蕭簫 發自 凹非寺 量子位 報道 | 公眾號 QbitAI
一場關鍵比賽,剛剛在全球頂級語音會議 INTERSPEECH 2021 上決出勝負。
騰訊、西工大、CMU等國內外機構是這場對決的主辦方,兩項比賽內容是語音行業的前沿研究,針對真實影片會議場景。
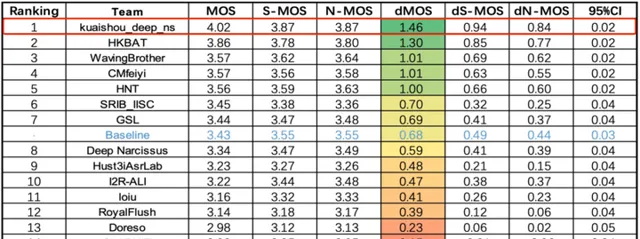
△ 單麥克風陣列多通道語音增強任務(dMOS越高越好)
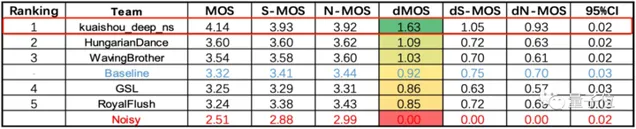
△ 多分布式麥克風陣列多通道語音增強任務(dMOS越高越好)
來自中國、美國、新加坡等16個國家和地區的實力隊伍參賽,其中有像浙大、北航這樣的頂尖高校,也有像中科院聲學所這樣的專業研究機構。
最終kuaishou_deep_ns團隊包攬榜首,這支團隊來自 快手 。
兩項任務的第二名,分別是來自浙江大學和海康威視研究院聯合團隊,以及中國科學院大學、中科院聲學所、北京航空航天大學、北京語言大學、西北工業大學聯合團隊。
快手團隊在這場比賽中所使用的技術,已經以2篇論文的形式被INTERSPEECH 2021收錄。
快手究竟在「遠場多通道語音增強技術」上做出了什麽突破?
經典分割模型U-Net,跨界語音增強領域
先來看看,這兩項任務的考查目標「 遠場多通道語音增強技術 」是什麽。
語音增強技術 ,指在含噪語音中,對雜訊訊號進行抑制、降低,盡可能提取純凈的原始語音訊號。
如果場景中只有一個麥克風(單鍊結),將難以解決在會議室、智能家居、智能座艙等場景下出現的遠場問題。
遠場 ,指說話人距離麥克風較遠的場景。主要存在三個難點:訊噪比低、房間混響(在封閉、室內場景下,聲波在傳播時不斷被墻壁反射、吸收和衰減)、多人說話場景
因此,通常采用 多通道 (多個麥克風組成的陣列)技術,來獲取更多不同方向訊號的振幅和相位資訊,進一步解決遠場問題,就是這場挑戰賽的目標。

△ 圓陣和線陣的采集方案
多通道包括單個、多個分布式麥克風陣列兩種類別,因此這場挑戰賽也由兩項任務組成,分別考查這兩種多通道類別的遠場語音增強技術。
傳統基於訊號的多通道演算法,往往雜訊抑制能力有限。這次的比賽中,快手團隊決定從一個 新角度 出發解決遠場問題:將深度學習技術和多通道演算法進行融合。
經過篩選後,團隊最終敲定了U-Net模型架構,這是一個 影像分割 領域的經典模型,在醫療影像和遙感領域的套用效果非常好。
U-Net 模型以其結構左右完全對稱、非常像「U」而得名,與FCN相似,同樣為encoder-decoder架構,最初被用於影像壓縮和影像去噪中。
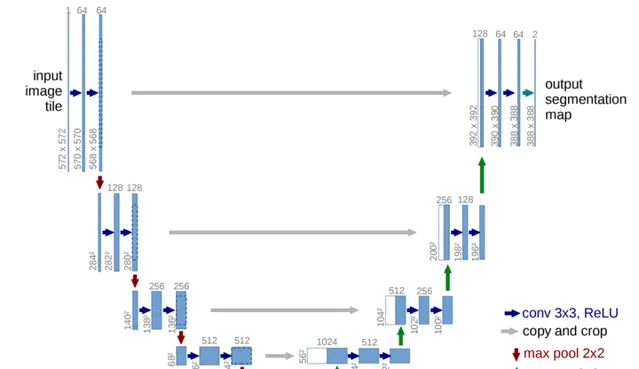
由於下采樣和上采樣均進行了4次,同時相比於FCN多了skip-connection(跳層連線)結構,因此U-Net能很好地提取高級語意資訊和低階特征。
但團隊卻將U-Net用在了語音增強領域中,基於因果U-Net提出了一種多輸入多輸出演算法模型。
因果U-Net 的摺積結構采用了因果摺積(causal convolutions),目的是考慮即時問題(語音數據處理需要考慮即時性)。事實上,將深度學習技術用於多通道模型,仍屬於前沿研究,相關論文非常少。這也成為了團隊設計模型時的一大難題。
經過反復測試驗證後,團隊發現,如果將模型的輸出和經典的波束形成相結合,就能獲得 1+1>2 的效果。
同時,在整體設計的基礎上,串聯一個 後處理濾波器 ,對基於深度學習模型生成的語音訊號進行二次降噪,讓語音音質更加清晰。
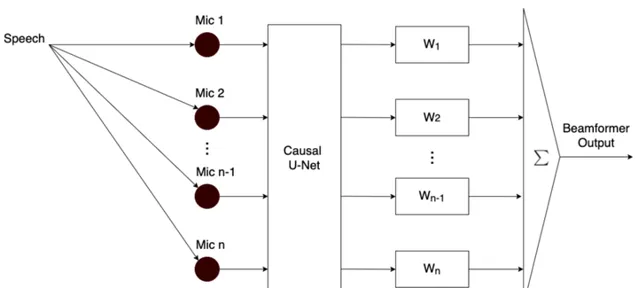
事實證明,這一「跨界」模型的效果確實不錯,原本廣泛用於影像分割領域的經典模型,現在在 語音增強 領域也能取得不錯的效果。
最終,快手團隊研發的多輸入多輸出模型支持8通道語音增強技術,同時具有可延伸性(能擴充套件不同的通道數量)。
不過,模型創新設計還只是比賽中的一環。
用數據還原真實場景,讓聽覺「無障礙」成為可能
事實上,在語音增強比賽中, 數據 合成又成為了另一挑戰。
舉辦方只會給出純凈的單人語音和雜訊數據,但在最終的場景考核中,所有語音訊號卻都來自真實場景。
也就是說,在最終比賽時,模型會遇到各種遠場情況、不同房間尺寸、不同麥克風放置地點和各種雜訊強度等不同類別的數據,但訓練數據卻完全要靠團隊自行設計。
這就需要參賽者合理考慮各類數據的占比,盡可能使模擬出來的數據更貼近真實情況。

不僅如此,由於此前深度學習在語音增強方向的研究大多基於單鍊結模型,因此團隊自行設計的數據,還得進一步考慮多通道的情況。
也就是說,需要對同一場景下、不同麥克風(通道)收到的訊號數據進行模擬,用於多通道模型的訓練。
盡可能還原真實場景的合成數據,加上自己研發的基於深度學習的多通道模型,讓快手團隊最終在這場語音增強比賽上獲得兩項任務的第一。
但這場語音增強比賽,背後的意義不僅在於角逐出模型的第一。
雖然「遠場多通道語音增強技術」確實尚處於前沿研究階段,但它未來的套用場景也已經得以預見。
其一, 多人會議 ,而且是異地兩部門之間的那種多人影片會議。

常見的線上影片會議中,基本上每個人都需要佩戴一副耳機,才能實作多人影片會議,這也是目前大多數影片會議APP所能實作的功能。
但未來可能只需要一塊螢幕,加上多通道語音技術就能在兩個異地部門、或是兩群人之間實作即時影片溝通。
即使坐在螢幕最遠端的人,也能聽見影片對面每個人的聲音,就像在一個辦公室溝通那樣順利。
其二,讓 XR技術 的實作,在語音處理領域成為可能。

5G+AI的組合,讓XR中的影像即時傳輸技術成為現實,但語音即時互動卻仍然存在不少困難,其中遠場是不可避開的一個技術難點。
如果遠場多通道語音增強技術進一步得到發展,或許將來XR也能真正實作語音上「聲臨其境」的互動效果。
想象一下,如果將來XR能套用到直播中(例如戶外直播),或許我們也能即時進入到直播環境中,足不出戶感受世界的美景。
作為音影片行業的引領者,快手已經在探索這樣的多通道語音增強技術落地場景。
將來,像多人會議、XR、直播場景互動這些設想中的「無障礙」聽覺技術,說不定哪天就會成為產品,落入尋常百姓家。
奪冠背後,快手的技術基因
在這次的語音增強比賽上獲得第一,背後是一整個快手的 音訊處理演算法團隊 在做技術支撐。

參賽團隊中,也有不少成員來自清北、西工大等985高校。
據團隊成員表示,實作這個模型,團隊用了將近一個月的時間,期間在模型設計和數據處理上遇到了不少難關,但最終團隊都將它們逐一攻破。
但相比於一味追求降噪效果,團隊成員的模型設計也考慮了 即時通訊 的需求。
畢竟遠場通訊的一大特點就是即時性,如果模型設計得太大,忽略了可實作性的話,也會失去落地套用的價值。
這也是快手「技術無差別」的基因之一,讓技術更貼近實際生活,盡可能造福每一圈層的人群。

事實上,除了語音增強技術以外,快手在 回聲消除 技術上也深耕已久。
同樣是在INTERSPEECH 2021的AEC Challenge(Acoustic Echo Cancellation Challenge)回聲消除比賽上,快手就以 4.77 的分數取得了雙講回聲消除的單項世界冠軍,領先於中科院、字節跳動、阿裏巴巴等諸多參賽團隊。
而在技術落地方面,同樣是在今年5月,快手還上線了基於深度學習的即時變聲直播,成為行業中首個上線相關技術的公司。
未來,快手還將繼續在音影片行業中,憑借技術實力,帶給我們更多的驚喜。
—完—
@量子位 · 追蹤AI技術和產品新動態
深有感觸的朋友,歡迎贊同、關註、分享三連վ'ᴗ' ի ❤











