這個問題非常不錯,由於side car 模式的興起,感覺本機網絡 IO 用的越來越多了,所以我特地把該問題挖出來答一答。
不過我想把這個問題再豐富豐富,討論起來更帶勁!
這裏先直接把結論投擲來。
內容來源於本人公-眾-號: 開發內功修煉, 歡迎關註!
另外我把我對網絡是如何收包的,如何使用 CPU,如何使用記憶體的對於記憶體的都深度分析了一下,還增加了一些效能最佳化建議和前沿技術展望等,最終匯聚出了這本【理解了實作再談網絡效能】。在此無私分享給大家。

下載連結傳送門: 【理解了實作再談網絡效能】
好了,繼續討論今天的問題!
一、跨機網路通訊過程
在開始講述本機通訊過程之前,我們還是先回顧一下跨機網絡通訊。
1.1 跨機數據發送
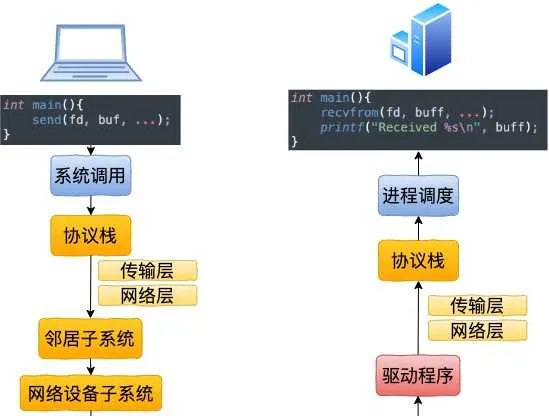
從 send 系統呼叫開始,直到網卡把數據發送出去,整體流程如下:
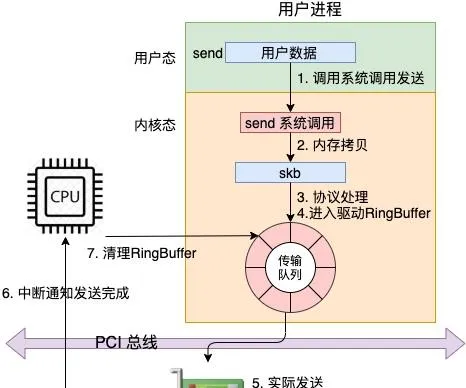
在這幅圖中,我們看到使用者數據被拷貝到內核態,然後經過協定棧處理後進入到了 RingBuffer 中。隨後網卡驅動真正將數據發送了出去。當發送完成的時候,是透過硬中斷來通知 CPU,然後清理 RingBuffer。
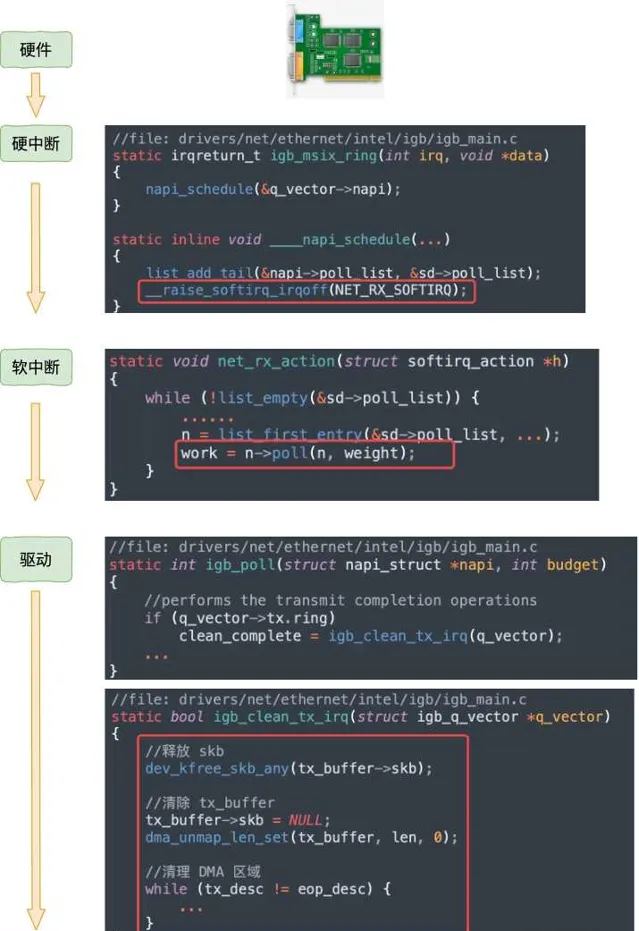
不過上面這幅圖並沒有很好地把內核元件和源碼展示出來,我們再從程式碼的視角看一遍。

等網絡發送完畢之後。網卡在發送完畢的時候,會給 CPU 發送一個硬中斷來通知 CPU。收到這個硬中斷後會釋放 RingBuffer 中使用的記憶體。
更詳細的分析過程參見:
1.2 跨機數據接收
當封包到達另外一台機器的時候,Linux 封包的接收過程開始了。
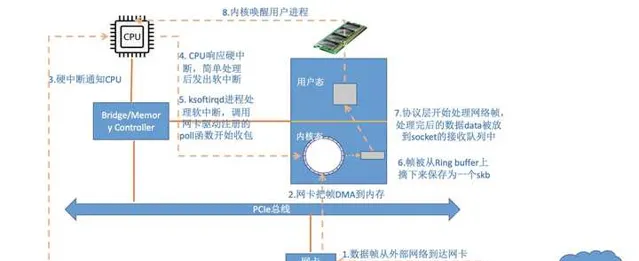
當網卡收到數據以後,向 CPU 發起一個中斷,以通知 CPU 有數據到達。當CPU收到中斷請求後,會去呼叫網絡驅動註冊的中斷處理常式,觸發軟中斷。ksoftirqd 檢測到有軟中斷請求到達,開始輪詢收包,收到後交由各級協定棧處理。當協定棧處理完並把數據放到接收佇列的之後,喚醒使用者行程(假設是阻塞方式)。
我們再同樣從內核元件和源碼視角看一遍。

詳細的接收過程參見這篇文章: 圖解Linux網絡包接收過程
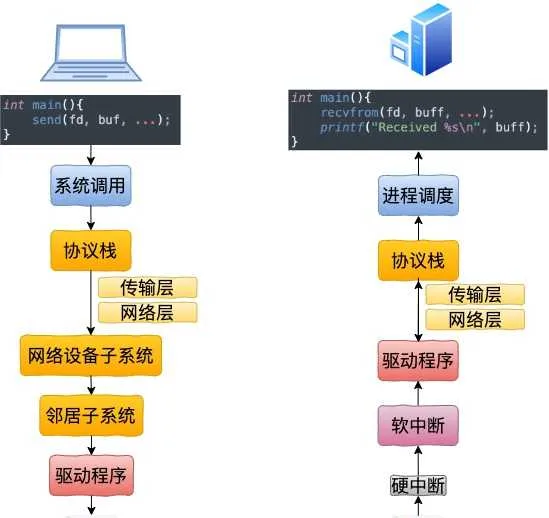
1.3 跨機網絡通訊匯總
二、本機發送過程
在第一節中,我們看到了跨機時整個網絡發送過程(嫌第一節流程圖不過癮,想繼續看源碼了解細節的同學可以參考 拆解 Linux 網絡包發送過程) 。
在本機網絡 IO 的過程中,流程會有一些差別。為了突出重點,將不再介紹整體流程,而是只介紹和跨機邏輯不同的地方。有差異的地方總共有兩個,分別是 路由 和 驅動程式 。
2.1 網絡層路由
發送數據會進入協定棧到網絡層的時候,網絡層入口函數是 ip_queue_xmit。在網絡層裏會進行路由選擇,路由選擇完畢後,再設定一些 IP 頭、進行一些 netfilter 的過濾後,將包交給鄰居子系統。
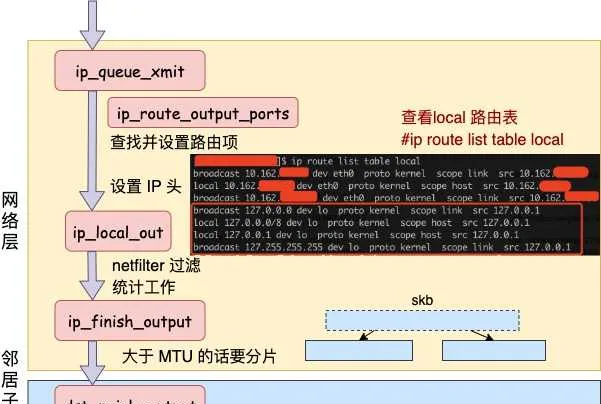
對於本機網絡 IO 來說,特殊之處在於在 local 路由表中就能找到路由項,對應的器材都將使用 loopback 網卡,也就是我們常見的 lo。
我們來詳細看看路由網絡層裏這段路由相關工作過程。從網絡層入口函數 ip_queue_xmit 看起。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
//檢查 socket 中是否有緩存的路由表
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
//沒有緩存則展開尋找
//則尋找路由項, 並緩存到 socket 中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
尋找路由項的函數是 ip_route_output_ports,它又依次呼叫到 ip_route_output_flow、__ip_route_output_key、fib_lookup。呼叫過程省略掉,直接看 fib_lookup 的關鍵程式碼。
//file:include/net/ip_fib.h
static inline int fib_lookup(struct net *net, const struct flowi4 *flp,
struct fib_result *res)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}
在 fib_lookup 將會對 local 和 main 兩個路由表展開查詢,並且是先查 local 後查詢 main。我們在 Linux 上使用命令名可以檢視到這兩個路由表, 這裏只看 local 路由表(因為本機網絡 IO 查詢到這個表就終止了)。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
從上述結果可以看出,對於目的是 127.0.0.1 的路由在 local 路由表中就能夠找到了。fib_lookup 工作完成,返回__ip_route_output_key 繼續。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if (fib_lookup(net, fl4, &res)) {
}
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
...
}
rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags);
return rth;
}
對於是本機的網絡請求,器材將全部都使用 net->loopback_dev,也就是 lo 虛擬網卡。
接下來的網絡層仍然和跨機網絡 IO 一樣,最終會經過 ip_finish_output,最終進入到 鄰居子系統的入口函數 dst_neigh_output 中。
本機網絡 IO 需要進行 IP 分片嗎?因為和正常的網絡層處理過程一樣會經過 ip_finish_output 函數。在這個函數中,如果 skb 大於 MTU 的話,仍然會進行分片。只不過 lo 的 MTU 比 Ethernet 要大很多。透過 ifconfig 命令就可以查到,普通網卡一般為 1500,而 lo 虛擬介面能有 65535。在鄰居子系統函數中經過處理,進入到網絡器材子系統(入口函數是 dev_queue_xmit)。
2.2 本機 IP 路由
開篇我們提到的第三個問題的答案就在前面的網絡層路由一小節中。但這個問題描述起來有點長,因此單獨拉一小節出來。
問題 :用本機 ip(例如192.168.x.x) 和用 127.0.0.1 效能上有差別嗎?
前面看到選用哪個器材是路由相關函數 __ip_route_output_key 中確定的。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if (fib_lookup(net, fl4, &res)) {
}
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
...
}
rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags);
return rth;
}
這裏會查詢到 local 路由表。
# ip route list table local
local 10.162.*.* dev eth0 proto kernel scope host src 10.162.*.*
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
很多人在看到這個路由表的時候就被它給迷惑了,以為上面 10.162 . 真的會被路由到 eth0(其中 10.162. . 是我的本機區域網路 IP,我把後面兩段用 * 號隱藏起來了)。
但其實內核在初始化 local 路由表的時候,把 local 路由表裏所有的路由項都設定成了 RTN_LOCAL,不僅僅只是 127.0.0.1。這個過程是在設定本機 ip 的時候,呼叫 fib_inetaddr_event 函數完成設定的。
static int fib_inetaddr_event(struct notifier_block *this,
unsigned long event, void *ptr)
{
switch (event) {
case NETDEV_UP:
fib_add_ifaddr(ifa);
break;
case NETDEV_DOWN:
fib_del_ifaddr(ifa, NULL);
//file:ipv4/fib_frontend.c
void fib_add_ifaddr(struct in_ifaddr *ifa)
{
fib_magic(RTM_NEWROUTE, RTN_LOCAL, addr, 32, prim);
}
所以即使本機 IP,不用 127.0.0.1,內核在路由項尋找的時候判斷類別是 RTN_LOCAL,仍然會使用 net->loopback_dev。也就是 lo 虛擬網卡。
為了穩妥起見,飛哥再抓包確認一下。開啟兩個控制台視窗,一個對 eth0 器材進行抓包。因為區域網路內會有大量的網絡請求,為了方便過濾,這裏使用一個特殊的埠號 8888。如果這個埠號在你的機器上占用了,那需要再換一個。
#tcpdump -i eth0 port 8888
另外一個視窗使用 telnet 對本機 IP 埠發出幾條網絡請求。
#telnet 10.162.*.* 8888
Trying 10.162.129.56...
telnet: connect to address 10.162.129.56: Connection refused
這時候切回第一個控制台,發現啥反應都沒有。說明包根本就沒有過 eth0 這個器材。
再把器材換成 lo 再抓。當 telnet 發出網絡請求以後,在 tcpdump 所在的視窗下看到了抓包結果。
# tcpdump -i lo port 8888
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 65535 bytes
08:22:31.956702 IP 10.162.*.*.62705 > 10.162.*.*.ddi-tcp-1: Flags [S], seq 678725385, win 43690, options [mss 65495,nop,wscale 8], length 0
08:22:31.956720 IP 10.162.*.*.ddi-tcp-1 > 10.162.*.*.62705: Flags [R.], seq 0, ack 678725386, win 0, length 0
2.3 網絡器材子系統
網絡器材子系統的入口函數是 dev_queue_xmit。簡單回憶下之前講述跨機發送過程的時候,對於真的有佇列的物理器材,在該函數中進行了一系列復雜的排隊等處理以後,才呼叫 dev_hard_start_xmit,從這個函數 再進入驅動程式來發送。在這個過程中,甚至還有可能會觸發軟中斷來進行發送,流程如圖:
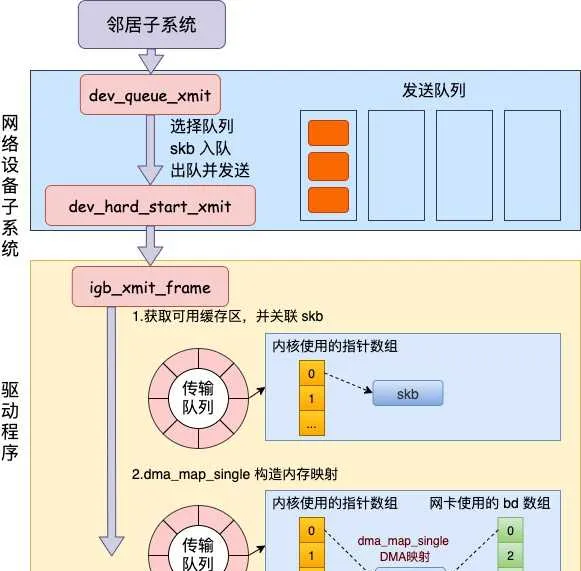
但是對於啟動狀態的回環器材來說(q->enqueue 判斷為 false),就簡單多了。沒有佇列的問題,直接進入 dev_hard_start_xmit。接著中進入回環器材的「驅動」裏的發送回呼函式 loopback_xmit,將 skb 「發送」出去。
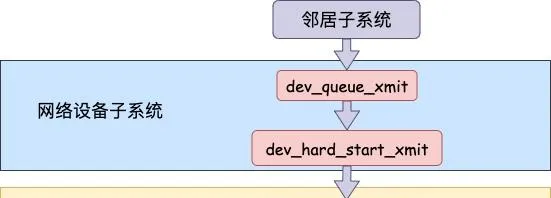
我們來看下詳細的過程,從 網絡器材子系統的入口 dev_queue_xmit 看起。
//file: net/core/dev.c
int dev_queue_xmit(struct sk_buff *skb)
{
q = rcu_dereference_bh(txq->qdisc);
if (q->enqueue) {//回環器材這裏為 false
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
//開始回環器材處理
if (dev->flags & IFF_UP) {
dev_hard_start_xmit(skb, dev, txq, ...);
...
}
}
在 dev_hard_start_xmit 中還是將呼叫器材驅動的操作函數。
//file: net/core/dev.c
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
//獲取器材驅動的回呼函式集合 ops
const struct net_device_ops *ops = dev->netdev_ops;
//呼叫驅動的 ndo_start_xmit 來進行發送
rc = ops->ndo_start_xmit(skb, dev);
...
}
2.3 「驅動」程式
對於真實的 igb 網卡來說,它的驅動程式碼都在 drivers/net/ethernet/intel/igb/igb_main.c 檔裏。順著這個路子,我找到了 loopback 器材的「驅動」程式碼位置:drivers/net/loopback.c。 在 drivers/net/loopback.c
//file:drivers/net/loopback.c
static const struct net_device_ops loopback_ops = {
.ndo_init = loopback_dev_init,
.ndo_start_xmit= loopback_xmit,
.ndo_get_stats64 = loopback_get_stats64,
};
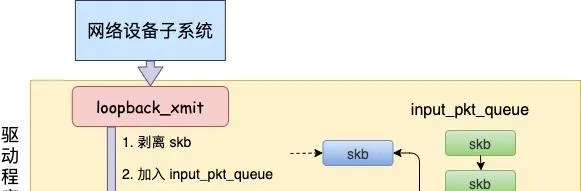
所以對 dev_hard_start_xmit 呼叫實際上執行的是 loopback 「驅動」 裏的 loopback_xmit。為什麽我把「驅動」加個引號呢,因為 loopback 是一個純軟件性質的虛擬介面,並沒有真正意義上的驅動。
//file:drivers/net/loopback.c
static netdev_tx_t loopback_xmit(struct sk_buff *skb,
struct net_device *dev)
{
//剝離掉和原 socket 的聯系
skb_orphan(skb);
//呼叫netif_rx
if (likely(netif_rx(skb) == NET_RX_SUCCESS)) {
}
}
在 skb_orphan 中先是把 skb 上的 socket 指標去掉了(剝離了出來)。
註意,在本機網絡 IO 發送的過程中,傳輸層下面的 skb 就不需要釋放了,直接給接收方傳過去就行了。總算是省了一點點開銷。不過可惜傳輸層的 skb 同樣節約不了,還是得頻繁地申請和釋放。接著呼叫 netif_rx,在該方法中 中最終會執行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。
//file: net/core/dev.c
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
sd = &per_cpu(softnet_data, cpu);
...
__skb_queue_tail(&sd->input_pkt_queue, skb);
...
____napi_schedule(sd, &sd->backlog);
在 enqueue_to_backlog 把要發送的 skb 插入 softnet_data->input_pkt_queue 佇列中並呼叫 ____napi_schedule 來觸發軟中斷。
//file:net/core/dev.c
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
只有觸發完軟中斷,發送過程就算是完成了。
三、本機接收過程
在跨機的網絡包的接收過程中,需要經過硬中斷,然後才能觸發軟中斷。而在本機的網絡 IO 過程中,由於並不真的過網卡,所以網卡實際傳輸,硬中斷就都省去了。直接從軟中斷開始,經過 process_backlog 後送進協定棧,大體過程如圖。

接下來我們再看更詳細一點的過程。
在軟中斷被觸發以後,會進入到 NET_RX_SOFTIRQ 對應的處理方法 net_rx_action 中(至於細節參見 圖解Linux網絡包接收過程 一文中的 3.2 小節)。
//file: net/core/dev.c
static void net_rx_action(struct softirq_action *h){
while (!list_empty(&sd->poll_list)) {
work = n->poll(n, weight);
}
}
我們還記得對於 igb 網卡來說,poll 實際呼叫的是 igb_poll 函數。那麽 loopback 網卡的 poll 函數是誰呢?由於poll_list 裏面是
struct softnet_data
物件,我們在 net_dev_init 中找到了蛛絲馬跡。
//file:net/core/dev.c
static int __init net_dev_init(void)
{
for_each_possible_cpu(i) {
sd->backlog.poll = process_backlog;
}
}
原來
struct softnet_data
預設的 poll 在初始化的時候設定成了 process_backlog 函數,來看看它都幹了啥。
static int process_backlog(struct napi_struct *napi, int quota)
{
while(){
while ((skb = __skb_dequeue(&sd->process_queue))) {
__netif_receive_skb(skb);
}
//skb_queue_splice_tail_init()函數用於將連結串列a連線到連結串列b上,
//形成一個新的連結串列b,並將原來a的頭變成空連結串列。
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen)
skb_queue_splice_tail_init(&sd->input_pkt_queue,
&sd->process_queue);
}
}
這次先看對 skb_queue_splice_tail_init 的呼叫。源碼就不看了,直接說它的作用是把 sd->input_pkt_queue 裏的 skb 鏈到 sd->process_queue 連結串列上去。
然後再看 __skb_dequeue, __skb_dequeue 是從 sd->process_queue 上取下來包來處理。這樣和前面發送過程的結尾處就對上了,發送過程是把包放到了 input_pkt_queue 佇列裏。

最後呼叫 __netif_receive_skb 將數據送往協定棧。在此之後的呼叫過程就和跨機網絡 IO 又一致了。
送往協定棧的呼叫鏈是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 後 將封包送入到 ip_rcv 中(詳情參見圖解Linux網絡包接收過程 一文中的 3.3 小節)。
網絡再往後依次是傳輸層,最後喚醒使用者行程。
四、本機網絡 IO 總結
我們來總結一下本機網絡 IO 的內核執行流程。
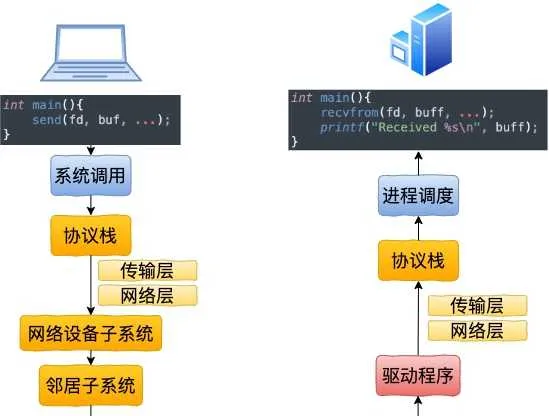
回想下跨機網絡 IO 的流程是
我們現在可以回顧下開篇的三個問題啦。
1)127.0.0.1 本機網絡 IO 需要經過網卡嗎? 透過本文的敘述,我們確定地得出結論, 不需要經過網卡 。即使了把網卡拔了本機網絡是否還可以正常使用的。
2)封包在內核中是個什麽走向,和外網發送相比流程上有啥差別? 總的來說,本機網絡 IO 和跨機 IO 比較起來,確實是節約了驅動上的一些開銷。發送數據不需要進 RingBuffer 的驅動佇列,直接把 skb 傳給接收協定棧(經過軟中斷)。但是在內核其它元件上,可是一點都沒少,系統呼叫、協定棧(傳輸層、網絡層等)、器材子系統整個走了一個遍。連「驅動」程式都走了(雖然對於回環器材來說只是一個純軟件的虛擬出來的東東)。所以即使是本機網絡 IO,切忌誤以為沒啥開銷就濫用。
3)用本機 ip(例如192.168.x.x) 和用 127.0.0.1 效能上有差別嗎?
很多人的直覺是走網卡,但正確結論是和 127.0.0.1 沒有差別,都是走虛擬的環回器材 lo。
這是因為內核在設定 ip 的時候,把所有的本機 ip 都初始化 local 路由表裏了,而且類別寫死 RTN_LOCAL。在後面的路由項選擇的時候發現類別是 RTN_LOCAL 就會選擇 lo 了。還不信的話你也動手抓包試試!
最後再提一下,業界有公司基於 ebpf 的 sockmap 和 sk redirect 功能研發了自己的 sockops 元件,用來加速 istio 架構中 sidecar 代理和本地行程之間的通訊。透過引入 BPF,才算是繞開了內核協定棧的開銷,原理如下。
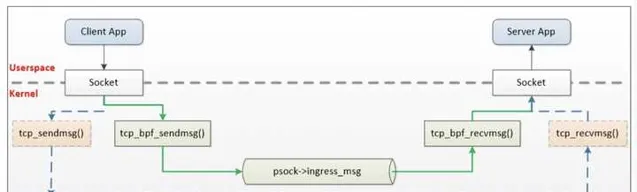
飛哥寫了一本電子書。這本電子書是對網絡效能進行拆解,把效能拆分為三個角度:CPU 開銷、記憶體開銷等。
具體到某個角度比如 CPU,那我需要給自己解釋清楚網絡包是怎麽從網卡到內核中的,內核又是透過哪些方式通知行程的。只有理解清楚了這些才能真正把握網絡對 CPU 的消耗。
對於記憶體角度也是一樣,只有理解了內核是如何使用記憶體,甚至需要哪些內核物件都搞清楚,也才能真正理解一條 TCP 連線的記憶體開銷。
除此之外我還增加了一些效能最佳化建議和前沿技術展望等,最終匯聚出了這本【理解了實作再談網絡效能】。在此無私分享給大家。
下載連結傳送門: 【理解了實作再談網絡效能】
另外飛哥經常會收到讀者的私信,詢問可否推薦一些書繼續深入學習內功。所以我幹脆就寫了篇文章。把能搜集到的電子版也幫大家匯總了一下,取需!
答讀者問,能否推薦幾本有價值的參考書(含下載地址)
Github: https://github.com/yanfeizhang/
------------------------------ 華麗的分割線 ----------------------------------------
2021-12-22 日追更
在上次回答完後,有讀者在評論區裏希望飛哥能再分析一下 Unix Domain Socket。最近終於抽空把這個也深入研究了一下。
今天我們將分析 Unix Domain Socket 的 連線建立過程、數據發送過程 等內部工作原理。你將理解為什麽這種方式的效能比 127.0.0.1 要好很多。最後我們還給出了實際的效能測試對比數據。
相信你已經迫不及待了,別著急,讓我們一一展開細說!
一、連線過程
總的來說,基於 UDS 的連線過程比 inet 的 socket 連線過程要簡單多了。客戶端先建立一個自己用的 socket,然後呼叫 connect 來和伺服器建立連線。
在 connect 的時候,會申請一個新 socket 給 server 端將來使用,和自己的 socket 建立好連線關系以後,就放到伺服器正在監聽的 socket 的接收佇列中。 這個時候,伺服器端透過 accept 就能獲取到和客戶端配好對的新 socket 了。
總的 UDS 的連線建立流程如下圖。
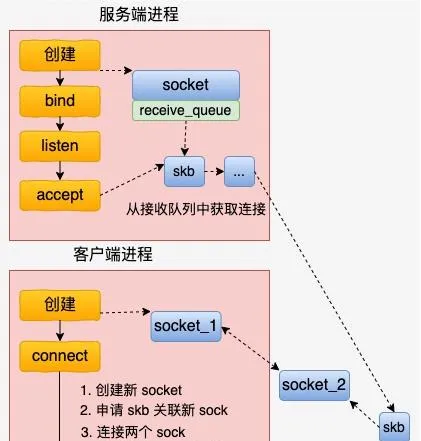
內核源碼中最重要的邏輯在 connect 函數中,我們來簡單展開看一下。 unix 協定族中定義了這類 socket 的所有方法,它位於 net/unix/af_unix.c 中。
//file: net/unix/af_unix.c
static
const
struct
proto_ops
unix_stream_ops
=
{
.
family
=
PF_UNIX
,
.
owner
=
THIS_MODULE
,
.
bind
=
unix_bind
,
.
connect
=
unix_stream_connect
,
.
socketpair
=
unix_socketpair
,
.
listen
=
unix_listen
,
...
};
我們找到 connect 函數的具體實作,unix_stream_connect。
//file: net/unix/af_unix.c
static
int
unix_stream_connect
(
struct
socket
*
sock
,
struct
sockaddr
*
uaddr
,
int
addr_len
,
int
flags
)
{
struct
sockaddr_un
*
sunaddr
=
(
struct
sockaddr_un
*
)
uaddr
;
...
// 1. 為伺服器側申請一個新的 socket 物件
newsk
=
unix_create1
(
sock_net
(
sk
),
NULL
);
// 2. 申請一個 skb,並關聯上 newsk
skb
=
sock_wmalloc
(
newsk
,
1
,
0
,
GFP_KERNEL
);
...
// 3. 建立兩個 sock 物件之間的連線
unix_peer
(
newsk
)
=
sk
;
newsk
->
sk_state
=
TCP_ESTABLISHED
;
newsk
->
sk_type
=
sk
->
sk_type
;
...
sk
->
sk_state
=
TCP_ESTABLISHED
;
unix_peer
(
sk
)
=
newsk
;
// 4. 把連線中的一頭(新 socket)放到伺服器接收佇列中
__skb_queue_tail
(
&
other
->
sk_receive_queue
,
skb
);
}
主要的連線操作都是在這個函數中完成的。和我們平常所見的 TCP 連線建立過程,這個連線過程簡直是太簡單了。沒有三次握手,也沒有全連線佇列、半連線佇列,更沒有啥超時重傳。
直接就是將兩個 socket 結構體中的指標互相指向對方就行了。就是 unix_peer(newsk) = sk 和 unix_peer(sk) = newsk 這兩句。
//file: net/unix/af_unix.c
#define unix_peer(sk) (unix_sk(sk)->peer)
當關聯關系建立好之後,透過 __skb_queue_tail 將 skb 放到伺服器的接收佇列中。註意這裏的 skb 裏保存著新 socket 的指標,因為服務行程透過 accept 取出這個 skb 的時候,就能獲取到和客戶行程中 socket 建立好連線關系的另一個 socket。
怎麽樣,UDS 的連線建立過程是不是很簡單!?
二、發送過程
看完了連線建立過程,我們再來看看基於 UDS 的數據的收發。這個收發過程一樣也是非常的簡單。發送方是直接將數據寫到接收方的接收佇列裏的。
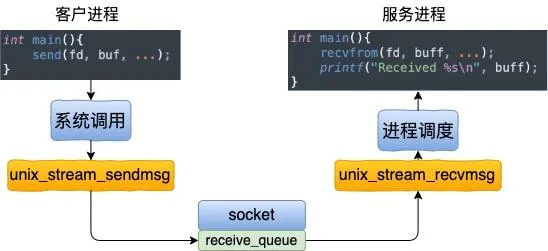
我們從 send 函數來看起。send 系統呼叫的源碼位於檔 net/socket.c 中。在這個系統呼叫裏,內部其實真正使用的是 sendto 系統呼叫。它只幹了兩件簡單的事情,
第一是在內核中把真正的 socket 找出來,在這個物件裏記錄著各種協定棧的函數地址。 第二是構造一個 struct msghdr 物件,把使用者傳入的數據,比如 buffer地址、數據長度啥的,統統都裝進去. 剩下的事情就交給下一層,協定棧裏的函數 inet_sendmsg 了,其中 inet_sendmsg 函數的地址是透過 socket 內核物件裏的 ops 成員找到的。大致流程如圖。
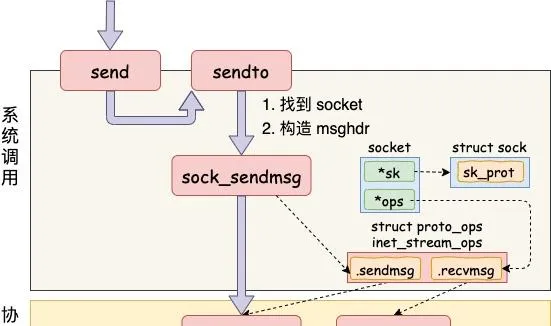
在進入到協定棧 inet_sendmsg 以後,內核接著會找到 socket 上的具體協定發送函數。對於 Unix Domain Socket 來說,那就是 unix_stream_sendmsg。 我們來看一下這個函數
//file:
static
int
unix_stream_sendmsg
(
struct
kiocb
*
kiocb
,
struct
socket
*
sock
,
struct
msghdr
*
msg
,
size_t
len
)
{
// 1.申請一塊緩存區
skb
=
sock_alloc_send_skb
(
sk
,
size
,
msg
->
msg_flags
&
MSG_DONTWAIT
,
&
err
);
// 2.拷貝使用者數據到內核緩存區
err
=
memcpy_fromiovec
(
skb_put
(
skb
,
size
),
msg
->
msg_iov
,
size
);
// 3. 尋找socket peer
struct
sock
*
other
=
NULL
;
other
=
unix_peer
(
sk
);
// 4.直接把 skb放到對端的接收佇列中
skb_queue_tail
(
&
other
->
sk_receive_queue
,
skb
);
// 5.發送完畢回呼
other
->
sk_data_ready
(
other
,
size
);
}
和復雜的 TCP 發送接收過程相比,這裏的發送邏輯簡單簡單到令人發指。申請一塊記憶體(skb),把數據拷貝進去。根據 socket 物件找到另一端, 直接把 skb 給放到對端的接收佇列裏了
接收函數主題是 unix_stream_recvmsg,這個函數中只需要存取它自己的接收佇列就行了,源碼就不展示了。所以在本機網絡 IO 場景裏,基於 Unix Domain Socket 的服務效能上肯定要好一些的。
三、效能對比
為了驗證 Unix Domain Socket 到底比基於 127.0.0.1 的效能好多少,我做了一個效能測試。 在網絡效能對比測試,最重要的兩個指標是延遲和吞吐。我從 Github 上找了個好用的測試源碼:https:// github.com/rigtorp/ipc- bench 。 我的測試環境是一台 4 核 CPU,8G 記憶體的 KVM 虛機。
在延遲指標上,對比結果如下圖。
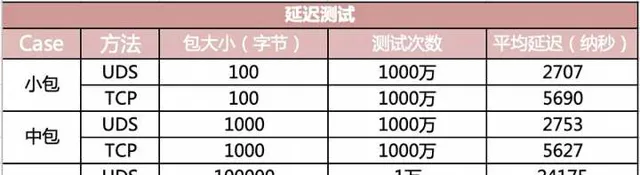
可見在小包(100 字節)的情況下,UDS 方法的「網絡」 IO 平均延遲只有 2707 納秒,而基於 TCP(存取 127.0.0.1)的方式下延遲高達 5690 納秒。耗時整整是前者的兩倍。
在包體達到 100 KB 以後,UDS 方法延遲 24 微秒左右(1 微秒等於 1000 納秒),TCP 是 32 微秒,仍然高一截。這裏低於 2 倍的關系了,是因為當包足夠大的時候,網絡協定棧上的開銷就顯得沒那麽明顯了。
再來看看吞吐效果對比。
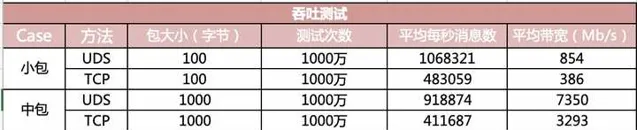
在小包的情況下,頻寬指標可以達到 854 M,而基於 TCP 的 IO 方式下只有 386。
四、總結
本文分析了基於 Unix Domain Socket 的連線建立、以及數據收發過程。其中數據收發的工作過程如下圖。
相對比本機網絡 IO 通訊過程上,它的工作過程要清爽許多。其中 127.0.0.1 工作過程如下圖。
我們也對比了 UDP 和 TCP 兩種方式下的延遲和效能指標。在包體不大於 1KB 的時候,UDS 的效能大約是 TCP 的兩倍多。 所以,在本機網絡 IO 的場景下,如果對效能敏感,可考慮使用 Unix Domain Socket。
看到這裏留個贊再走唄!
也歡迎關註飛哥的公眾號:開發內功修煉











