編輯:編輯部 HZj
【新智元導讀】Ilya「預訓練結束了」言論一出,圈內嘩然。谷歌大佬Logan Klipatrick和LeCun站出來反對說:預訓練還沒結束!Scaling Law真的崩了嗎?Epoch AI釋出報告稱,我們已經進入「小模型」周期,但下一代依然會更大。
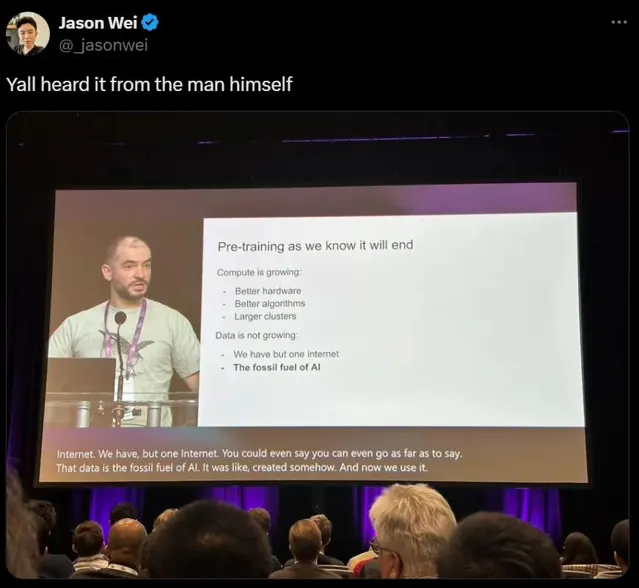
最近,Ilya在NeurIPS 2024中宣布:預訓練結束了!瞬間一石激起千層浪。
在他看來,數據如同化石燃料般難以再生,因此訓練模型需要的海量數據即將枯竭。
作為前OpenAI首席科學家,Ilya的這番話,有可能影響之後數十年的AI發展方向。
不過,預訓練真的結束了嗎?
最近,幾位圈內大佬,就公開站出來質疑和反對Ilya了。
谷歌大佬Logan Kilpatrick是這樣內涵Ilya的:認為預訓練結束,恐怕是因為你缺乏想象力。

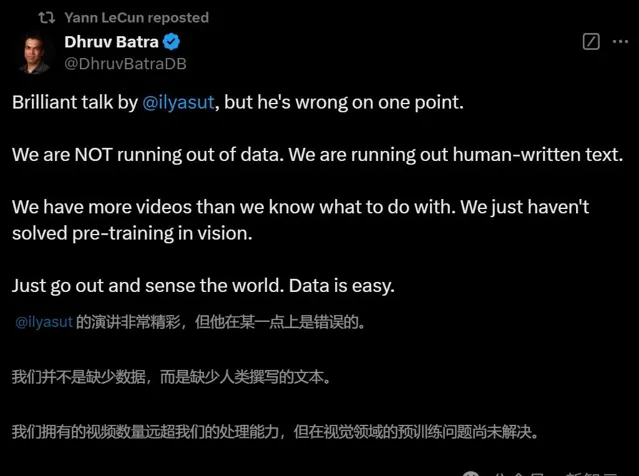
前Meta具身智能團隊的高級總監Dhruv Batra也站出來共同表示:Ilya錯了!
在他看來,人類的數據還沒有用完。
我們只是用完了人類書寫的文本而已,但我們擁有的影片數量,依然遠超我們的處理能力,目前只是尚未解決視覺領域的預訓練問題罷了。
的確,要知道,網絡上的文本公共數據,畢竟只是冰山一角而已。
我們除了文本,還能對音訊、影片、影像進行預訓練,甚至可以把視覺、嗅覺、觸覺、平衡和傳感器這些人類前進演化出來的功能賦予機器。
而如果模型真的可以學習的話,那數據或許確實是無所不在。


左右滑動檢視
有人則充分放分想象:如果預訓練能和化石相連,那它的確永遠不會結束。

Scaling Law和預訓練到底有沒有撞墻?
種種事件表明,我們已經站在了一個發展路線的分水嶺。
Ilya、LeCun甚至柯曼,都已經感覺到:目前的發展路線不能再延續下去了,我們亟需探索新的出路。
早期,Ilya曾是暴力Scaling的早期倡導者之一,認為透過增加數據和算力來「scale up」,能顯著改善模型效能。
但現在,Ilya已經承認自己曾經的想法錯了,並透露SSI正在研究一種全新的替代方法,來擴充套件預訓練。

相較之下,外媒SemiAnalysis則在一篇關於o1的深度報道中指出——scale的維度遠不止預訓練,Scaling Law仍將繼續下去。

最近,Epoch AI研究員的一篇長文,更是直觀地展示了這個「矛盾」的現象。

從2017年Transformer架構誕生到GPT-4釋出,SOTA模型的規模一直在變大,但增幅在變小。
從GPT-1到GPT-3,用了2年時間,模型參數量從1.17億增加到1750億,增加了1000倍
從GPT-3到GPT-4,用了2年9個月,模型參數量從1750億增加到1.8萬億,增加了10倍
而到了2023年,這一趨勢直接發生了逆轉。
據估計,當前SOTA模型的參數可能要比GPT-4的1.8萬億小一個數量級!
GPT-4o大約為2000億參數
Claude 3.5 Sonnet約為4000億參數
但有趣的是,下一代模型的規模,可能又會重新超過GPT-4。

當今SOTA模型最大只有約4000億參數
盡管許多實驗室沒有公開模型架構,Epoch AI的研究員依然從蛛絲馬跡中發現了線索。
首先是開源模型的證據。根據Artificial Analysis的模型質素指數,當前最佳的開源模型是Mistral Large 2和Llama 3.3,分別擁有1230億和700億參數。
這些稠密模型,架構與GPT-3相似,但參數更少。它們總體的基準表現超過了GPT-4和Claude 3 Opus,且由於參數更少,它們的推理成本和速度也更優。
對於閉源模型,盡管我們通常無法得知參數詳情,但可以根據推理速度和收費推測它們的大小。
僅考慮短上下文請求,OpenAI提供的2024年11月版本GPT-4o,每個使用者每秒100-150個輸出token,收費每百萬輸出token 10美元;而GPT-4 Turbo每秒最多大約55個輸出token,費用是每百萬輸出token 30美元。
顯然,GPT-4o比GPT-4 Turbo更便宜且更快,因此它的參數可能比GPT-4小得多。
另外,我們還可以使用推理經濟學的理論模型,來預測GPT-4在p00上進行推理的成本。
假設使用p00進行推理的機會成本為每小時3美元,下面的圖顯示了不同價格點下,GPT-4及其假設縮小版的生成速度。
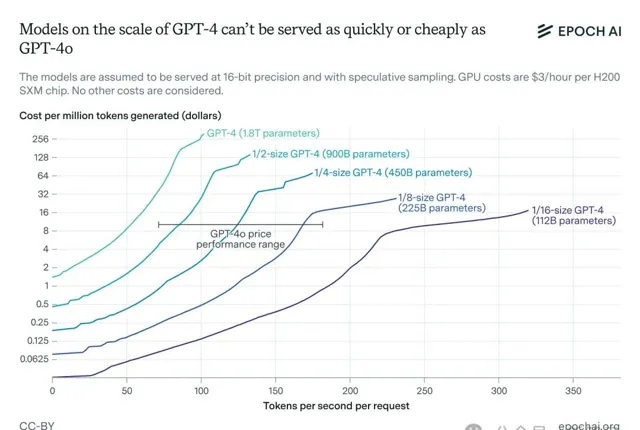
總體來說,為了讓模型每秒生成100個以上的token並且能夠流暢服務,模型需要比GPT-4小得多。
根據上圖,假設OpenAI的價格加成大約是GPU成本的八分之一,GPT-4o的參數量可能在2000億左右,雖然這個估計可能有2倍的誤差。
有證據表明,Anthropic的Claude 3.5 Sonnet可能比GPT-4o更大。Sonnet每秒生成約60個token,每百萬輸出token收費15美元。這速度在最佳化設定下接近原版GPT-4的收支平衡點。
不過,考慮到Anthropic API可能加價不少,Sonnet參數規模仍顯著小於GPT-4,估計在4000億左右。
總體來看,當前前沿模型的參數大多在4000億左右,像Llama 3.1 405B和Claude 3.5 Sonnet可能是最大的。
雖然對於閉源模型的參數估計有很大的不確定性,但我們仍然可以推測,從GPT-4和Claude 3 Opus到如今最強的模型,規模縮小的振幅可能接近一個數量級。
為什麽會這樣?
針對這一現象,Epoch AI認為有四個主要原因:
1. AI需求爆發,模型不得不瘦身
自ChatGPT和GPT-4釋出以來,AI產品需求激增,服務商面臨的推理請求大大超出預期。
此前,從2020年到2023年3月,模型訓練的目標是最小化訓練計算量,即在固定的能力水平下,花費盡可能少的計算資源完成訓練。Kaplan和Chinchilla的Scaling Law建議,隨著訓練計算量的增加,模型規模也應擴大。
隨著推理成本占據支出的大頭,傳統法則的適用性受到了挑戰。相比scaling模型規模,在更多訓練數據(token)上訓練較小的模型反而更劃算,因為較小的模型在推理階段的計算需求較低,能夠以更低的成本服務使用者。
比如,從Llama 2 70B到Llama 3 70B,雖然模型參數規模沒有顯著增加,但模型的效能卻顯著提升。
這是因為透過過度訓練(在更多數據上訓練較小的模型),可以讓模型在保持小規模的同時,表現得更強大。
2. 蒸餾,讓小模型更能打
實驗室還采用了「蒸餾」方法,從而讓更小的模型表現得更強大。
蒸餾指的是讓小模型模仿已經訓練好的大模型的效能。
蒸餾方法有很多種,其中一種簡單的方法是使用大模型生成高質素的合成數據集來訓練小模型,而更復雜的方法則需要存取大模型的內部資訊(如隱藏狀態和logprobs)。
Epoch AI認為,GPT-4o和Claude 3.5 Sonnet很可能是從更大的模型蒸餾得到的。
3. Scaling Law的轉變
Kaplan Scaling Law(2020)建議,模型的參數量與訓練用的token數量(即數據量)應保持較高的比例。簡單來說,當你增加訓練數據時,應該相應增加模型的規模(參數量)
而Chinchilla Scaling Law(2022)則偏向於更多訓練數據和更少的參數。模型不必越來越大,關鍵在於訓練數據的規模和多樣性。
這個轉變導致了訓練方式的改變:模型變得更小,但訓練數據更多。
從Kaplan到Chinchilla的轉變,並非因為推理需求的增加,而是我們對如何有效scaling預訓練的理解發生了變化。
4. 推理更快,模型更小
隨著推理方法的改進,模型生成token的效率和低延遲變得更加重要。
過去,判斷一個模型「足夠快」的標準是看它的生成速度是否接近人類的閱讀速度。
然而,當模型在生成每個輸出token時需要先推理出多個token時(比如每個輸出token對應10個推理token),提升生成效率就變得更關鍵。
這推動了實驗室,像OpenAI,專註於最佳化推理過程,使得模型在處理復雜推理任務時能夠更高效執行,也因此促使它們縮小模型的規模。
5. 用AI餵AI,成本更低
越來越多的實驗室開始采用合成數據作為訓練數據來源,這也是促使模型變小的原因之一。
合成數據為訓練計算scaling提供了一種新的途徑,超越了傳統的增加模型參數量和訓練數據集大小的方法(即,超越預訓練計算scaling)。
我們可以生成將來用於訓練的token,而不是從互聯網上抓取它們,就像AlphaGo透過自我對弈生成訓練數據一樣。
這樣,我們可以保持Chinchilla Scaling Law下計算最優的token與參數比例,但透過生成數據時為每個token投入更多計算,從而增加訓練計算量而不增加模型大小。
柯曼:參數規模競賽即將終結?
2023年4月,OpenAI釋出了當時最強的,同時也是第一款未公開參量的模型GPT-4。
之後不久,CEO柯曼曾預言了模型參數競賽的終結:圍繞模型參數量的競賽,就像歷史上對更高處理器主頻的追求,是一個死胡同。

那麽,前沿模型的規模會不會越變越小呢?
簡短的答案是——可能不會。但也很難說是否應該期待它們在短期內變得比GPT-4更大。
從Kaplan到Chinchilla的轉變是免洗的,因此我們沒有理由期待它繼續讓模型變小。
GPT-4釋出後的推理需求增長也可能快於未來推理支出的增長速度。且合成數據和scaling計算並非每個實驗室都在采納——即使有高質素的訓練數據,對於非常小的模型而言,能夠取得的成就可能非常有限。
此外,硬件的進步可能會促使更大的模型變得更優,因為在相同預算下,大模型通常表現更好。
較小的模型在推理時可能表現更差,尤其在長上下文和復雜任務上。
未來的模型(如GPT-5或Claude 4)可能會恢復或稍微超過GPT-4的規模,之後是否繼續縮小規模難以預料。
理論上,當前硬件足以支持比GPT-4大50倍、約100萬億參數的模型,可能以每百萬輸出token 3000美元、每秒10-20個token的速度提供服務。
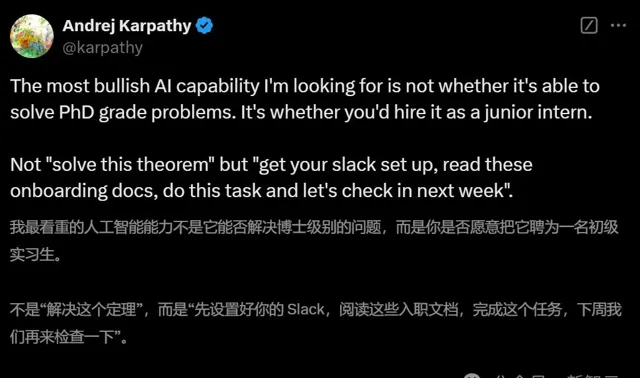
但正如Karpathy所說,相比於如今這種只能根據prompt去解決博士級別問題的AI,一個能夠真正作為「實習生」入職的AI更為實用。