 Paul Graham 在其著作 <黑客與畫家> 中斷言:「不同語言的執行效率差距正變得越來越大,所以效能分析器(profiler)將變得越來越重要。目前,效能分析並沒有受到重視。許多人好像仍然相信,程式執行速度提升的關鍵在於開發出能夠生成更快速程式碼的編譯器。程式碼效率與機器效能的差距正在不斷加大,我們將會越來越清楚地看到,套用軟件執行速度提升的關鍵在於有一個好的效能分析器幫助指導程式開發。」 by Paul Graham 黑客與畫家
Paul Graham 在其著作 <黑客與畫家> 中斷言:「不同語言的執行效率差距正變得越來越大,所以效能分析器(profiler)將變得越來越重要。目前,效能分析並沒有受到重視。許多人好像仍然相信,程式執行速度提升的關鍵在於開發出能夠生成更快速程式碼的編譯器。程式碼效率與機器效能的差距正在不斷加大,我們將會越來越清楚地看到,套用軟件執行速度提升的關鍵在於有一個好的效能分析器幫助指導程式開發。」 by Paul Graham 黑客與畫家
0 序言
谷歌搜尋 「Android 最佳化工具」,你會找到很多與此相關的內容。他們的問題在於要麽是內容高度重復、要麽是直接講使用方法,很少會給你介紹整體性的架構,一不小心就會讓人會種「一個工具搞定一切」的錯誤認知。以筆者團隊的多年經驗來看,在效能分析領域這種銀彈級別的工具是不存在的。工具在發展,老問題會以新的方式變樣出現,不掌握核心邏輯的話始終會讓你浮於技術的表面。
本文首先系統性的梳理效能分析中的可觀測性技術,它涵蓋數據類別、抓取方法以及分析方法等三部份內容,之後是介紹谷歌提供的「三大件」分析工具。目的是想讓你了解不變的理論性的知識,以及與之對應的在安卓環境中可用的工具,這些可以讓你少走一些彎路,直接復用前輩們的經驗。
需要特別說明的是,對於效能最佳化肯定不止有這三個工具可用,但這個三個工具是我們平時用到的「第一手工具」。進行進一步分析之前,你都需要依賴這三個工具進行瓶頸定位,之後才應不同領域特性選擇對應的工具進行下鉆分析。
1 效能分析中的可觀測性技術
相信你不止一次被同事、被老板問到過類似的問題。最原始的想法應該是,首先是拿到相關的日誌進行逐個分析。根據以往經驗,透過尋找關鍵字尋找蛛絲馬跡。如果沒有想看的資訊,那就加上日誌嘗試本地復現。費時費力不說,也還費研發資源。但你有沒有想過行業裏有沒有更高效的方法?可以提高一個數量級的那種,把我們的時間花在問題解決上而不是無聊的重復性體力活兒上?
答案當然是有的(否則就不會有這篇文章了),我們稱他為可觀測性技術。
電腦行業發展至今,電腦前輩們搗鼓出了所謂的「可觀測性技術」的類別。它研究的是透過工具,來觀測復雜系統的執行細節,內容越細越好。 流動作業系統之前是由嵌入式發展而來的,現在的中高端安卓手機算力都能趕得上二十幾年前的一個主機的算力,在此算力基礎上所帶來的軟件復雜度也是非常巨大的。
如果你的程式部署了一個精心設計且執行良好的可觀測性技術,可以大大加快研發軟件的效率,因為即使我們使用了各種各樣的前置性靜態程式碼檢測、人工程式碼審查,也無法 100% 攔截軟件的問題。只有在真實環境裏執行之後才知道是否真正發生了問題,即使這個環境可能是一個你的自動化測試用例。即使這樣,你還需要翻閱你的日誌,重讀程式碼來找出問題。出於這些原因,每個工程團隊都需要有一個功能完備的可觀測性工具作為他們的基礎設施之一。
可觀測性技術是一個系統性工程,它能夠讓你更深入的了解軟件裏發生的事情。可用於了解軟件系統內部執行過程(特別是對於業務邏輯或者互動關系復雜的系統)、排查問題甚至透過尋找瓶頸點最佳化程式本身。對於復雜的系統來說,你透過閱讀程式碼來了解整個執行過程其實是很困難的事情,更高效的方法就是借助此類工具,以最直觀的的方式獲取軟件執行的狀態。
下面將從 數據類別、數據獲取方法、分析方法 這三個主題來幫助你了解可觀測性技術。
1.1 數據類別
日誌的形式可能是鍵值對(key=Value),JSON、CSV,關系型數據庫或者其他任何格式。其次我們透過日誌還原出系統當時執行的整個狀態,目的是為了解決某個問題,觀察某個模組的執行方式,甚至刻畫系統使用者的行為模式。在可觀測性技術上把日誌類別分類為 Log 類別、Metric 類別,以及 Trace 類別。

Log 類別
Log 是最樸素的數據記錄方式,一般記錄了什麽模組在幾點發生了什麽事情,日誌等級是警告還是錯誤。 絕大部份系統,不管是嵌入式器材還是汽車上的電腦,他們所使用的日誌形式幾乎都是這種形式。這是最簡單,最直接也最好實作的一種方式。幾乎所有的 Log 類別是透過 string 類別的方式儲存,數據呈現形式是一條一條的文本數據。Log 是最基本的類別,因此透過轉換,可以將 Log 類別轉換成 Metric 或者 Trace 類別,當然成本就是轉換的過程,當數據量非常巨大的時候這可能會成為瓶頸。
為了標識出不同的日誌類別等級,一般使用錯誤、警告、偵錯等級別來劃分日誌等級。顯然,錯誤類別的是你首要關註的日誌等級。不過實踐中也不會嚴格按照這種方式劃分,因為很多工程師不會嚴格區分他們之間的差異,這可能是他們的工程開發環境中不太會對不同等級的日誌進行分類分析有關。總之,你可以根據你的目的,將 Log 類別進行等級劃分,它就像一個索引一樣,可以進一步可以提高分析問題、定位目標資訊的效率。
Metric 類別
Metric 類別相比 Log 類別使用目的上更為聚焦,它記錄的是某個維度上數值的變化。知識點是「維度」與「數值」的變化。維度可能是 CPU 使用率、CPU Cluster 執行頻率,或者上下文切換次數。數值變化既可以是采樣時候的瞬時值(成為快照型)、與前一次采樣時的差值(增或減)、或者某個時段區間的統計聚合值。實踐中經常會使用統計值,比如我想看問題發生時刻前 5 分鐘的 CPU 平均使用量。這時候需要將這五分鐘內的所有數值做算數平均計算,或者是加權平均(如: 離案發點越近的樣本它的權重就越高)。Log 類別當然可以實作 Metric 類別的效果,但是操作起來非常麻煩而且其效能損耗可能也不小。
聚合是非常有用的工具,因為人不可能逐個分析所有的 Metric 值,因此借助聚合的方式判斷是否出了問題之後再進行詳細的分析是更為經濟高效的方法。
Metric 類別的另外一個好處是它的內容格式是比較固定的,因此可以透過預編碼的方式進行數據儲存,空間的利用率會更緊湊進而占用的磁盤空間就更少。最簡單的套用就是數據格式的儲存上,如果使用 Log 類別,一般采用的是 ASCII 編碼,而 Metric 使用的是整數或者浮點等固定 byte 數的數據,當儲存較大數值時顯然 ASCII 編碼需要的字節數會多於數碼型數據,並且在進行數據處理的時候你可以直接使用 Metric 數據,而不需要把 Log 的 ASCII 轉換成數碼型後再做轉換。
除了是具體的數值之外,也可以儲存列舉值(某種程度上它的本質就是數值)。不同的列舉值代表不同的意義,可能是開和關、可能是不同的事件類別。
Trace 類別
Trace 類別標識了事件發生的時間、名稱、耗時。多個事件透過關系,標識出了是父與子還是兄弟。當分析多個執行緒間復雜的呼叫關系時 Trace 類別是最方便的數據分析方式。
Trace 類別特別適用於 Android 套用與系統級的分析場景,因為用它可以診斷:
- 函數呼叫鏈
- Binder 呼叫時的呼叫鏈
- 跨行程事件流跟蹤
Android 的應用程式執行環境的設計中,一個應用程式是無法獨自完成所有的功能的,它需要跟 SystemServer 有大量的互動才能完成它的很多功能。與 SystemServer 間的通訊是透過 Binder 完成,它的通訊方式後面的文章再詳細介紹,到目前為止你只需要知道它的呼叫關系是跨行程呼叫即可。這需要本端與遠端的數據才能準確還原出呼叫關系,Trace 類別是完成這種資訊記錄的最佳方式。
Trace 類別可以由你手動添加開始與結束點,在一個函數裏可以添加多個這種區間。透過預編譯技術或者程式語言的特性,在函數的開頭與結尾裏自動插樁 Trace 區間。理想情況下後者是最好的方案,因為我們能知道系統中執行的所有的函數是哪些、執行情況與呼叫關系是什麽。可以拿這些資訊統計出呼叫次數最多(最熱點)的函數是什麽,最耗時的函數又是什麽。可想而知這種方法帶來的效能損耗非常大,因為函數呼叫的頻次跟量級是非常大的,越是復雜的系統量級就越大。
因此有一種迂回的方法,那就透過采樣獲取呼叫棧的方式近似擬合上面的效果。采樣間隔越短,就越能擬合真實的呼叫關系與耗時,但間隔也不能太小因為取堆疊的操作本身的負載就會變高因為次數變多了。這種方法,業界管他叫 Profiler,你所見過的絕大部份程式語言的 Profiler 工具都是基於這個原理實作的。
1.2 數據獲取方法

靜態程式碼與動態跟蹤
靜態程式碼的采集方式是最原始的方式,優點是實作簡單缺點是每次新增內容的時候需要重新編譯、安裝程式。當遇到問題之後你想看的資訊恰好沒有的話,就沒有任何辦法進一步定位問題,只能重新再來一遍整個過程。更進一步的做法是預先把所有可能需要的地方上加入數據獲取點,透過動態判斷開關的方式選擇是否輸出,這既可以控制影響效能又能夠在需要日誌的時候可以動態開啟,只不過這種方法的成本非常高。
動態跟蹤技術其實一直都存在,只是它的學習成本比較高,被譽為偵錯跟蹤領域裏的屠龍刀。它需要你懂比較底層的技術,特別是編譯、ELF 格式、內核、以及熟悉程式碼中的預設的探針、動態跟蹤所對應的程式語言。對,你沒看錯,這種技術甚至還有自己的一套程式語言用於「動態」的實作開發者需求。這種方式兼具效能、靈活性,甚至線上版本裏遇到異常後可以動態檢視你想看的資訊。
Android 套用開發、系統級開發中用的比較少,內核開發中偶爾會用一些。只有專業、專職的效能分析人員才可能會用上這類工具。它有兩個關鍵點,探針與動態語言,程式執行過程中需要有對應的探針點將程式執行許可權交接到動態跟蹤框架,框架執行的邏輯是開發者使用動態語言來編寫的邏輯。
所以,你的程式裏首先是要有探針,好在 Linux 內核等框架埋好了對應的探針點,但是 android 套用層是沒有現成的。所以目前 Android 上能用動態框架,如 eBPF 基本都是內核開發者在使用。
無條件式抓取與有條件式抓取
無條件式抓取比較好理解,觸發抓取之後不管發生任何事情,都會持續抓取數據。缺點是被觀測物件產生的數據量非常大的時候可能會對系統造成比較大的影響,這種時候只能透過降低數據量的方式來緩解。需要做到既能滿足需求,效能損失又不能太大。
有條件式抓取經常用在可以辨識出的異常的場景裏。比如當系統的某個觀測值超過了預先設定的閾值時,此時觸發抓取日誌並且持續一段時間或者達到另外一種閾值之後結束抓取。這相比於前面一個方法稍微進步了一些,僅在出問題的時候對系統有影響,其他時候沒有任何影響點。但它需要你能夠辨識出異常,並且這種異常是不需要異常發生之前的歷史數據。當然你可以透過降低閾值來更容易達到觸發點,這可能會提高觸發數據抓取的概率,這時候會遇到前面介紹的無條件式抓取遇到的同樣的問題,需要平衡效能損失。
落盤策略
持續落盤是儲存整個數據抓取過程中的所有數據,代價是儲存的壓力。如果能知道觸發點,比如能夠檢測到異常點,這時候可以選擇性的落盤。為了保證歷史數據的有效性,因此把日誌先暫儲存到 RingBuffer 中,只有接受到落盤指令後再進行落盤儲存。這種方式兼顧了效能與儲存壓力,但成本是執行時記憶體損耗與觸發器的準確性。
1.3 分析方式
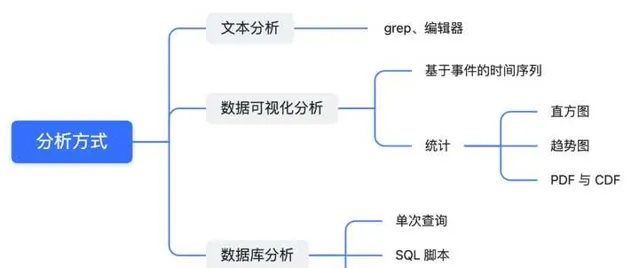
數據視覺化分析
隨著問題分析的復混成,出現了要解決多個模組間互動的效能問題需求,業界就出現了以時間為橫軸把對應事件放到各自泳道上的數據視覺化分析方法,可以方便的看到所關心事件什麽時候發生、與其他系統的互動資訊等等。在 Android 裏我們常用的 Systrace/Perfetto 以及更早之前的 KernelShark 等工具本質上都是這一類工具。在「數據類別」提到的 「Trace 類別」,經常采用這種視覺化分析方法。
Systrace 的視覺化框架是基於 Chrome 的一個叫 Catapult 的子專案構建。 Trace Event Format 講述了 Catapult 所支持的數據格式,如果你有 Trace 類別的數據,完全可以使用此框架來展示視覺化數據。AOSP 編譯系統,安卓套用的編譯過程,也都有相應的 Trace 檔輸出,它們也都基於 Catapult 實作了視覺化效果。
數據庫分析
面對大量數據分析的分析,透過對數據進行格式化,把他們轉換成二維數據表,借助 SQL 語言可實作高效的查詢操作。在伺服器領域中 ELK 等技術棧可以實作更為靈活的格式化搜尋與統計功能。借助數據庫與 Python,你甚至可以實作一套自動化數據診斷工具鏈。
從上面的討論可知,從文本分析到數據庫分析他們要面對的分析目的是不一樣的。單純的看一個模組的耗時用文本分析就夠用了,多個系統間的互動那就要用視覺化工具,復雜的數據庫分析就要用到 SQL 的工具。無論哪種分析方式,本質上都是針對數據的分析,在實戰中我們經常會透過其他工具對數據進行轉換以支持不同的分析方式,比如從文本分析方式改成數據庫分析方式。
根據自己的目的,選擇合適的分析方式才會讓你的工作事倍功半。
對於 Android 開發者來說,Google 提供了幾個非常重要的效能分析工具,幫助系統開發者、套用開發者來最佳化他們的程式。
2 谷歌提供的 Andorid 效能分析工具
從實踐經驗來看最常用的工具有 Systrace,Perfetto 與 Android Studio 中的 Profiler 工具。透過他們定位出主要瓶頸之後,你才需要用到其他領域相關工具。因此,會重點介紹這三個工具的套用場景,它的優點以及基本的使用方法。 工具之間的橫向對比,請參考下一個「綜合對比」這一章節的內容。
2.1 初代系統效能分析工具 - Systrace
Systrace 是 Trace 類別的視覺化分析工具,是第一代系統級效能分析工具。Trace 類別所支持的功能它都有支持。在 Perfetto 出現之前,基本上是唯一的效能分析工具,它將 Android 系統和 App 的執行資訊以圖形化的方式展示出來,與 Log 相比,Systrace 的影像化方式更為直觀;與 TraceView 相比,抓取 Systrace 時候的效能開銷基本可以忽略,最大程度地減少觀察者效應帶來的影響。

Systrace 的設計思路
在 系統的一些關鍵操作 (比如 Touch 操作、Power 按鈕、滑動操作等)、 系統機制 (input 分發、View 繪制、行程間通訊、行程管理機制等)、 軟硬件資訊 (CPU 頻率資訊、CPU 排程資訊、磁盤資訊、記憶體資訊等)的關鍵流程上,插入類似 Log 的資訊,我們稱之為 TracePoint(本質是 Ftrace 資訊),透過這些 TracePoint 來展示一個核心操作過程的執行時間、某些變量的值等資訊。然後 Android 系統把這些散布在各個行程中的 TracePoint 收集起來,寫入到一個檔中。匯出這個檔後,Systrace 透過解析這些 TracePoint 的資訊,得到一段時間內整個系統的執行資訊。

Android 系統中,一些重要的模組都已經預設插入了一些 TracePoint,透過 TraceTag 來分類,其中資訊來源如下
- Framework Java 層的 TracePoint 透過 android.os.Trace 類完成
- Framework Native 層的 TracePoint 透過 ATrace 宏完成
- App 開發者可以透過 android.os.Trace 類自訂 Trace
這樣 Systrace 就可以把 Android 上下層的所有資訊都收集起來併集中展示,對於 Android 開發者來說,Systrace 最大的作用就是把整個 Android 系統的執行狀態,從黑盒變成了白盒。全域性和視覺化使得 Systrace 成為 Android 開發者在分析復雜的效能問題的時候的首選。
實踐中的套用情況
解析後的 Systrace 由於有大量的系統資訊,天然適合分析 Android App 和 Android 系統的效能問題, Android 的 App 開發者、系統開發者、Kernel 開發者都可以使用 Systrace 來分析效能問題。
- 從技術角度來說,Systrace 可覆蓋效能涉及到的 響應速度 、 卡頓丟幀 、 ANR 這幾個大類。
- 從使用者角度來說,Systrace 可以分析使用者遇到的效能問題,包括但不限於:
- 套用啟動速度問題,包括冷啟動、熱啟動、溫啟動
- 界面跳轉速度慢、跳轉動畫卡頓
- 其他非跳轉的點選操作慢(開關、彈窗、長按、選擇等)
- 亮滅屏速度慢、開關機慢、解鎖慢、人臉辨識慢等
- 列表滑動卡頓
- 視窗動畫卡頓
- 界面載入卡頓
- 整機卡頓
- App 點選無響應、卡死閃退
在遇到上述問題後,可以使用多種方式抓取 Systrace ,將解析後的檔在 Chrome 開啟,然後就可以進行分析
2.2 新一代效能分析全棧工具 - Perfetto
谷歌在 2017 年開始了第一筆送出,隨後的 4 年(截止到 2021.12)內總共有 100 多位開發者送出了近 3.7W 筆送出,幾乎每天都有 PR 與 Merge 操作,是一個相當活躍的專案。 除了功能強大之外其野心也非常大,官網上號稱它是下一代面向可跨平台的 Trace/Metric 數據抓取與分析工具。套用也比較廣泛,除了 Perfetto 網站, Windows Performance Tool 與 Android Studio ,以及華為的 GraphicProfiler 也支持 Perfetto 數據的視覺化與分析。 我們相信谷歌還會持續投入資源到 Perfetto 專案,可以說它應該就是下一代效能分析工具了,會完全取代 Systrace。
提供的亮點功能
Perfetto 相比 Systrace 最大的改進是可以支持長時間數據抓取,這是得益於它有一個可在背景執行的服務,透過它實作了對收集上來的數據進行 Protobuf 的編碼並存盤。從數據來源來看,核心原理與 Systrace 是一致的,也都是基於 Linux 內核的 Ftrace 機制實作了使用者空間與內核空間關鍵事件的記錄(ATRACE、CPU 排程)。Systrace 提供的功能 Perfetto 都支持,由此才說 Systrace 最終會被 Perfetto 替代。

Perfetto 所支持的數據類別、獲取方法,以及分析方式上看也是前所未有的全面,它幾乎支持所有的類別與方法。數據類別上透過 ATRACE 實作了 Trace 類別支持,透過可客製的節點讀取機制實作了 Metric 類別的支持,在 UserDebug 版本上透過獲取 Logd 數據實作了 Log 類別的支持。
你可以透過 Perfetto.dev 網頁、命令列工具手動觸發抓取與結束,透過設定中的開發者選項觸發長時間抓取,甚至你可以透過框架中提供的 Perfetto Trigger API 來動態開啟數據抓取,基本上涵蓋了我們在專案上能遇到的所有的情境。
在數據分析層面,Perfetto 提供了類似 Systrace 操作的數據視覺化分析網頁,但底層實作機制完全不同,最大的好處是可以支持超大檔的渲染,這是 Systrace 做不到的(超過 300M 以上時可能會崩潰、可能會超卡)。在這個視覺化網頁上,可以看到各種二次處理的數據、可以執行 SQL 查詢命令、甚至還可以看到 logcat 的內容。Perfetto Trace 檔可以轉換成基於 SQLite 的數據庫檔,既可以現場敲 SQL 也可以把已經寫好的 SQL 形成執行檔。甚至你可以把他匯入到 Jupyter 等數據科學工具棧,將你的分析思路分享給其他夥伴。
比如你想要計算 SurfaceFlinger 執行緒消耗 CPU 的總量,或者執行在大核中的執行緒都有哪一些等等,可以與領域專家合作,把他們的經驗轉成 SQL 指令。如果這個還不滿足你的需求, Perfetto 也提供了 Python API,將數據匯出成 DataFrame 格式近乎可以實作任意你想要的數據分析效果。
這一套下來供開發者可挖掘的點就非常多了,從筆者團隊的實踐來看,他幾乎可以覆蓋從功能開發、功能測試、CI/CD 以及線上監控、專家系統等方方面面。本星球的後續系列文章中,也會重點介紹 Perfetto 的強大功能與基於它開發的專家系統,可以幫助你「一鍵解答」效能瓶頸。
實踐中的套用情況
效能分析首要用到的工具就是 Perfetto,使用 Systrace 的場景是越來越少了。所以,你首要掌握的工具應該是 Perfetto,學習它的用法以及它提供的指標。
不過 Perfetto 也有一些邊界,首先它雖然提供了較高的靈活性但本質上還是靜態數據收集器,不是動態跟蹤工具,跟 eBPF 還是有本質上的差異。其次執行時成本比較高,因為涉及到在手機中實作 Ftrace 數據到 Perfetto 數據的轉換。最後他不提供文本分析方式,只能透過網頁視覺化或者操作 SQLite 來進行額外的分析了。綜合來看 Perfetto 是功能強大,幾乎涵蓋了可觀測性技術的方方面面,但是使用門檻也比較高。值得挖掘與學習的知識點比較多,我們後續的文章中也會重點安排此部份的內容。
2.3 Android Studio Profiler 工具
Android 的套用開發整合環境(官方推薦)是 Android Studio (之前是Eclipse,不過已經淘汰了) ,它自然而然也需要把開發和效能調優整合一起。非常幸運的是,隨著 Android Studio 的叠代、演進,到目前,Android Studio 有了自己的效能分析工具 Android Profiler,它是一個集合體,整合了多種效能分析工具於一體,讓開發者可以在 Android Studio 做開發套用,也不用再下載其它工具就能讓能做效能調優工作。
目前 Android Studio Profiler 已經整合了 4 類效能分析工具: CPU、Memory、Network、Battery,其中 CPU 相關效能分析工具為 CPU Profiler,也是本章的主角,它把 CPU 相關的效能分析工具都整合在了一起,開發者可以根據自己需求來選擇使用哪一個。可能很多人都知道,谷歌已經開發了一些獨立的 CPU 效能分析工具,如 Perfetto、Simpleperf、Java Method Trace 等,現在又出來一個 CPU Profiler,顯然不可能去重復造輪子,CPU Profiler 目前做法就是:從這些已知的工具中獲取數據,然後把數據解析成自己想要的樣式,透過統一的界面展示出來。
提供的亮點功能
CPU Profiler 整合了效能分析工具:Perfetto、Simpleperf、Java Method Trace,它自然而然具備了這些工具的全部或部份功能,如下:
- System Trace Recording,它是 用 Perfetto 抓取的資訊,可用於分析行程函數耗時、排程、渲染等情況,但是它一個精簡版,只能顯示行程強相關的資訊且會過濾掉耗時短的事件,建議將 Trace 匯出檔後在 https:// ui.perfetto.dev/ 上進行分析。
- Java Method Trace Recording,它是 從虛擬機器獲取函數呼叫棧資訊,用於分析 Java 函數呼叫和耗時情況。
- C/C++ Function Trace,它是用 Simpleperf 抓取的資訊,Simpleperf 是從 CPU 的效能監控單元 PMU 硬件元件獲取數據。 C/C++ Method Trace 只具備 Simpleperf 部份功能,用於分析 C/C++ 函數呼叫和耗時情況。
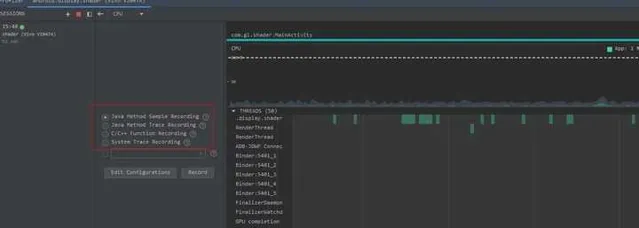
實踐中的套用情況
套用的效能問題主要分為兩類:響應慢、不流暢。
CPU Profiler 在這些場景中要如何使用呢?基本的思路是:首先就要抓 System Trace,先用System Trace 分析、定位問題,如果不能定位到問題,再借助 Java Method Trace 或 C/C++ Function Trace 進一步分析定位。
以一個效能極差的套用為例,在系統的關鍵位置插了 Systrace TracePoint,假設對程式碼不熟悉,那要怎麽找到效能瓶頸呢?我們先把套用跑起來, 透過 CPU Profiler 錄制一個 System Trace (後面文章會介紹工具的使用方法)如下:
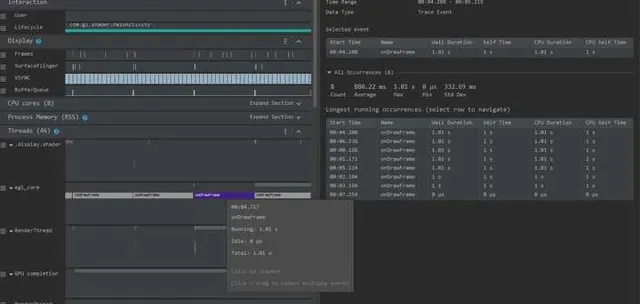
透過上面 Trace 可以知道是在 egl_core 執行緒中的 onDrawFrame 操作耗時,如果發現不了問題,建議匯出到 https:// ui.perfetto.dev/ 進一步分析,可以尋找原始碼看看 onDrawFrame 是什麽東西, 我們透過尋找發現 onDrawFrame 是 Java 函數 onDrawFrame 的耗時,要分析 Java 函數耗時情況, 我們要錄制一個 Java Method Trace ,如下:
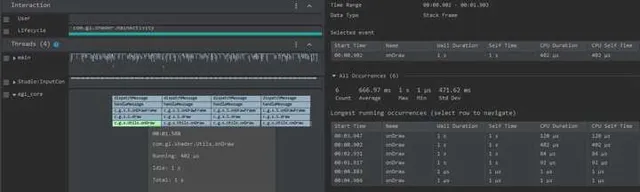
透過上面 Trace 很容易發現是一個叫做 Utils.onDraw 的 native 函數耗時,因為涉及到C/C++ 程式碼,所以要再錄制一個 C/C++ Function Trace 進一步分析,如下:

可以發現在 native 的 Java_com_gl_shader_Utils_onDraw 中程式碼執行了 sleep,它就是導致了效能低下的罪魁禍首!
AS 中的 CPU Profiler 最大優勢是整合了各種子工具,在一個地方就能操作一切,對套用開發者來說是非常方便的,不過對系統開發者來說可能沒那麽幸運。
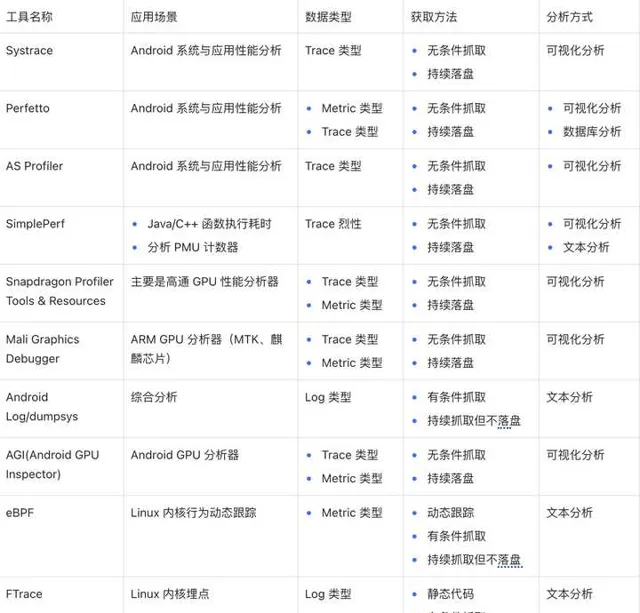
2.4 綜合對比
3 關於「器、術、道」
技術上的變革、改進更多是體現在「器」層面,Linux 社區以及谷歌所開發的工具發展方向朝著提高工具的整合化使得在一個地方可以方便查到所需的資訊、或者是朝著獲取更多資訊的方向發展。總之,器層面他們的發展軌跡是可尋的,可總結出發展規律。 我們需要在工具快速叠代的時候準確的認識到他們能力以及套用場景,其目的是提高解決問題的效率,而不是把時間花在學習新工具上。
「術」層面依賴具體的業務知識,知道一幀是如何被渲染的、CPU 是如何選擇行程排程的、IO 是如何被下發的等等。只有了解了業務知識才能正確的選擇工具並正確的解讀工具所提供的資訊。隨著經驗的豐富,有時候你都不需要看到工具提供的詳細資訊,也可以查到蛛絲馬跡,這就是當你業務知識豐富到一定程度,大腦裏形成了復雜的關聯性資訊之後淩駕於工具之上的一種能力。
「道」層面思考的是要解決什麽問題,問題的本質是什麽?做到什麽程度以及需要投入什麽樣的成本達成什麽樣的效果。為了解決一個問題,什麽樣的路徑的「投入產出比」是最高的?整體打法是什麽樣?為了完成一件事,你首先要做什麽其次是做什麽,前後依賴關系的邏輯又是什麽?
後續的文章中,會依照「器、術、道」方式講解一個技術、一個功能,我們不止想讓你學習到一個知識點,更想激發你舉一反三的能力。遇到類似的工具或者類似的問題、更進一步是完全不同的系統,都能夠從容應對。牢牢抓住本質,透過評估「投入產出比」選擇合適的工具或資訊,高效解決問題。
4 關於「The Performance 知識星球」
為了更好地交流與輸出高質素文章,我們建立了名為 「The Performance」的知識星球,主理人是三個國內一線手機廠商效能最佳化方面的一線開發者,有多年效能相關領域的工作經驗,提供Android 效能相關的一站式知識服務,涵蓋了基礎、方法論、工具使用和最寶貴的案例分析。
目前星球的內容規劃如下(兩個 ## 之間的是標簽,相關的話題都會打上對應的標簽,方便大家點選感興趣的標簽檢視對應的知識)
註意: iOS 手機使用者不要直接在星球裏面付款,在微信界面長按圖片掃描二維碼加入即可,否則蘋果會收取高昂的手續
5 附錄











