前段時間騰訊的 AI 「絕藝」 在野狐圍棋越殺越勇,勝率接近90%,戰績一片紅色,充分展示了強化學習自我前進演化的威力。但就在2月10日畫風突變,被幾位棋手連殺幾局,隨後就下線調整去了:
細看棋譜,職業棋手很有想法,確實找到了電腦的一個比較本質的缺陷。例如這盤,電腦持白,對持黑的潛伏(柯潔九段):
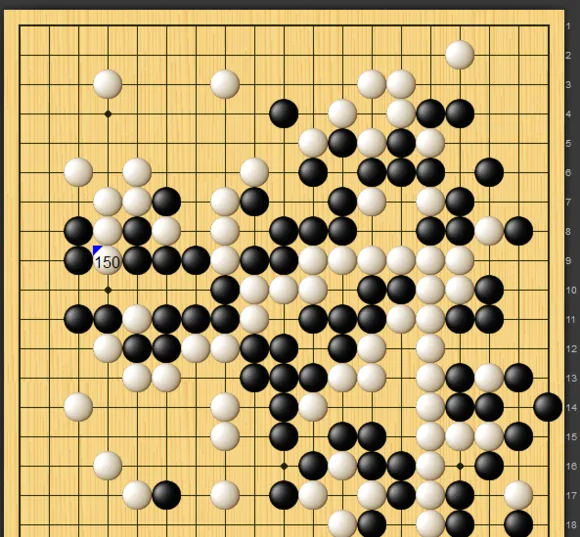 白棋的大龍從右下被黑棋緊盯著殺到中腹,最後竟然做不出兩眼,郁郁而亡。其余幾盤也均是以電腦大龍被殺告終。
白棋的大龍從右下被黑棋緊盯著殺到中腹,最後竟然做不出兩眼,郁郁而亡。其余幾盤也均是以電腦大龍被殺告終。
這是深度摺積網絡的一個 BUG: 電腦對於局部的死活很敏感,但是對於大龍的死活不一定看得清。 最近我在訓練網絡時也發現,深度摺積網絡 在此有一個"資訊傳遞困難癥"。這首先有兩個原因:
第一,AlphaGo v13 的網絡層數實際是不夠的。如果按照 AlphaGo v13 的架構,5x5往上面長11層3x3,相當於27x27,看上去夠大了吧? 錯,這樣的半徑只有14。因此,如果大龍的長或寬超出14,那麽它的尾就和頭沒有任何直接聯系了 。實際上,摺積核 要至少長到37x37才保險,也就是16層3x3才夠。
第二,由於網絡的結構是往上一層層生長,如果只長幾層,一般不會遺失重要資訊,但如果一直長上去,就會越來越容易出現問題。所以,
大龍甚至都不用長到14,電腦就已經不一定"知道"自己的大龍是一條聯通的大龍了。
舉個與之相關的例子:按照 AlphaGo v13 的架構,如果大龍只在一端有兩個真眼,另一端就甚至不一定知道自己已經活了(它只會知道自己有兩口氣,而這是網絡輸入告訴它的)...... 不可思議吧,我自己訓練時看到這個現象也很驚訝,然後一想確實是這樣。
以上這兩個問題,電腦換成足夠深的殘留誤差網絡
或許就可以基本解決,不過意味著要重新訓練。
但實際還有兩個問題:
第三,如果仔細看網絡本身輸入的特征設計 ,會發現網絡容易被帶入一個誤區: 它會傾向於認為氣很多的棋塊就是活的。 對於局部死活,這沒有問題,但對於大龍死活,這是不足夠的。 網絡實際並沒有清晰的眼位概念。
第四,這裏的局面在人人對局中少見,在電腦自我對局中也會同樣少見。關鍵在於,棋塊小的時候,可能出現的形狀不多,而且許多形狀經常在對局中出現,因此容易被神經網絡學會。而大龍越大,其可能出現的形狀就越多,網絡不一定能學會。事實上,目前的深度摺積網絡並不擅長學會拓撲概念。 細長的大龍、分叉的大龍、卷曲的大龍,會尤其是它的弱點。棋手可以多嘗試讓電腦或自己的棋變成這樣,電腦就會更容易看不清死活。
以上兩個問題,電腦也可以透過有針對性的訓練改善自己。具體效果如何,我們看「絕藝」上線後的表現。
順便一提,如果讀者對於 AlphaGo 與圍棋 AI 感興趣,我正在寫一個系列,其它幾篇的傳送門 :











