1 什麽叫梯度下降
我們訓練模型的目標,就是找到一個擬合函數和一組參數,使得loss函數最小。如下

那麽這組參數怎麽找呢?大家肯定就想到了耳熟能詳的梯度下降。
假設θ 有兩個參數,即 {θ1, θ2}。初始時刻
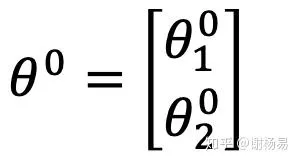
第一次叠代後,

第二次叠代後,

其中梯度即為

學習率為η。這種沿著梯度反方向更新參數的方式,即為梯度下降。叠代步驟如如下所示

2 為什麽要使用梯度下降
那為什麽采用梯度下降更新參數,就可以使得loss函數逐漸變小呢(不代表每次更新參數,Loss一定能減小)。我們可以采用一種方法來減小loss函數。先在loss函數中隨機找一個初始點,然後以它為中心畫一個圓圈,找到這個圓圈上loss最小的點。然後以這個點為中心繼續畫圓圈,找到loss最小的點。一直找下去即可找到令人滿意的一組參數。
這裏就要用到泰勒定理了。對於中心點x0周圍的x,泰勒展開如下
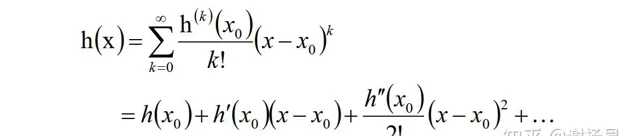
當x與x0很接近時,我們可以只保留一階導數,也就是

對於多個變量,也是類似的

我們令其中的常數如下:


上式可以覆寫為
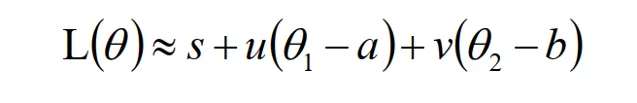
要使得L(θ)最小,即u(θ1 - a)+ v(θ2 - b) 即可。即為求兩向量(u, v)和(θ1 - a, θ2 - b)內積最小。顯然兩向量夾角180度時內積最小。如下圖所示
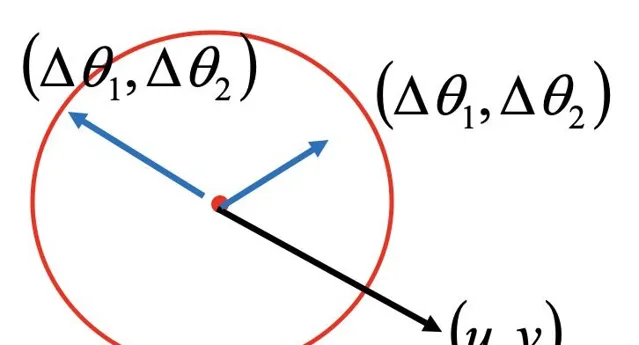
這就是為什麽我們要沿著梯度的反方向更新參數了,如下

3 如何最佳化梯度下降
3.1 隨機梯度下降 SGD
更新模型參數來叠代計算loss函數的時候,我們可以一次性計算所有的樣本數據,但會帶來一些問題
- 模型一次需要看所有的樣本,可能會有記憶體溢位問題
- 看完所有樣本才能更新一次模型,導致參數更新太慢,最終模型收斂比較慢
所以提出了隨機梯度下降。它每次隨機選取一部份樣本,稱為mini_batch,而不是全部所有樣本。利用這部份樣本來更新參數。然後再隨機選取另一批樣本,繼續更新模型參數。雖然每一步不一定和整體梯度方向一致,但所有樣本訓練完後,基本可以和整體梯度方向保持一致。
隨機梯度下降利用每次隨機只選取一批mini_batch的方法,很好的解決了記憶體溢位問題,並大大增加了參數更新頻率,加快了模型收斂速度。
3.2 特征歸一化
兩個參數θ1 、θ2的loss函數如下
如果兩個參數大小差別太大,則參數較小的那個的更新,不會對loss有太大作用,導致參數無法學習和更新。所以需要對參數進行歸一化,將二者拉到一個水平線上。
常用的方法為,每個特征減去其平均值,再除以變異數。如下

3.3 自適應學習率
梯度下降中的學習率很關鍵。學習率過大則容易越過最優點,過小則導致學習過慢。所以選取一個合適的學習率十分關鍵。如下圖所示

針對不同的叠代輪次,不同的參數,我們可以使用不同的學習率,因材施教。簡單來說就是,剛開始的時候loss比較大,可以使用大一點的學習率,加快模型收斂。當loss下降到比較小,接近最優點時,降低學習率,精調參數使得靠近最優點。
3.3.1 學習率隨叠代次數進行衰減
如下,其中t為叠代次數。

3.3.2 學習率隨梯度的累積進行衰減
如下

其中衰減值為之前的梯度的均方根

3.3.3 warmUp
剛開始訓練時模型參數比較坑,比如隨機初始化的參數。此時如果使用比較大的學習率,很容易導致模型不穩定,甚至直接跑飛,以後比較難拉回來了。故剛開始選擇一個較小的學習率,訓練一些iteration後,等模型較為穩定後,再逐步調整到預設的值。然後再從這個預設值開始逐步衰減和叠代。這個方法稱為warmUp。
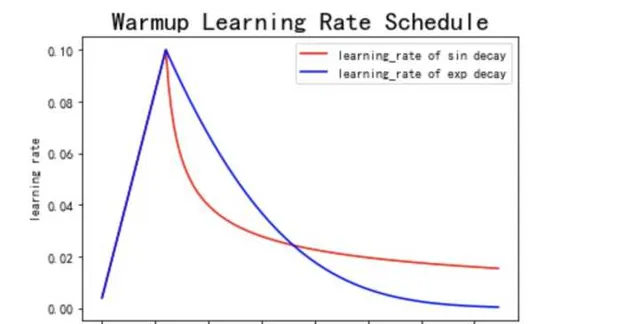
3.4 加入動量
梯度下降還有一個比較嚴重的問題,就是容易卡在梯度很小的地方。由梯度下降公式

可知,當梯度

很小,甚至接近0時,

,導致參數無法更新,或者更新很慢。這是一個很致命的問題。
常見的梯度很小的地方有
- 局部最小值,也就是經常說的局部最優解
- 鞍點
- 平坦的高原上。

那怎麽解決這個問題呢,我們可以使用動量,momentum。將前面叠代的梯度累積起來,使得保持朝某個方向下降的趨勢。在SGDM和ADAM最佳化器中均有套用,我們下節再講。
3.5 其他
其他方法也很多,主要有
- mini_batch shuffle,打亂每次叠代樣本
- 加入dropout,增加隨機性,從而增加模型學習的可能性
- 加入梯度雜訊,從而增加模型學習的可能性
- fine-tune,站在巨人肩膀上,比如NLP和CV的各種預訓練模型。
- curriculum learning。剛開始在簡單樣本上訓練,然後在比較難的樣本上訓練。
- 歸一化,比如batch-norm和layer-norm。使得樣本以及每一層參數都拉到同一個範圍內
- 正則化,盡量讓模型比較簡單,提升模型泛化能力
這兒就不一一贅述了。










