時間序列預測是一個重要的領域,這裏介紹最新的M5 Accuracy Competition的總結分析。
M competitions
M Competitions迄今共舉辦了5界,主要目的是透過真實數據評估現有演算法和最新演算法。比賽相關文章主要發表在International Journal of Forecasting雜誌上。
數據集
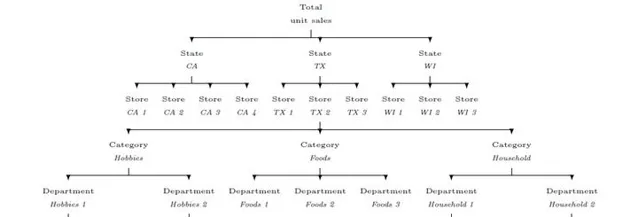
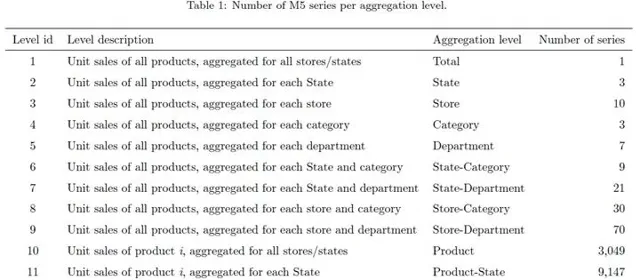
M5 Accuracy Competition數據集來自於沃爾瑪的三個州,共涉及10個門店、3大類商品、3049個產品,總共42840條時間序列。
時間序列根據物件類別等級的不同,可以細分成12個層級。
時間序列數據從2011-01-29到2016-06-19,約5年半的天粒度數據,預測任務是未來28天的銷量。
除了基礎的天粒度銷量數據外,還有額外的輔助資訊,如行事曆資訊、價格資訊、節假日資訊、促銷資訊。
Baseline
Baseline演算法包括Naive演算法、sNaive演算法、Exponential Smoothing演算法等。
在基準演算法中,Exponential Smoothing演算法的預測效能最好。
Results
演算法最佳化的提升天花板
相比Exponential Smoothing基準演算法,Winner演算法的預測效能提升了 22.4% ,而在M3和M4中,Winner演算法的預測效能提升不到10%
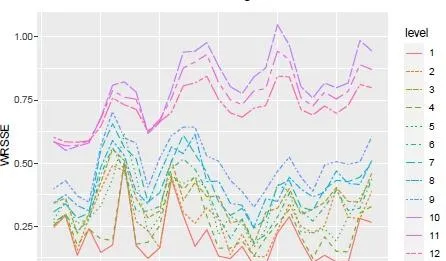
粒度越細,預測誤差越大,預測效能的提升越少:最粗粒度的預測提升達40%,而最細粒度的預測提升僅3%
exogenous/explanatory variables可以提升預測效能:ESX演算法相比ES演算法,效能提升了6%,ARIMAX演算法相比ARIMA演算法,效能提升了13%
時間序列預測任務中,相比基準演算法,可提升的空間約在3%~20%之間
尺有所短,寸有所長( Horses For Courses )
Winner演算法並未在所有level上都取得最佳效能
預測效能的天花板與數據的粒度有關、與行事曆有關(工作日、周末等)
Top演算法解決方案的特點
機器學習/深度學習演算法,其中lightGBM是利器
整合預測,多種演算法的整合(如算術平均等)
充分利用exogenous/explanatory variables
Cross-learning提升對序列之間的資訊的利用能力
交叉驗證(CV)可以提高演算法的魯棒性,指導演算法策略的選擇。在Winner解決方案中,透過交叉驗證發現recursive model的整體準確率要高於non-recursive model。
The bene cial effect of external adjustments(未理解)
參考文獻
- The M5 Accuracy competition: Results, findings and conclusions
![[表皮永生] 996違法,表皮幹細胞也需要休息](http://img.jasve.com/2024-2/3e9ab2f59687e990984c214c63554720.webp)










