在語言學習中,一個常見的關鍵問題是如何對學習者表現評分,這種評分一般可分為客觀與主觀評價。客觀評價一般以客觀題的形式測試,比如填空、選擇等,學習者答案正確即為合格。主觀評價則通常以問話形式測試,由學習者做答,再由評判老師對學生的回答給出主觀評測,比如作文打分、口語評測等。
主觀評價常常耗時耗力,成本較高。另外,由於評測器材、心理狀態、個人偏好的差異,不易保持評價結果的一致性。為了解決這些問題,主觀評測已成為電腦輔助語言學習 Computer-Assisted Language Learning (CALL) 的重要課題之一。
我們將介紹微軟小英團隊利用序數回歸 Ordinal Regression (OR) 方法處理 CALL 中主觀評價問題的創新,以及其在發音、語音流暢度及英文寫作三種自然語音/語言的套用,以及相關方法的總結與展望。
序數回歸與主觀評測
在主觀評測的問題中,用不同的分數表示不同的等級,比如在5分制平均意見分 Mean Opinion Score (MOS) 中,常以1分到5分分別代表很差,差,一般,好,很好。傳統方法常用分類或回歸的方法解決,訓練多類別的分類器或回歸得到由輸入特征與分數間的對映。
然而,這類問題中樣本之間相對次序的資訊未能全盤解讀。因為不同的分數除其絕對分數外,其物理意義也代表了樣本在整個序列中的相對位置,比如一個3分的樣本,它所呈現的資訊代表著一個比4分的樣本差比2分樣本好的樣本,同時3分與2分的樣本的主觀差異與2分與1分之間的主觀差異,不盡相同。傳統的分類器只將每個分數視為一類,並不能完善地利用主觀評分中相對次序的特質。
不同分數樣本間的差異並非非等距,比如作文打分,1-3分的評價常針對拼寫和語法錯誤,而3-5分的差異著重在更高一級的寫作技巧,例如論述、展開與切題等等。對於等分間距的回歸,訓練中受到數據集大小與數據分布的影響,會有模型對於訓練數據過擬合的問題。
考慮到分數之間的相對次序,微軟亞洲研究院的研究員們提出利用序數回歸解決此類的問題。序數回歸是針對具有主觀上的自然排序的數據集進行建模與預測。類似的問題如預測年齡、甄別信用好壞、美感高低等,都有很大的套用潛力。
基於錨定參考樣本的序數回歸
收集數據時,研究員們發現對於標註者,給一個樣本1到5的分數相對於找出一對樣本的優劣更加困難,也更容易出現打分時因打分人與評測時間變化而產生的浮動與偏移。這是因為對於某些樣本,由於評分者的心理或生理變化,使評判標準發生了遷移,出現了浮動的主觀評分。一對樣本相比較更容易判斷孰好孰壞。盡管樣本對之間的比較更為一致和準確,但由於不同樣本對可能組合的待測數量呈階乘式上升,導致人力與金錢成本同比上升,因此幾乎不可能使打分人透過大量的對比確定待測樣本的水平。但對機器而言,決定一對樣本間的相對優劣可由一個二元分類器輕易完成,對於電腦的算力也不是很大的負擔。
透過這樣的觀察,研究員們提出了 基於錨定參考樣本的序數回歸 Ordinal Regression with Anchored Reference Sampless (ORARS) 。如圖1所示,該方法的基本邏輯是在不同的分數段分別選取若幹樣本作為錨點(Anchor),對於新的待測樣本,為了確定它的對應等級,所以將該待測樣本分別與不同分數子集內的參考錨定樣本相比較,從而得到待測樣本在整體序列中的位置,以及對應的分數。舉個例子,有一待測樣本在對比過程中,比在1分、2分段中的錨定樣本表現更佳,和3分段中的樣本不相上下,比4分、5分中的樣本稍顯不足,那麽很容易可以推斷出其最適當的分數為3分。這種方法不是直接去預測分數,而是將分數所代表的序數關系還原到原始的數列分布中,找出其對應的位置。對於機器來說,理解不同分數的絕對意義是相對更難的操作,尤其是細粒度分段,如100分制,而 ORARS 方法將此類的打分問題回歸到最為樸素的本質,也就是比較樣本對之間的相對優劣,並以對應位置的樣本作為預測的分數預測。
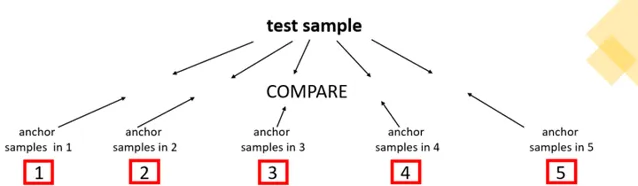
具體來講,ORARS 分為訓練與推斷階段。如圖2所示,在訓練階段,首先,從訓練集 D(具有專家評測後的樣本集合)中分出錨點集(Anchor set)A 與剩余訓練集(Training set)T,A 與 T 可有重疊部份,並利用 A 與 T 之間的笛卡爾積生成樣本對 (a, b),樣本對的對應標簽由樣本對之間的相對關系決定,分別代表樣本 a 優於樣本 b,或是樣本 a 不優於樣本 b。然後,利用構建的樣本對集合訓練一個用來判斷輸入樣本對間相對優劣的二分類器。在推斷階段,則先將待測樣本與選定的錨點集 A 同樣進行配對,然後利用在訓練階段獲得的二分類器進行推斷,最後利用待測樣本與錨點集中所有樣本的比對結果打分。
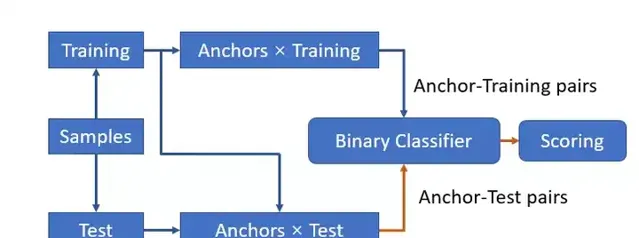
對於推斷過程中打分部份,研究員們提出了兩種不同的打分邏輯,分別適用於樣本分布比較均勻與樣本分布不均的情況。
方法一:對於數據分布較為均勻的樣本集,在選定錨點集 A 時,假設共有 N 個等級,對每個等級選取 M 個樣本作為錨點,一般建議選擇在人工打分中多個標註者意見較為統一的樣本作為錨點。記訓練的二分類器的推斷結果為 P(x_t, x_a),其物理意義為待測樣本是否比錨定參考樣本 x_a 的更優,則最終分數為 s= ∑_(i=1)^(N*M)(P(x_t,x_a)/M)。這種方法利用待測樣本與各分數段待測樣本之間的比較,透過加權平均的方式得到最終的預測分數。
方法二:對於數據分布不均勻或等級較多的樣本集(如百分制),選取均勻的錨點集是極具挑戰的,因此研究員們用訓練集中所有樣本作為參考錨點,將待測樣本與所有的樣本進行對比,利用所有的模型輸出求和得到待測樣本在錨點序列中的「排序」,並利用錨點集中對應排名的樣本分數作為預測分數。
基於錨定參考樣本的序數回歸有以下優勢 :第一,利用序數資訊將傳統的多分類器或回歸器簡化為樣本對之間的相對比較。一來,二元比較更為簡單,二來,透過原有數據樣本間的組合配對生成了多量的數據樣本,如此訓練二分類器,更多的數據、更簡單的優劣比對保證了模型的效能。第二,相較於傳統序數回歸方法,ORARS 引入了錨定參考樣本,透過樣本對之間的比較確定待測樣本水平,錨定參考樣本在對比的過程中,提供了參考資訊,構建了更加準確的序數空間與序數回歸的精細量化。
ORARS在電腦輔助語言學習中的套用
基於錨定參考樣本的序數回歸由於引入了序位資訊,並將原來的打分問題轉化為樣本對之間的比較,所以最佳化了效能。
研究員們在三個子問題中驗證了其有效性,分別為英文語音的流利度、語音的發音準確度,還有英文的寫作能力。一方面,三個子問題分別屬於語音訊號處理與自然語言處理領域,另一方面,三個問題的數據集樣本量分別為8000,2500,350。這些實驗可以驗證 ORARS 方法在不同問題和大小數據集的普適性與魯棒性。
語音流利度打分
利用8000句來自微軟小英的 ESL(English as Second Language)說話人語料,每句話由兩位語言學背景的專業編輯進行5分制評分,並以平均分作為標註。若兩位編輯打分分差大於2分,將引入第三位專業編輯進行仲裁。
之後,選取500句作為測試集,剩余部份用作訓練集,利用語速、停頓等六維流利度特征對比 ORARS 方法和基於 DNN 與 SVM 的分類器、SVR 回歸器,以及經典序數回歸方法序數二元分解[4]與多工序數回歸[5]。

透過在 Pearson Correlation Coefficient (PCC) 上,平均絕對誤差 Mean Absolute Error (MAE) 以及細粒度誤差比例(Fine Error,預測誤差小於0.5的比例)和粗粒度誤差比例(Coarse Error,預測誤差大於1.5的比例)的對比,可以看到基於序數回歸的方法可以提高模型的效能, ORARS 方法則可以達到最優效能,甚至在 MAE 與 Fine Error 上超過了專家評測 。
語音的發音準確度打分
利用2500句來自微軟小英的 ESL 說話人在跟讀場景下的語料,每句話請四位有語言/語音學背景的專業編輯以5分制評分,以最後的平均分作為標註。
傳統的發音打分一般是基於 GOP (Goodness of Pronunciation) 完成,先得到各個音素的發音得分,再采取平均的方式得到句子級別的總分。但這樣的方法具有以下問題:1)簡單的平均運算忽略了各音素間的差異,不能代表整句話的發音水平;2)忽略了打分問題中的相對排序資訊。因此該任務提出了句子級別的特征(average GOP vector + confusion GOP vector),並采用 ORARS 方法組建打分模型。
研究員們基於不同的聲學模型(Acoustic model, AM)執行了兩組實驗,分別記為 AM1 與 AM2,並利用五折交叉驗證(5-fold cross-validation) 的方法驗證了模型的效能。透過對比傳統方法 GOP 及其最新變種 Transition Awarepronunciation Score (TA Score), 以及基於神經網絡的回歸方法和 ORARS 方法之間的效能差異,並采用 Pearson Correlation Coefficient (PCC),Spearman Correlation Coefficient (SCC) 以及 MAE 進行對比,結果如表2所示:
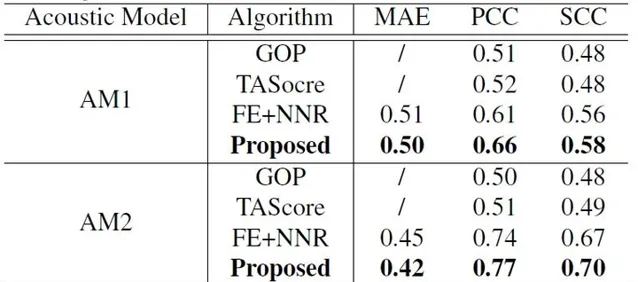
透過對比可以發現,研究員們提出的 ORARS 方法相較於傳統的 GOP 方法在 PCC,SCC 指標上分別相對提升了26.9%與20.8%, 並達到了與人類打分水平相當,或更好的水平 。
英文寫作打分
研究員們收集了350篇托福 (TOEFL) 獨立寫作,並讓專業標註團隊基於滿分30分制進行打分標註,每篇文章由兩人標註。微軟小英采用了基於詞、句、段等方面的特征進行模型建模,並利用十折交叉驗證的方式對比了不同模型的效能,具體如表3所示:
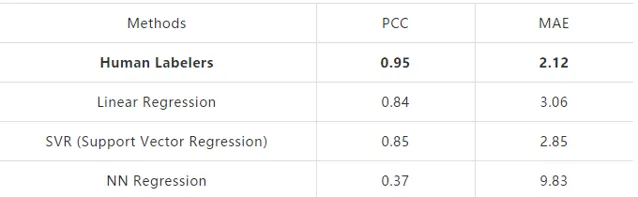
實驗結果顯示,ORARS 方法相較於其他方法效能更優。由於數據量很少,基於神經網絡 Neural Net (NN) 的回歸幾乎無法訓練,然而 ORARS 方法透過樣本對組合,增加了訓練核心二分類器的數據量,展現出了優異的效能。不過當數據量過少時,雖然 ORARS 比傳統機器學習方法效果更優,但機器學習的效能仍然不如專家評測。
總結與分析
ORARS 方法將傳統的主觀打分問題轉化為一系列樣本對之間的二元優劣比較,相比傳統的機器學習方法及序數回歸,ORARS 方法的打分功能得到了穩定的提升。基於 ORARS 的發音評分及寫作打分現已套用於微軟 Azure 語音發音打分服務(Speech Pronunciation Rating Service)及微軟愛寫作套用中。除了套用在語言學習的主觀打分方面,ORARS 方法還將可以套用到更多的排序問題上,如由人臉決定年齡、由音色辨識年齡、主觀美感評級等等。該方法充分利用了人類在處理同類問題中的認知理解,在未來的研究中,微軟小英團隊也將會從數學、理論和認知的角度,進一步闡述對於 ORARS 方法的理論分析與推廣更多套用。
ORARS 方法也已經套用到了微軟 Azure 語音服務 Speech-to-Text(語音轉文本)的語音評測功能中,微軟小英就是基於該功能進行構建的。微軟希望可以借此更好地賦能教育領域解決方案的合作夥伴、套用開發者以及語言學校、培訓中心、教育機構、考試中心的各種語言學習、口語練習和考試等場景的開發。
歡迎試用微軟小英以及微軟 Azure 語音評測功能,並提供寶貴的意見。
https://www. engkoo.com/
https:// docs.microsoft.com/zh-c n/azure/cognitive-services/speech-service/rest-speech-to-text#pronunciation-assessment-parameters
https:// github.com/Azure-Sample s/Cognitive-Speech-TTS/tree/master/PronunciationAssessment/CSharp/WPF
[1] Shaoguang Mao, Zhiyong Wu, Jingshuai Jiang, Peiyun Liu, Frank Soong, NN-based ordinal regression for assessing fluency of ESL speech. [in] Proc. ICASSP 2019, pp. 7420-7424, 2019.
[2] Bin Su, Shaoguang Mao, Frank Soong, Yan Xia, Jonathan Tien, Zhiyong Wu, Improving pronunciation assessment via ordinal regression with anchored reference samples. [in] arXiv preprint arXiv:2010.13339, 2020.
[3] Improve remote learning with speech-enabled apps powered by Azure Cognitive Services. Microsoft Tech Community Blog
https:// techcommunity.microsoft.com /t5/azure-ai/improve-remote-learning-with-speech-enabled-apps-powered-by/ba-p/1612807
[4] Ling Li, Hsuan-Tien Lin, Ordinal regression by extended binary classification. [in] Proc. Advances in neural information processing systems, pp. 865-872, 2007.
[5] Zhenxing Niu, Mo Zhou, Le Wang, Xinbo Gao, Gang Hua, Ordinal regression with multiple output cnn for age estimation. [in] Proc. CVPR, pp. 4920-4928, 2016.
本賬號為微軟亞洲研究院的官方知乎賬號。本賬號立足於電腦領域,特別是人工智能相關的前沿研究,旨在為人工智能的相關研究提供範例,從專業的角度促進公眾對人工智能的理解,並為研究人員提供討論和參與的開放平台,從而共建電腦領域的未來。
微軟亞洲研究院的每一位專家都是我們的智囊團,你在這個賬號可以閱讀到來自電腦科學領域各個不同方向的專家們的見解。請大家不要吝惜手裏的「邀請」,讓我們在分享中共同進步。
也歡迎大家關註我們的微博和微信 (ID:MSRAsia) 賬號,了解更多我們的研究











