註:這篇文章的副標題和之前張偉同學的文章有些相似,不過這裏討論的視角會以AI系統視角為切入點,所以資訊量存在比較明顯的差異,希望張偉同學看到不要覺得有盜標之嫌,因為我確實覺得這個副標題比較貼切:)。
每一代NV GPU的釋出都會給業界帶來新的想象空間。作為AI系統(這裏主要代指深度學習系統)方向的從業者,最關心的自然是每一代GPU能夠為AI系統領域帶來哪些新的變量。
從之前NV GPU的甲方消費者,轉變為現在的乙方提供者,視角變化讓自己可以從不同角度來看待這個問題。這裏會以深度學習系統的發展蹤跡為套用載體,來回顧NV GPU架構的歷史變遷。
整個回顧會從最早套用於深度學習計算加速的GTX 580 開始,直到最新的Ampere架構。對每一代GPU的回顧會從以下幾個方面展開:
首先來看Fermi,這也是第一款套用於代表性深度學習加速場景(AlexNet)的GPU架構。
1. Fermi
Fermi是支持CUDA的第三代GPU架構,第一代是2006年推出的G80架構(公開材料沒有查詢到G80的whitepaper,相對詳細一些的分析可以參見anandtech的這篇文章),第二代是2008年推出的GT200架構(類似G80,在NV官網上已經找不到類似Fermi的whitepaper,倒是在一些分析網站上有一些關聯內容,比如beyond3d的這個和anandtech的這篇)。從Fermi時代開始,Tesla產品線的每一代GPU的whitepaper都提供了公開下載的連結,裏面提到了大量的架構技術細節。這篇回顧文章正是以這些whitepaper為基礎展開。在Fermi的這篇whitepaper裏提到了這樣一段話,讀來讓人感慨頗深:
When designing each new generation GPU, it has always been the philosophy at NVIDIA to improve both existing application performance and GPU programmability ; while faster application performance brings immediate benefits , it is the GPU’s relentless advancement in programmability that has allowed it to evolve into the most versatile parallel processor of our time . It was with this mindset that we set out to develop the successor to the GT200 architecture.以hindsight式的視角來看,將可編程性放在和效能相齊的位置,是一個重要的決策。因為可編程性的改善對於提升NV GPU的網絡效應和使用者切換成本,至關重要。在俞軍的【產品方法論】裏提到了 使用者價值=新體驗-舊體驗-切換成本 。這個公式也適用於GPGPU這種To B性質的產品。以NV當前代際GPU代指新體驗,上一代GPU代指舊體驗,效能提升相當於在強化新體驗,可編程性相當於在減少切換成本。以NV GPU代指舊體驗,競品代指新體驗,這個公式同樣成立,只不過可編程性相當於增加競品的切換成本,效能提升相當於減少競品提供的增益價值。在接下來的歷代GPU架構回顧過程中,我們可以看到NV一以貫之地堅持踐行這個理念,不斷透過效能和可編程性(包括用於提升AI開發者生產效率的努力我也歸結為廣義的可編程性)的提升來強化自己產品相較於上代產品和競品的使用者增益價值。
任何事物都有其兩面性。所以,對可編程性的重視,也存在風險,可能成為制約NV發展的阿基里斯之踵。從Google在2016年推出TPU開始(從開創AI DSA硬件先河的角度,引爆這一撥AI硬件技術演進大趨勢的寒武紀也成立於2016年),行業裏湧現出大量的AI芯片 start-up,僅從硬件層面AI絕對算力來說,這些公司裏已經出現了和NV當前主流產品效能on-par的產品,如果從performance per watt的角度來看,也已經出現了超過NV的若幹競品。其核心原因也跟NV需要關註可編程性和歷史使用者習慣的包袱有關,而新興公司沒有積累也同樣沒有包袱,所以可以在架構設計的空間裏以適當犧牲通用可編程性為代價來尋找更適合於挖掘AI計算效率的設計權衡點。相關原理在【創新者的窘境】裏也有提到,這也是考驗某個領域裏頭部企業的地方了。
回歸正題。Fermi相較前兩代架構,引入了比較大的架構變化:
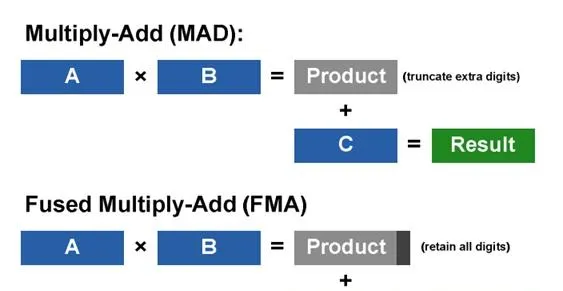
從AI系統的角度,NV在Fermi這一代並沒有為AI計算場景進行任何針對性的設計,包括 硬件和軟件。其被套用在AlexNet上也更像是一個機緣巧合: Alex這樣的演算法科學家因為實際演算法需求,在為釘子找錘子的過程中,發現GPU相較CPU更適合解決相關問題從而將其作為錘子引入進來。整個過程中NV的作用是相對passive的 。這和當前NV在AI計算領域的主動和激進存在著巨大的差異。
而在當時那個年代,為什麽是NV GPU被選中作為錘子,而不是Intel CPU或AMD GPU?
讓我們穿越過歷史的故紙堆,試圖做一些推測。
在2006年的這篇文章裏,我們能夠看到基於論文裏的實驗對比,Intel CPU上開啟BLAS庫,和NV GPU上的效能在on-par的水準,當時這個工作裏並沒有使用到CUDA,因為當年正是CUDA的元年。
有趣的是在這篇文章的註腳裏提到了除了在NVIDIA GeForce 7800 Ultra, Intel Pentium 4上的效能實驗之外,也準備加入ATI Radeon X1900上的實驗結果。在2005年更早的一篇文章裏,能夠看到在CPU, ATI GPU, NV GPU上同時進行MLP加速實驗對比的一些數據,看起來當時還有互有千秋。
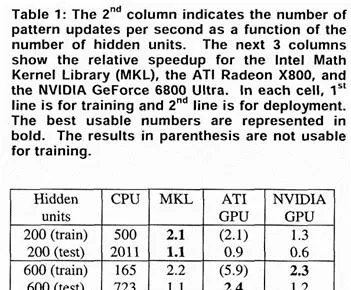
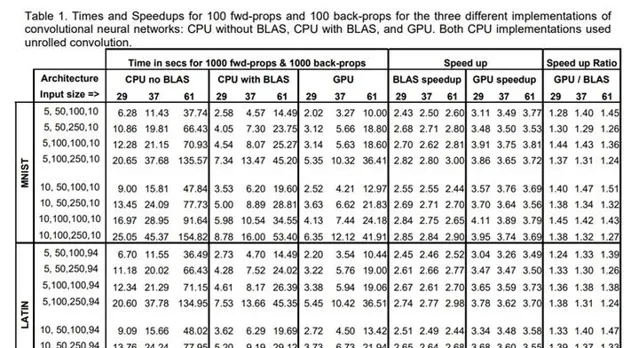
而在2011年的這篇文章裏,基於CUDA實作的摺積操作,效能最多已經達到了Intel CPU上的60倍。當時使用的硬件是Intel Core i7-920(2.66GHZ)以及基於Fermi架構的GTX480/GTX580顯卡。年代久遠,實測評估已經不太現實,不過,從多個途徑的數據cross check的結果(這裏,這裏,還有這裏)來看,i7-920 2.66GHZ的峰值算力大體在在 24~100GFlops 之間。關於i7-920的理論峰值算力, @李少俠 給出了一個比較專業的預估,我直接援引如下
nehalem cpu 只有 port0 的 sse 支持 FP32 乘法,port1 的 sse 只支持 FP32 加法,所以對於深度學習裏典型的乘法加法 1:1 的場景,i7-920 理論算力是 4-way*4core*2(FP add + mul ILP)*sse_freq,sse_freq 取 2.66G,那麽算力約 85Gflops,不過官方並沒有公布sse密集情況下的多核頻率,應該和這個數接近。這個數碼和這裏的一個推算基本是相當的。所以從客觀公平性角度,不妨將i7-920的峰值算力按 85Gflops 來設定。而GTX580的峰值算力是 1.5TFlops ,大體是1個數量級的差異。再加上CUDA提供的可編程性,以及Fermi引入的提升軟件開發人員效率的一些硬件feature(比如L2的引入),在2011年,NV GPU相較Intel CPU已經取得了在神經網絡加速場景比較明顯的優勢了。結合文章裏的這一段話,對於Fermi加入L2,並且在後續代際持續提升L2的容量的動作,就更容易有共鳴了。
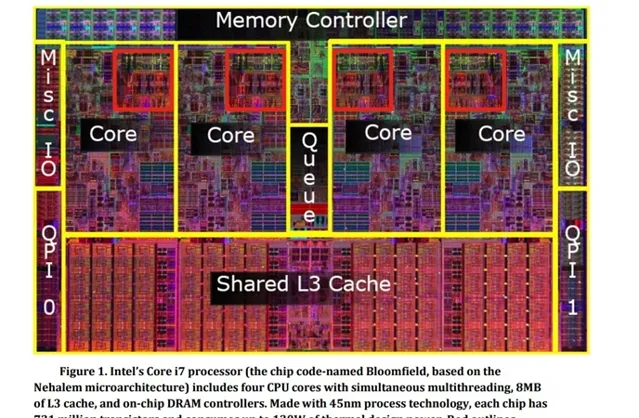
The latest generation of NVIDIA GPUs, the 400 and 500 series (we use GTX 480 & GTX 580), has many advantages over older GPUs, most notably the presence of a R/W L2 global cache for device memory. This permits faster programs and simplifies writing the code. In fact, the corresponding transfer of complexity into hardware alleviates many software and optimization problems. Our experiments show that the CNN program becomes 2-3 times faster just by switching from GTX 285 to GTX 480. Manual optimization of CUDA code is very time-consuming and error prone. We optimize for the new architecture, relying on the L2 cache for many of the device memory accesses, instead of manually writing code that uses textures and shared memory. Code obtained by this pragmatic strategy is fast enough. We use the following types of optimization: pre-computed expressions, unrolled loops within template kernels, strided matrices to obtain coalesced memory accesses and registers wherever possible. Additional manual optimizations are possible in case future image classification problems will require even more computing power.需要指出的是,上面的對比,並沒有做到完全基於第一性原理的公平性,比如Intel Core i7-920的工藝是 45nm ,而GTX580是 40nm ,整合的晶體管數量也存在明顯的差異( 30B v.s. 0.731B )。不過考慮到i7-920的架構設計中,只有不到20%的芯片面積用於實際計算,參見下圖(原圖 來源於Fermi的whitepaper),已經可以認為論文裏的效能差異是由GPU和CPU在架構設計權衡的定性差異所帶來的,所以我們不再花費精力進行更精細的定量對比。
總的來說,在Fermi這一代,NV GPU雖然沒有為AI計算場景進行特殊的客製,但因為其相異於CPU的設計理念使得其更適配於神經網絡的平行計算特性,再加上CUDA和硬件層面改善可編程性的一系列努力,使得其「誤打誤撞」地契合了AlexNet的建模需求,在深度學習的第一個killer application上取得了不錯的開局。
2. Kepler
Kepler架構在2012推出。這一代並沒有引入多少AI計算相關的架構創新,更多是一些偏通用性質的架構改進,包括 :
關於Kepler時代的架構變化細節,可以參見這篇whitepaper以及GTX680的whitepaper,在此不再做資訊搬運。
Kepler時代,NV在軟件層面引入了針對AI計算場景的一個大的動作---cuDNN V1.0在2014年的釋出,並整合進了Caffe等深度學習框架中。考慮到硬件叠代的成本,其發展通常會滯後於軟件發展,所以2014年cuDNN的釋出標誌著深度學習已經進入了NV的視野,透過軟件庫的叠代加深對深度學習計算負載的理解,為後續硬件架構的演進提供資訊反饋,大體可以推測是這個思路。而2016年Pascal架構的釋出,也基本上佐證了這點。
在Kepler時代,生態方面有幾個有代表性的事件:
阿裏巴巴初具規模采購NV GPU,也是從Kepler時代開始的。騰訊使用GPU進行語音辨識加速,也始於Kepler時代。百度使用GPU的歷史則更為悠久一些,我不確定是不是在Kepler之前就開始在使用GPU了,有熟悉這段歷史的朋友歡迎提供線索。
3. Maxwell
Maxwell架構在2014年被推出。和上一代Kepler架構相同,采用的也是28nm工藝。相同工藝,通常意味著可供騰挪的硬件晶體管資源數量不會有顯著的上升,留給架構師的設計空間相對有限。不過在Maxwell時代,因為28nm工藝成熟度的改進,加上從前代產品叠代中學習到的經驗,Maxwell仍然引入了一些比較出彩的變化:
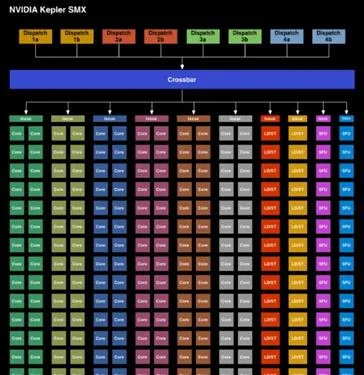
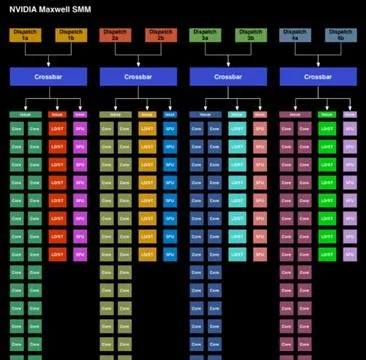
在這裏可以了解到更多Maxwell的架構細節。
Maxwell這一代,架構上也和Kepler和Fermi一樣,並沒有引入針對AI計算場景的特化考慮。
軟件層面,在14年cuDNN V1.0推出以後,進行了持續的叠代,2015年3月釋出了V2,2015年9月釋出了V3,2016年2月釋出了cuDNN V4,2016年3月伴隨P100釋出了cuDNN V5(cuDNN的發展過程中值得一提的是Scott Gray,這位兄台人不在NV,但透過逆向工程手寫了Maxwell架構上的SASS assembler,並首次基於winograd實作了快速conv演算法,最終這個作法被cuDNN團隊吸納入正式產品中),同時在V5版本也加入了對RNN/LSTM結構的最佳化支持,雖然現在RNN/LSTM結構的使用已經顯得勢微,但是在當時,對於機器轉譯,語言模型等NLP場景(以及涉及序列建模的OCR及語音辨識場景),RNN/LSTM實際上是當時的SOTA了,如果我們結合一些領域工作發表的時間做一下關聯,會發現NV對RNN/LSTM的支持跟這些工作發表的時間距離非常之近,這從一個側面體現出NV對於AI計算workload演化趨勢跟進之緊密。同時這段時間湧現了一些具備killer application內容的深度學習模型,比如微軟在2015年推出的ResNet。我沒能在公開文獻中檢索到ResNet論文發表時所使用的具體GPU型號,不過按時間推算,應該使用的是Kepler或Maxwell架構的GPU。
Maxwell時代,行業生態層面有幾件重要的事情發生:
回過頭來審視,站在2016年Pascal推出的前夜,會有一種「山雨欲來風滿樓」的感覺,於是就有了Pascal架構的釋出。
4. Pascal
Pascal架構在2016年3月被推出,采用16nm和14nm的工藝,說其是NV面向AI計算場景釋出的第一版架構,當不為過。在Pascal架構裏引入了面向AI場景很重要的一些特性:
阿裏大約是在2018年上線了具備NVLink的生產集群,而要到2019年才有比較多生產作業啟用NVLink進行單機 多卡加速,距離NVLink架構特性的推出大約有近三年的時間差,可以參見這裏的一些分析描述。
NVLink的技術細節簡要來說可以分為NVHS,Sub-link,Link,Gang四個層次。一條NVHS的link提供單向20Gb/s的傳輸頻寬頻寬,8根NVHS構成一個Sub-link,兩條Sub-links組成一條用於雙向連線的Link,P100架構下的單機八卡配置,不同GPU之間會由四個Link組成一條Gang,所以Gang的雙向匯總頻寬是 20Gb * 8 * 2 * 4 = 160GB/s ,單向匯總頻寬80GB/s,是PCIe提供頻寬的 5x 。更形象一些的示意圖如下:

在SM架構層面,Pascal引入的變化不算多。在我的理解中,更多是工藝提升帶來更多可用晶體管資源以後,可以把更多料堆起來反映到SM的數量提升,屬於增量式的變化。 從這一點也其實體現出NVIDIA從Fermi時代起結合CUDA所選擇的計算架構的優越性----幾乎每一代新架構(特別是SM相關)都能夠以相對增量的方式將工藝提升帶來的新增晶體管資源利用起來,而不是動輒引入大的架構調整。
在Pascal whitepaper裏提及的將CPU和GPU進行統一記憶體存取的特性,我自己的經驗,並沒有感覺到這個特性對於AI計算領域提供了多少實際收益。記得在剛剛拿到P100以後,我們評測過其page migration engine的表現,當時的結論非常negative。我們當時的判斷是想使用CPU記憶體來作為GPU視訊記憶體的backup,並且保證效能下滑不要太明顯,還是需要在AI框架層結合套用作業的特點來進行處理,而不是直接交給page migration engine來在後台自動完成。
在Pascal時代,另一個值得一提的是,能夠看到NV在從芯片向整機系統邁進,在其whitepaper裏提到了單機8卡的DGX-1 server,這也是從Fermi時代開始,第一次在whitepaper裏出現單GPU之上整機的方案。考慮到DGX-1的成本,在大量生產環境布署的其實是參考DGX-1代工生產的類似GPU伺服器機型。
軟件層面,Pascal這一代針對AI場景也引入了更多變化,首先是面向推理加速場景的TensorRT的釋出,然後是NCCL在2016年的釋出。說到這裏,我一直很好奇NCCL以開源形式存在至今(多機部份初始是以閉源形式提供,後來在框架自行提供多機通訊庫的壓力下推動了NCCL多機通訊版本的開源),而TensorRT則一直保持閉源形態,是什麽導致這兩個產品存在這樣的差異?在NV的官方blog上提到NCCL最早是一個research project,而TensorRT的源起則並不是一個research project,所以可能在對外開放度上NCCL尺度會更大。不過從生態建設的角度,hindsight地來看,如果TensorRT在起步的時候,就考慮按一個開源專案的方式來運作,不確定會不會帶來更快的叠代速度(如果叠代速度是一項重要的商業度量metrics)?這也是自己有時候會YY的問題之一-------如果有一款全新硬件,需要為其規劃AI軟件棧的技術路線的話,NV的哪些作法是應該借鑒的,哪些是應該改良的?
行業生態方面,有幾個很有意義的事件
5. Volta
在距離Pascal架構推出僅過去一年之後,2017年5月的GTC keynote,NV宣布了下一代Volta架構的釋出。考慮到Pascal代際引入了較大的架構升級,間隔這麽短又釋出了下一代的Volta架構,這並不是一個常規行為,實際上是源於Google TPU當時給NV帶來的壓力。在Volta之前,面向AI計算場景,NV GPU相較TPU其實是存在技術上的代際差異的,這就嚴重威脅到了NV在AI計算領域的地位。如果技術上不能及時拉平代際差異,僅靠CUDA生態建立的使用者切換成本來進行對抗,很可能會出現【創新者的窘境】裏的狀況,被顛覆性的技術拉下馬來。這個技術代際差異在Volta架構透過引入第一代TensorCore在訓練場景進行了拉平,隨後Turing架構的第二代TensorCore在推理場景上進行了拉平,直到Ampere時代,NV才算再次鞏固了自己在AI計算領域的龍頭地位。時隔四年,回顧這一段行業歷史,還是感覺精彩之至。比如,為什麽選擇了先支持FP16,而不是Google提及的BF16?為什麽考慮選擇了4x4尺寸的TensorCore,而不是更大的尺寸?如何figure out出來和FP16配套的Loss scaling的訓練策略?TensorCore的編程API如何對外暴露來盡量避免和現有CUDA體系形成撕裂?怎樣讓NV之外的開發者也具備在TensorCore上開發程式的能力?這裏涉及到了大量的技術、非技術因素的綜合權衡。一些結論決策,當時看是合理的,但現在來看,已經被推翻或叠代更新了。比如從最早支持FP16,到支持BF16,及至引入TF32。從4x4尺寸,到更大的8x8。CUDA層面暴露的API粒度也在發生演進變化。如此等等。這裏重要的不是結論,而是探討這些結論產生的過程。因為這些過程,是可以遷移到下一撥workload,下一撥架構創新機會上的,具體的結論則很可能未必。
Volta時代架構層面幾個重要變化是
硬件層面,Volta時代的Tensor Core提供了單cycle完成4x4x4=64條半精度FMA計算操作的的能力,在計算能力提升的同時,因為原先由64條FP32指令完成的操作現在由一條TensorCore指令完成,也省掉了大量用於保存中間計算結果的寄存器資源消耗,提升了數據復用性。
Volta的每個SM內部除了跟Pascal時代一樣的64個FP32/32個FP64/64個INT CUDA core以外,還提供了8個Tensor Cores。FP32 CUDA core和Tensor Cores數量差距如此之大,再加上Tensor Core對數據存取的需求和FP32 CUDA core存在明顯的差異,如何將Tensor Core計算能力對CUDA軟件開發人員暴露成為一個蠻考究的問題。從Volta架構開始,PTX指令中引入了Warp level的矩陣計算及存取指令,並不斷擴充套件其靈活性,從只能使用wmma.load/wmma.store/wmma.mma按ISA約束的數據組織方式來進行存取,到使用mma指令由軟件開發人員根據需要進行顯式的數據組織排布(靈活性提升的同時也意味著編程復雜性的增加)。以及為了簡化NV之外CUDA開發人員使用TensorCore的負擔所推出的CUTLASS軟件庫。TensorCore編程復雜性的根源在於
總的來說,Volta時代的TensorCore在技術原理上幫助NV拉平了和Google在AI計算領域的技術代差,但是現在回頭來看仍然存在比較多的局限性,包括 :
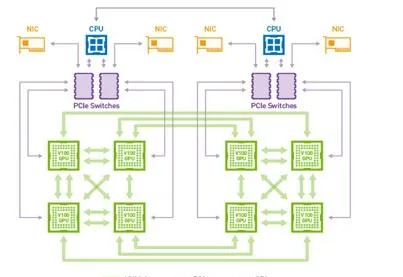
在Volta時代,深度學習模型層面也出現了一些新的變化,這些變化主要集中在自然語言處理領域。首先是2017年Transformer模型結構在機器轉譯場景取得的效果突破,使得其開始替換之前SOTA的RNN/LSTM結構,被大量采用。然後是2018年BERT的出現,在展現其出色的預訓練模型效果的同時,也給使用NV GPU預訓練BERT帶來了比較大的挑戰和壓力。NV對此的應對是迅速推出了32G視訊記憶體的V100卡型,並在設計針對訓練場景的下一代GPU架構時對視訊記憶體容量給予了更高權重。另一個標誌性的事件是2020年OpenAI對外公布其在微軟提供的V100集群上完成了包含175B參數的GPT-3模型的訓練過程。一個有意思但無從考證的坊間傳言是,BERT的核心開發者之前在微軟工作,在加入Google後,借助Google提供的軟硬結合的AI算力,在比較短的時間內推出了BERT,微軟的高層決策者收到這個反饋之後,投入了一大筆錢購買了DGX的伺服器:)。
軟件層面,NV在2017年底釋出了CUTLASS,為NV之外的開發者開發TensorCore程式提供了一個比較好的參考基礎。2018年Q3以開原始碼的形式釋出了跨結點的NCCL通訊庫(這裏的一個背景是,NCCL 1.X 一直是開源的,2.0 加入了多機分布式支持之後一度閉源了一年左右,後續框架開始自行支持 AllReduce on RDMA的壓力倒推NV最終將NCCL 2.0開源,最終成為多卡通訊的事實標準),並在當年釋出了TensorRT Inference Server(之後被更名為Triton Inference Server)。2018年NV為TensorFlow加入了TF-TRT的支持(還記得在NV推出這個工作之前,當時我還在阿裏,我的同事易凡同學因為支持業務的需要,正好也完成了一個類似工作的原型,看到NV釋出了撞車的tf-trt以後,感覺也是比較微妙),顯著提升了基於TensorFlow使用TRT布署能力的易用性。單器材最佳化之外,繼續向AI系統全鏈路滲透。
另外值得一提的是在V100時代,大模型訓練的需求變得更加旺盛。在V100之前的時代,大模型訓練場景主要包括三類:一類是大規模人臉分類,因為其會有一個巨大的全連線分類層需要進行模型並列;一類是ResNet101這種極深類別的模型,需要引入類似pipeline並列的作法;還有一種就是大規模稀疏搜推廣模型,透過將大規模embedding table分片存放解決。從V100之後,我們會發現大模型訓練所需要的技術核心點其實並沒有變化,只不過場景更多以NLP為主。其推手當屬BERT和GPT-3這兩大killer application性質的模型。2019年,NV對外釋出了支持Megatron-LM的工作,這也是Megatron-LM的第一次對外亮相,當時的工作基於32GB V100 GPU來完成,並且只支持Tensor Parallelism,不支持Pipeline Parallelism。與此同時,也已經能夠看到業界有更多圍繞大模型訓練相關的工作,比較有代表性的當屬微軟DeepSpeed團隊的工作,這支團隊透過引入精細的視訊記憶體最佳化技術從另一條技術路徑對大模型訓練進行探索,這個工作也是以V100 GPU為主要硬件平台來完成的。其他相關工作包括微軟的PipeDream(在NV GPU上完成),Google的GPipe(同時使用了NV GPU和TPU作為硬件平台)等。這篇回顧文章的重點不是討論分布式訓練技術,所以不再展開更多相關細節,這裏的關鍵是,這些大模型訓練工作背後的支撐硬件,幾乎清一色以NV GPU為主,以及若幹Google發起的工作基於TPU來完成。
另一個值得一提的是,MLPerf training 0.5在2018年12月份結果的釋出,從此MLPerf training先後歷經0.5、0.6、0.7、1.0、1.1五個版本的叠代(MLPerf inference歷經0.5、0.7、1.0、1.1四個版本叠代)。叠代過程中,因為有了清晰的最佳化標的,NV得以資源聚集,整套軟硬技術全棧也經歷了巨大的變化飛躍。雖然MLPerf裏的不少最佳化結果並不能直接遷移到生產環境裏(參考這裏的一些討論),但其對於行業技術進步的促進作用還是毋庸置疑的。
在V100時代,隨著Tensor Core對Conv/GEMM這類計算密集算子帶來顯著加速,訪存密集算子以及kernel launch開銷對端到端效能的影響變得也越來越大,也是從V100時代開始,自動算子融合技術開始受到更多關註。在這方面,Google XLA應該是最早進行相關探索的團隊。Google在為TPU設計XLA編譯器的過程中,發現裏面的一些技術對於GPU和CPU也同樣能夠帶來收益,於是將XLA也使能到了GPU上(XLA CPU的投入一直乏善可陳,在此不提)。時至今日,無論是NV GPU還是新興的AI芯片公司,算子融合技術已經是一項must了。
6. Turing
Turing架構在2018年9月的SIGGRAPH正式釋出。和Volta相同,Turing也基於TSMC 12nm工藝完成生產。從AI計算的角度,Turing主要面向推理場景,相較Volta其架構上的變化主要有:
7. Ampere
Ampere架構在2020年5月釋出。這一代架構引入了比較多的變化:

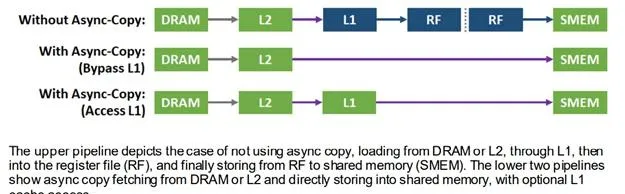
更多細節可以參考這裏的whitepaper。
在Ampere時代,NV在整機之外,進一步推出集群解決方案SuperPOD,以及基於SuperPOD搭建的超算集群Selene,SuperPOD和Selene支持了Megatron-LM以及MLPerf training的大量效能最佳化工作,也作為解決方案,成功交付給了若幹客戶。這也是一個蠻有意思的行業訊號。
軟件方面,Ampere時代一個比較重要的工作是TensorRT和PyTorch的整合Torch-TensorRT,不過這個工作仍然面臨一個大的挑戰,那就是PyTorch的模型寫法過於靈活,存在不少無法成功匯出TorchScript的模型寫法(比如NLP場景中decoding部份的迴圈生成結構),對於這部份如何進行高效自動推理加速,目前仍然是一個open的問題。
另一個NV GPU上軟件相關有代表性的工作是對dynamic shape的支持,關於有效處理dynamic shape,大約從三年前業界就有過過呼聲。TensorRT目前仍然是透過padding的策略來解決dynamic shape的問題。阿裏在兩個月前開源的BladeDISC是一個基於MLIR針對dynamic shape提供的E2E的AI編譯解決方案,不過完備性還有待完善。Amazon的Nimble工作則基於TVM技術棧探索了另一條解決dynamic shape的技術方案。
無論是Torch-TensorRT,還是對dynamic shape的支持,都反映出對AI開箱即用效能最佳化的重視,這在一定程度上,也和AI當前更多進入到行業套用落地期的階段有關。
模型方面,Ampere自2020年推出以後,直到現在,能夠看到AI領域主要的關註焦點集中在大模型訓練上,除了GPT-3,BERT類模型以外,MoE模型也受到了一定關註,相應地也催生了一系列工作,包括Google TPU之上的Gshard系列工作,GPU上的DeepSpeed-MoE工作等。但是大模型到底能夠為業務層面帶來多少實際收益,其收益是否足以justify新增的算力投入,是否需要更高效環保的模型設計方法以及AI算力提供方案,目前仍然是一個open的問題。
以上結合AI系統演進的視角,回顧了從Fermi到Ampere共7代架構,期望隨著未來Ampere-Next以及Ampere-Next-Next的釋出,我們可以再添加入相關的內容,一起經歷見證AI系統領域和NV GPU架構的共同演進發展。
這篇回顧涉及到了比較長的時間跨度,比較寬的技術區域,整個回顧內容,有些是我親身經歷的,有些是我基於獲取到的一手或二手資訊提煉的,還有一些則是根據網絡上的資訊進行交叉校驗後匯總出來的,難免會有疏漏或不夠準確之處,也歡迎同行朋友的批評指正。
文章撰寫過程中感謝一些朋友指出其中錯誤以及提供建議,包括 :











