鄒經緯 馬輝/ 國泰君安證券股份有限公司
鐘浪輝 陳敏/ 上交所技術有限責任公司
行業現狀
證券交易系統中,行情一直是最重要的環節之一。一般情況下,交易所向會員單位提供行情閘道器程式,會員單位使用行情解碼程式,與交易所行情閘道器程式連線,然後解碼收到的行情數據,進行行情處理,最後分發給行情使用者。行情系統包含如下幾種類別:傳統的集中式行情系統,低延時的組播行情系統和基於FPGA的硬件行情系統等等。
傳統的集中式行情分發系統,如下圖所示。采用軟件實作的行情解碼程式,連線交易所行情閘道器MDGW(Market Data GateWay) ,建立TCP連線。行情解碼程式接收MDGW發送的原始行情數據,進行解碼,然後將解碼後的數據發送到集中的行情中心。行情中心負責行情數據的落地以及分發,將數據落地到歷史行情庫中,然後將即時數據分發給訂閱行情的客戶程式。整個鏈路都是采用軟件TCP傳輸。在這種集中式行情系統中,從交易所MDGW發送原始數據到客戶收到解碼行情,時延消耗為幾百微秒至幾毫秒。
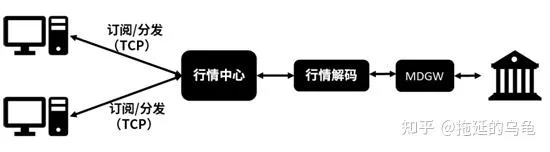
低延時的組播( UDP)行情系統,如下圖所示。采用軟件實作行情解碼,連線交易所 MDGW,建立 TCP連線。行情解碼程式將解碼後的行情采用組播( UDP)的方式,發送到行情組播私網中,在行情組播私網中的客戶將接收到組播行情。與集中式行情系統不同,這種低延時組播行情系統不適用於遠距離傳輸,一般在交易所托管機房內部署。這種行情組播系統多采用低延時網卡、搭配低延時交換機和高效能伺服器。行情傳輸時延能達到幾微秒到十幾微秒,接近於純網絡通訊的時延。
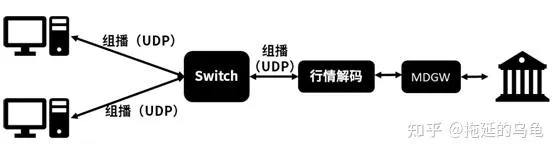
基於FPGA的硬件行情系統,如下圖所示。一般采用具備網絡通訊功能的FPGA板卡和x86伺服器構建的異構平台,進行行情解碼和行情分發。FPGA一般采用硬件描述語言開發。透過CPU負責行情解碼控制面,FPGA負責數據面。FPGA與MDGW建立TCP連線之後,接收原始行情數據,在FPGA卡內進行行情解碼和組播分發,不經過CPU處理。最後將行情數據發送到行情組播私網中,加入行情組播私網中的客戶將接收到硬件組播行情。由於網絡數據不經過CPU側DDR處理,因此行情傳輸時延可以到幾百納秒到1微秒。
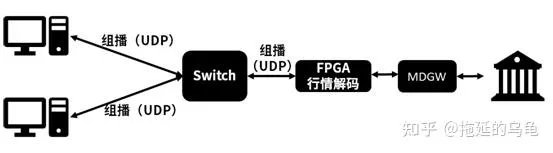
軟件開發人員單純依靠CPU、低延時網卡和低延時開發套件等,越來越接近時延瓶頸,再考慮到作業系統的排程和時延抖動,很難進入(幾)微秒甚至納秒級的競爭。FPGA(可編程邏輯陣列),作為可編程硬件,可以處理網絡數據,內部的大量邏輯資源可以重新「編程」,實作業務邏輯,而且時延抖動小。
異構加速平台
FPGA開發大多采用硬件描述語言,開發周期長、難度大,軟件開發者很難進入到這個領域。但是隨著FPGA加速套用的普及,Intel(英特爾)和Xilinx(賽靈思)也相繼推出了OpenCL(Open Computing Language)和HLS(high-level synthesis) 開發套件,支持采用類C語言進行FPGA開發。
本方案采用的是Intel的PAC(Programmable Acceleration Card)卡和x86 CPU構建的異構加速平台。PAC卡內建的是Arria 10GX FPGA,邏輯資源非常多。該異構平台支持使用OpenCL進行開發和執行。

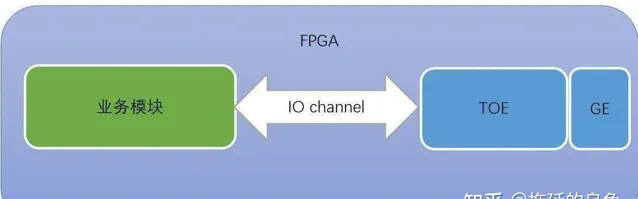
CPU主機側采用C++開發行情解碼控制面程式,FPGA器材側采用OpenCL C(基於C99)進行數據面開發。將TOE(TCP over Ethernet)IP(Intellectual Property)核嵌入到FPGA中,FPGA就具備了網絡通訊的功能,可以支持到傳輸層協定解析,然後將數據交給套用層處理。這裏,套用層就是采用OpenCL C開發的業務程式,即行情解碼。TOE與業務模組通訊,采用IO-channel的方式,數據位寬128bit,也就是16Bytes。
協定分析
深交所的行情,從MDGW發送給下遊的解碼程式,采用TCP連線,因此,在套用層采用分包協定。發送給下遊的字節流中,分包協定如下所示。每個套用層行情包,是一個完整的業務報文,可以解碼出一類行情資訊。一個套用層行情包分成三個部份:訊息頭,訊息體和訊息尾。訊息頭包含4字節訊息類別MsgType(如300111快照,300192逐筆委托等),4字節訊息體長度BodyLength。訊息體就是訊息類別對應的行情數據。訊息尾定義了訊息的校驗和,計算範圍從訊息頭開始一直到訊息體結束。每解完一個套用層行情包,後面緊跟的就是另一個行情包,根據訊息類別解析後續的訊息體。 行情中所有整數碼段均為大端字節序。
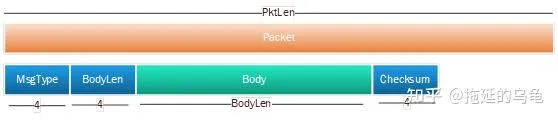
以300111行情快照為例,如果解析到MsgType為300111,則後續的訊息體使用300111對應的Binary協定進行解析。依次從訊息體中解析OrigTime(數據生成時間),ChannelNo(頻道程式碼),MDStreamID(行情類別),SecurityID(證券程式碼),對應的擴充套件欄位等等。

目前PAC卡中的TOE模組,輸出數據的位寬為128bit(16字節),為了充分利用FPGA的流水線處理特性,業務模組從IO-channel中每取到16字節進行一次處理,邊接收,邊解碼,而不是收到一個完成行情包再解析(這樣會引入較多的時延)。當然,也可以將16字節拆分成8字節或是1字節進行流水線處理。下圖為深交所行情快照按照16字節擺放,每一個時鐘周期數據對應的內容。

OpenCL行情解碼
異構平台程式分主機程式和器材程式。主機程式指執行於CPU上的軟件程式,器材程式指執行於FPGA內部的業務功能模組(OpenCL編寫的業務模組,非TOE)。主機和器材透過OpenCL執行框架通訊,進行任務分配。網絡功能則透過TOE對應的驅動程式,由主機側呼叫,透過TOE與交易所的MDGW建立連線。
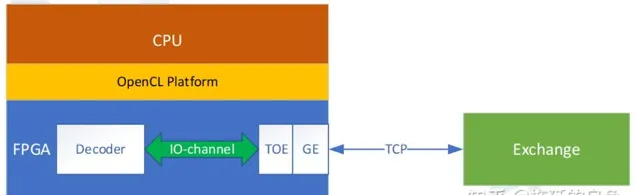
設計上分控制面和數據面。CPU相對靈活,編程容易,適用於邏輯控制。FPGA雖然可編程,但是功能固定,適合高速數據處理。因此CPU負責控制面,FPGA負責數據面。
控制面
- 管理上下遊鏈路。與上遊交易所MDGW建立TCP連線,向下遊組播私網發送組播行情。
- 管理FPGA上的任務執行。基於OpenCL Platform,下發Kernel任務給FPGA,包括FPGA初始化和釋放、MDGW登入、行情解碼等等。
- 監控行情解碼。監控上下遊連線狀態,監控行情解碼的收發包個數。
數據面
- 對接TOE。利用IO-channel與TOEInput/Output通訊,解析和封裝TCP/UDP報文。
- 行情解碼。進行TCP報文的處理、分包,Binary協定(行情快照、指數快照、逐筆委托、逐筆成交)解析。
軟件行情解碼,一般是收到一個完整的業務報文,再進行協定解析。由於CPU本身有快取cache,而且主頻比FPGA高一個數量級,解包效率非常高。但是,數據是從網卡到作業系統協定棧(若使用kernelbypass網卡,則進入使用者態協定棧),再搬移到DDR中,進行行情解析,存在多次數據搬移和拷貝。
FPGA行情解碼,整個行情解碼過程中,數據從交易所MDGW到FPGA板卡GE口,進入TOE,TOE將數據傳入Decoder業務模組,Decoder將解碼後的數據又透過TOE、GE口發送到對應的行情組播私網中。數據流只在FPGA板卡內部,不會進入FPGA板卡的片外DDR,更不需要透過PCIe搬移到CPU側DDR,因此省去很多數據搬移的開銷。
Kernel解碼邏輯設計時需要考慮到流水線的合理編排,充分利用FPGA硬件資源。TOE和業務Kernel之間的IO-channel通道位寬128bit(16Bytes),即TOE每個周期向IO-channel輸入和讀取16Bytes數據。為了獲得最低延時,業務模組需要同時進行數據接收、行情解碼和組播發送。快照解碼的偽碼如下。
在一個while迴圈體中,不停的從toe_in這個IO-channel中讀取數據,然後進行數據解析。如果這個時鐘周期的數據為套用層行情頭,即index等於0,則可以從中解析出msgtype、msglen和orig_time欄位;收下一時鐘周期的數據,可以解析出證券程式碼SecurityId;收到最後一個時鐘周期的數據時,解析完。封裝解碼後的行情數據,發送到中間的緩存channel(data_out)中。並列執行的發送Kernel就一直從data_out中取數據,取到數據就透過toe_out發送出去。

TOE協定的報文分析。TOE輸出的每個套用層報文會包上一個TOE頭,用於分包,並提供會話、長度資訊。緊接著的數據就是套用報文。TOE頭中長度欄位在0和1字節,長度的高字節在TOE頭的第0字節,長度的低字節在TOE頭的第1字節。會話ID(cid)在第二字節,TOE一般支持的會話在128以下。其余13字節都是0x55。TOE輸入的數據是大端擺放,如果用uchar16數據緩存TOE IO-channel輸入的數據,則uchar16的0~15字節對應的是TOE中的15~0字節,相當於數據翻轉了。重新翻轉之後的TOE數據如下:

效能調優
在使用OpenCL開發時,第一步是功能實作,第二部是效能調優。因為是使用OpenCL開發,gdb偵錯,所以功能開發所需要的時間相較傳統RTL開發少很多。效能調優占據整個開發流程中的一半時間。
II值和FMAX
效能調優時,除功能外,需要關註的指標主要有兩個:II值(Initiation Interval)和FMAX(maximum operating frequency)。
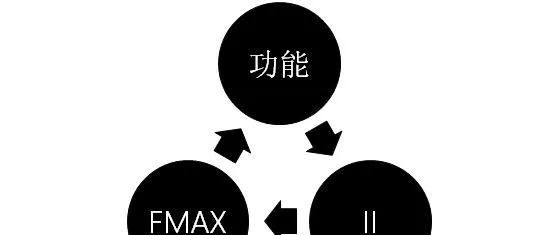
II值表示連續迴圈叠代之間的時鐘周期。FPGA是采用流水線執行任務,一條流水線的吞吐取決於最慢的一個環節,在最佳化時可以認為II值就是這個流水線中最慢環節所需的時鐘周期。如果流水線設計中,某個環節業務過於復雜,無法在一個時鐘周期內處理完,則流水線的II值會比較大。II值越大,表明吞吐越低;II值越低,則吞吐越大,時延也越低。一般在低延時套用中,II值目標是等於1,也就是在每個時鐘周期都能「吐出」一個任務結果。
FMAX值簡單理解就是FPGA執行的時脈。FMAX越高,則任務處理越快;FMAX越低,則任務處理越慢。業務模組過於復雜,FPGA在設計和編譯時,FMAX就「跑」不上去,導致上板後FPGA時脈較低,業務處理慢。
如果FMAX足夠低,即時鐘周期較長,足夠流水線中最慢的環節處理業務,II值總能為1;如果FMAX過高,即時鐘周期短,而流水線中最慢的環節無法在一個時鐘周期內處理完,則II值大於1,流水線無法在一個時鐘周期內輸出一個有效數據。如果II值足夠大,即流水線中可以容忍在多個時鐘周期內執行一次迴圈叠代(經過多個時鐘周期才能輸出一個處理結果),FMAX就可以很高;如果要求II值為1,則要求流水線每一個時鐘周期都輸出一個結果,那意味著FMAX需要降下來,保證流水線的迴圈叠代能在一個時鐘周期內處理完。
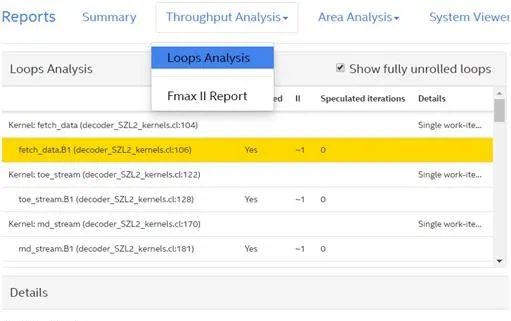
編譯器總會在II值和FMAX之間折中。OpenCL程式設計完後,可以在透過Quartus編譯生成的報告中檢視II值和FMAX。如下圖所示,reports中會給出所有模組的II值和FMAX,如果效能不高或者有最佳化空間,也會指出問題所在。
調優手段
詳細的調優手段可以參考Intel官方的【aocl-best-practices-guide】。以下列舉在行情解碼中用到的一些調優改進方法。
迴圈展開
使用while進行不定次數的迴圈,使用for全展開(unroll)進行固定次數的迴圈。一般低延時套用中,只允許一層不定次數迴圈,若有巢狀的不定次數迴圈,II值就不等於1。
例如使用for迴圈拷貝不定長度的數據。拷貝或者處理num個數據,num<=16,下述寫法II值不等於1,因為存在不定次數迴圈。

覆寫成如下寫法。就能將for迴圈全展開,且並列執行16個數據的處理。由於邏輯固定,可以在一個時鐘周期內完成。

同一變量的讀寫操作
首先要避免在一個迴圈體內復用同一個變量(邏輯資源充足,可以定義多個變量)影響編譯器最佳化邏輯依賴關系。
一個迴圈體內,建議對同一個變量進行多讀單寫,且寫在所有讀之前或之後,避免多讀多寫相互穿插。因為多讀單寫時,編譯器會復制多份變量,這樣依賴關系清晰,且多個讀程式碼會並列執行。而多讀多寫,可能會產生較為復雜的依賴關系,不利於編譯器最佳化。
降低IF判斷的復雜度
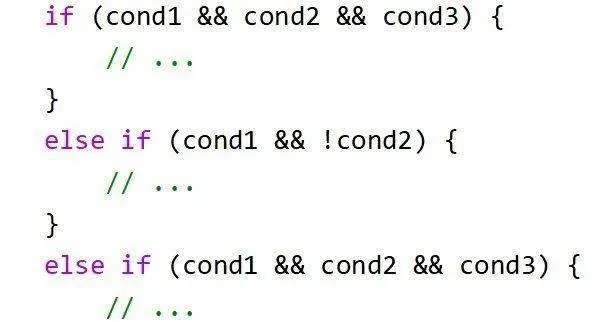
減少if巢狀,迴圈體內盡量只有1~3層if巢狀,過多的if巢狀不利於編譯器理解程式碼邏輯進行最佳化。

覆寫為下面的形式,if中的判斷條件會在一個時鐘周期內執行完。這樣的邏輯更為清晰,便於編譯器最佳化。
結論和展望
基於OpenCL開發的深交所Binary行情解碼,是證券領域利用OpenCL進行FPGA低延時套用開發的一次探索,配合高效能低延時的TOE,可以獲得接近硬件描述語言開發的效能。使用OpenCL開發FPGA具備很多好處:開發和叠代速度快,可以使用gdb在普通Linux環境進行功能偵錯;OpenCL編譯器也提供詳細效能分析報告,便於最佳化程式碼效能;還可以呼叫高效能的HDL或者其他語言開發的庫。目前已經完成了深交所Level1/Level2的Binary協定行情解碼,包括行情快照(快照和委托佇列)、指數快照、逐筆委托和逐筆成交。未來可以在板卡內進行一些指標計算,或者利用Intel的OpenCL FinLib,為客戶提供更豐富的行情資訊。











