我从工程师的角度来聊聊自动驾驶背后的性能优化。
使用深度学习技术来攻克自动驾驶是业界的共识。我们知道深度学习分为训练(training)和推理(inferencing)两部分,在自动驾驶中训练在服务器中完成,推理则在车子里进行。随着自动驾驶的模型越来越复杂,训练过程中的计算量和数据量都越来越多,单张 GPU 已经无法胜任,多 GPU、甚至多节点分布式训练,已经成为了行业标准。
在这个背景下,自动驾驶的 GPU 分布式训练,成为了端到端解决方案中非常重要的一环,而通信瓶颈是一个必须解决的性能关键点。
自动驾驶训练带来的挑战
训练一个自动驾驶方案依赖大量的真实数据。数据采集车配备多个传感器,主要包括摄像头、雷达和激光雷达。所采集的数据被用于构建辅助汽车驾驶以及驾驶员监控和协助的AI。数据采集车通常使用6-10个摄像头、4-6个雷达和2-4个激光雷达,它们都有不同的分辨率和距离范围。整个数据采集量由摄像头占主要,保守估算,一辆测试车每天产生的数据量可达 10 TB 。
更大规模的数据集与更短的训练时间的诉求, 仅依靠单张 GPU、甚至单台 GPU 服务器已经无法满足自动驾驶 AI 训练的要求,多机多卡 GPU 分布式训练成为必然选择。NVIDIA 使用 1400 张 V100 GPU 集群训练 BERT-Large,不到 1 个小时就可以完成训练。
AI 模型越庞大,模型参数越多,训练过程中的通信消耗也越大。一些大型 AI 模型的训练过程中,通信时间消耗占比已经超过 50%。在优化端到端的性能时,我们既需要考虑服务器内部的通信,也需要优化服务器外部的通信。
优化服务器内部的通信瓶颈
服务器内部的通信主要有
在高效的服务器架构中,CPU、GPU 和 IO 之间需要尽量做到两两直连。
我们先看下 NVIDIA 官方的 DGX Station A100 的外观图和硬件架构图,单路 AMD 罗马 CPU 加四块通过 NVLink 全互联的 A100 GPU,任何一块 GPU 都可以高速访问其他 GPU 的显存。CPU 和 GPU、CPU 和 IO 之间通过 x16 PCIe Gen4 进行直连,带宽是上一代 PCIe Gen3 的两倍。由于追求办公环境的全静音设计,性能方面有一定的妥协。

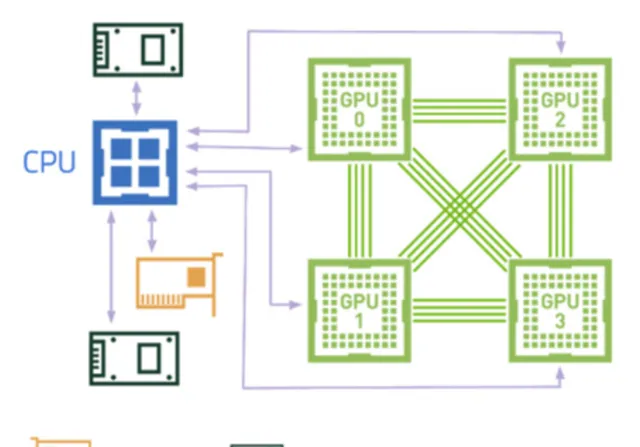
再看下合作伙伴的设计,下图是 Dell家的 PowerEdge R750xa 及 XE8545 服务器的外观图及硬件架构图。先看XE8545,NVlink全互联的四路A100,与DGX Station A100 设计类似,但 XE8545 要早半年推向市场。CPU升级为双路AMD米兰,更大的机箱,更多的内存和IO,全风冷散热。由于不用考虑办公环境的静音,在设计上毫无妥协,完全释放硬件性能。同为4*A100的R750xa采用了 不同的设计:NVLINK Bridge 。尽管只能实现GPU之间的两两相连,但俩GPU之间的带宽大大提升到了600GB/s(注:NVlink在4*GPU互联情况下,GPU两两之间的带宽只有200GB/s)。另x16 PCIe Gen4 的全面覆盖使得 CPU、GPU 和 IO 之间尽量直连,保障数据通信与 IO 传输性能。

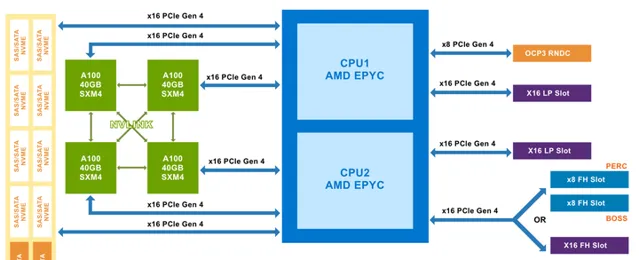
训练 AI 模型的过程中会反复读取同一组数据集, 以提升模型精度。如果暴力地进行反复读取,那么很卡就会用光通信带宽。在 PowerEdge XE845架构中,最高支持 8 块 NVME SSE 硬盘来缓存这部分数据,以实现高性能的本地存储。
优化服务器外部的通信瓶颈
为解决 GPU 分布式训练过程中的通信瓶颈,硬件层面开启 GPUDirect RDMA(简称 GDR),是非常有效的性能优化方案。通过 GPUDirect 技术调用 RDMA 通信库,一个服务器节点上的 GPU 可以直接将数据从其显存发送到目标服务器节点上的 GPU 显存,而不需要经过两个节点上的系统内存。AI 训练过程中的每一个数据字节,不需要绕路到系统内存进行严重拉低性能的内存拷贝,从而显著提升机算效率。
没有 GDR 时,CPU 必须将数据从 GPU 显存拷贝到系统内存,再通过 InfiniBand 传输给另一台服务器。开启 GDR 后,不同服务器中 GPU 间的通信不再经过 CPU 和系统内存,即只经过下图中绿色的线路。
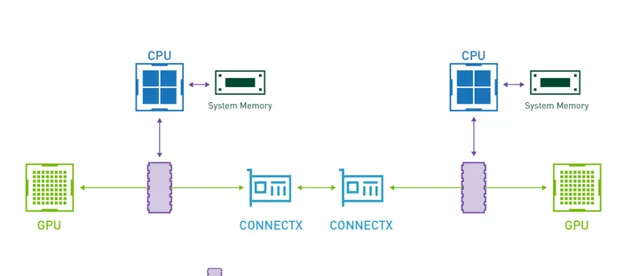
PowerEdge XE845服务器基于 Mellanox 200Gb HDR / 10Gb EDR Infiniband 交换机实现原生 RDMA,Dell Networking 自研的 100Gb / 25Gb 网络交换机部署 RoCE,提供低于 TCP / IP 协议的参数同步通信延迟。
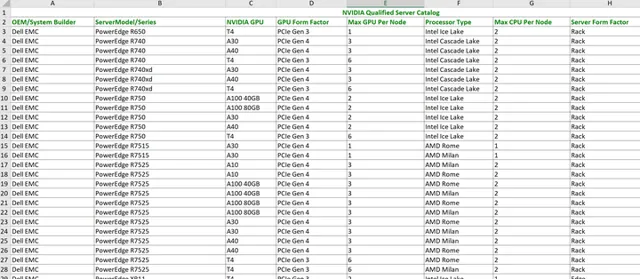
出于上述对性能、稳定性等重要因素的考虑,NVIDIA 会对合作伙伴的服务器设计进行企业级认证。目前能通过 NVIDIA 认证的企业级边缘服务器一共有51款,其中仅戴尔一家就占据了31款,高居榜首。
更多阅读资料











