例項,而例項軌跡來自於其點軌跡的平均,最後采用NMS消除重復的檢測和軌跡。
用概率損失函數對模型進行端到端的訓練,這裏損失函數定義為分類項和回歸項:
實驗結果如下:基準方法是前面提到的SpAGNN和前面分析過的Laserflow。
4 「 MultiXNet: Multi class Multistage Multimodal Motion Prediction 」
原來Uber ATG匹茲堡團隊在2021年5月24日上傳arXiv。
提出 MultiXNet ,一個直接基於激光雷達傳感器數據的端到端目標檢測和運動預測方法。該方法處理多個類的交通行為者,添加一個聯合訓練的第二階段 軌跡細化 步驟,並產生一個未來參與者運動的 多模態 概率分布,其中包括多個離散交通行為和標定連續位置的 不確定性 。
該方法基於以前SOA的工作 IntentNet ,如圖是MultiXNet架構的一覽圖:其中第一階段對應的是IntentNet,即參與者檢測及其單模態運動預測,而第二階段對應的是多模態和不確定性-覺察的預測細化。
模型輸入的是激光雷達和地圖的表征,其中地圖的靜態部份有駕駛路徑、人行道、車道線和道路邊界、交叉路口、私家車道和停車位等。
這裏訓練損失函數如下定義:
位置不確定性分解為 along-track (AT) 和 cross-track (CT) 方向,這裏以AT為例,給出其訓練損失項:
KLCT的損失項定義類似。
在第二階段的預測細化中,在最終未來軌跡和不確定性預測進行之前,RROI (rotated ROI)特征圖要透過一個輕量級 CNN 網絡。第一和第二階段網絡聯合訓練,第一階段使用全部損失 L 和第二個階段只有未來的預測損失,第二階段預測被用作最終輸出軌跡。第二階段是完全可微分的,因此訓練時,梯度流過第二階段進入第一階段。
多模態預測輸出有一個選項,可以透過EM演算法或者透過混合密度網絡進行學習。多模態預測的損失函數包括一個軌跡損失項和一個軌跡模式概率的cross entropy,這裏第一階段只有單模式預測。
多參與者包括車輛、行人和單車。在主幹網計算共享特征之後,輸出分成三組,一類是一組。實驗中發現,行人和單車,並不需要采用第二階段的多模態預測,第一階段的單模態預測結果就很好。
實驗結果如下:基準方法是以前提到的IntentNet和SpAGNN 。
5 「Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving 」
原來Uber ATG匹茲堡團隊在2020年10月27日上傳arXiv。
提出一種端到端目標檢測和軌跡預測的方法,利用激光雷達返回訊號和相機影像的多檢視表征。這項工作提出一個有效通用融合方法,其模型建立在一個BEV網絡,融合從一個序列歷史 激光雷達數據的體素化特征以及光柵化高畫質地圖,執行檢測和預測任務。作者擴充套件這個模型,用原始激光雷達資訊的原生非量化表征構建激光雷達距離檢視( RV )特征。RV 特征圖投影到 BEV ,融合從激光雷達和高畫質地圖計算的 BEV 特征。融合的特征,在一個單一端到端可訓練網絡中進一步處理,輸出最終檢測和軌跡。此外,該框架以一個簡單和計算有效的方式在 RV 融合激光雷達和相機。
如圖是多視角融合的架構圖:由兩個主要部份組成,特征提取器和特征投影器;輸入包括網絡攝影機影像、激光雷達點雲和高畫質地圖的光柵化影像;多視角模型考慮激光雷達輸入的兩個分支,一個是BEV,另一個是RV;而網絡攝影機影像和激光雷達融合在RV分支進行。
訓練的損失函數如下:
實驗結果如下:基準演算法包括
實驗中多視角融合MV方法記做:LC-MV(LiDAR + camera)和L-MV (LiDAR only)兩種。
如圖是LC-MV (中間) 和MultiXNet (底部)的比較:三個例項,包括遮擋車輛、遮擋行人和遮擋單車,結果分別顯示為預測(藍色)、真值(紅色)。
6 「 MVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data 「
Aurora公司(收購的原Uber ATG團隊)在2021年4月21日上傳arXiv。
這項工作 MVFuseNet ,一種端到端的方法,從時間序列的激光雷達數據聯合進行目標檢測和運動預測。大多數方法在一個單一檢視操作,即投影數據到距離檢視( RV )或鳥瞰圖( BEV )。相比之下,這個方法有效利用 RV 和 BEV 做時-空特征學習,是時域融合網絡的一部份,也是在一個骨幹網絡做多尺度特征學習。此外,提出一種序貫融合方法,有效地利用時域融合網絡的多個檢視。
如圖是MVFuseNet 的一覽圖:(a)在RV和BEV的激光雷達數據多檢視時域融合學習時-空特征;將數據從一次sweep投影到時間序列中的下一個sweep,從而按順序聚合這些sweeps;(b)這些多檢視的時-空特征,結合地圖特征在多檢視骨幹進一步處理,學習多尺度特征,最終做檢測和運動預測。
如下圖是網絡元件的概覽:(a) 用所描述的per-sweep網絡在兩個檢視時域融合中處理每個sweep。註意,在時域融合,沿著時間和檢視不共享權重。(b) HD Map是和網絡一起處理的,學習與激光雷達特征相結合的本地地圖特征。(c) 非對稱U-網絡對BEV的多尺度特征進行提取。
在RV,只有寬度維是下采樣,而第一個摺積層跨度為零。網絡的每一層都表示為B,k×k,/s,C,N,其中B是block名,k是核大小,s是步長,C是通道數,N是block的重復次數。Conv表示一個摺積層,然後是批次處理歸一化和ReLU。RES表示殘留誤差block。最後提示,用雙線性插值法對樣本進行采樣。
實驗結果如下:其中基準方法有
總結一下。
基於Uber ATG的工作,可以看出Aurora的感知-預測-決策規劃是一體化設計的,而且考慮了模仿學習的數據驅動模式開發,采用不確定性-覺察、多模態、多智體(車輛、行人和單車)形式,感知的融合基本實作端到端時空融合(包括定位地圖特征);激光雷達感知方面基於收購的公司實作FMCW技術的幾個優點,而且自研傳感器及其芯片設計可以控制成本和保證系統最佳化,另外自研還開發了高畫質地圖數據服務,和模擬仿真及視覺化技術。











